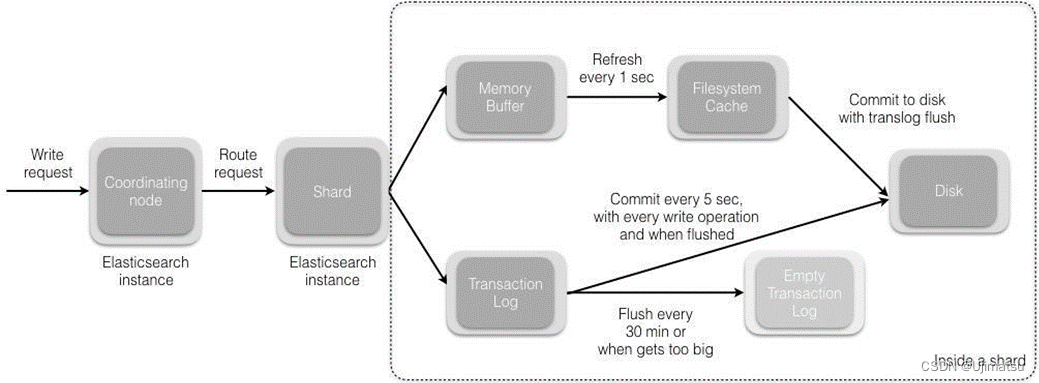
目录
4.2.1你对 Elasticsearch Query DSL 有多熟悉?请给出一个你认为高效的查询例子。
4.2.2使用 Elasticsearch DSL 编写一个可以处理模糊搜索和自动完成功能的查询。
5.2.1描述如何保证数据库和 Elasticsearch 索引间的数据同步
6.2.1在开发过程中,你会如何处理 Elasticsearch 的索引碎片化?
8.Elasticsearch API使用和最佳实践相关问题
9.2.1描述在应用程序中实现 Elasticsearch 安全性的策略
9.2.2你是如何在 Elasticsearch 中管理细粒度的访问控制?
11.2.1在开发过程中,你如何利用监控工具如 Elasticsearch 的 X-Pack 或其他插件来观察集群的健康状况?
11.2.2你如何设置和处理与 Elasticsearch 相关的警报?
当涉及到 Elasticsearch 开发者的面试时,问题通常会更专注于软件开发生命周期内与 Elasticsearch 集成的具体技术细节和实际应用场景。
1.Elasticsearch数据建模相关问题
1.1问题描述
描述如何设计 Elasticsearch 索引以支持高效的全文搜索和聚合操作。
在数据建模过程中,你如何决定使用嵌套类型还是平面结构?
1.2问题回答
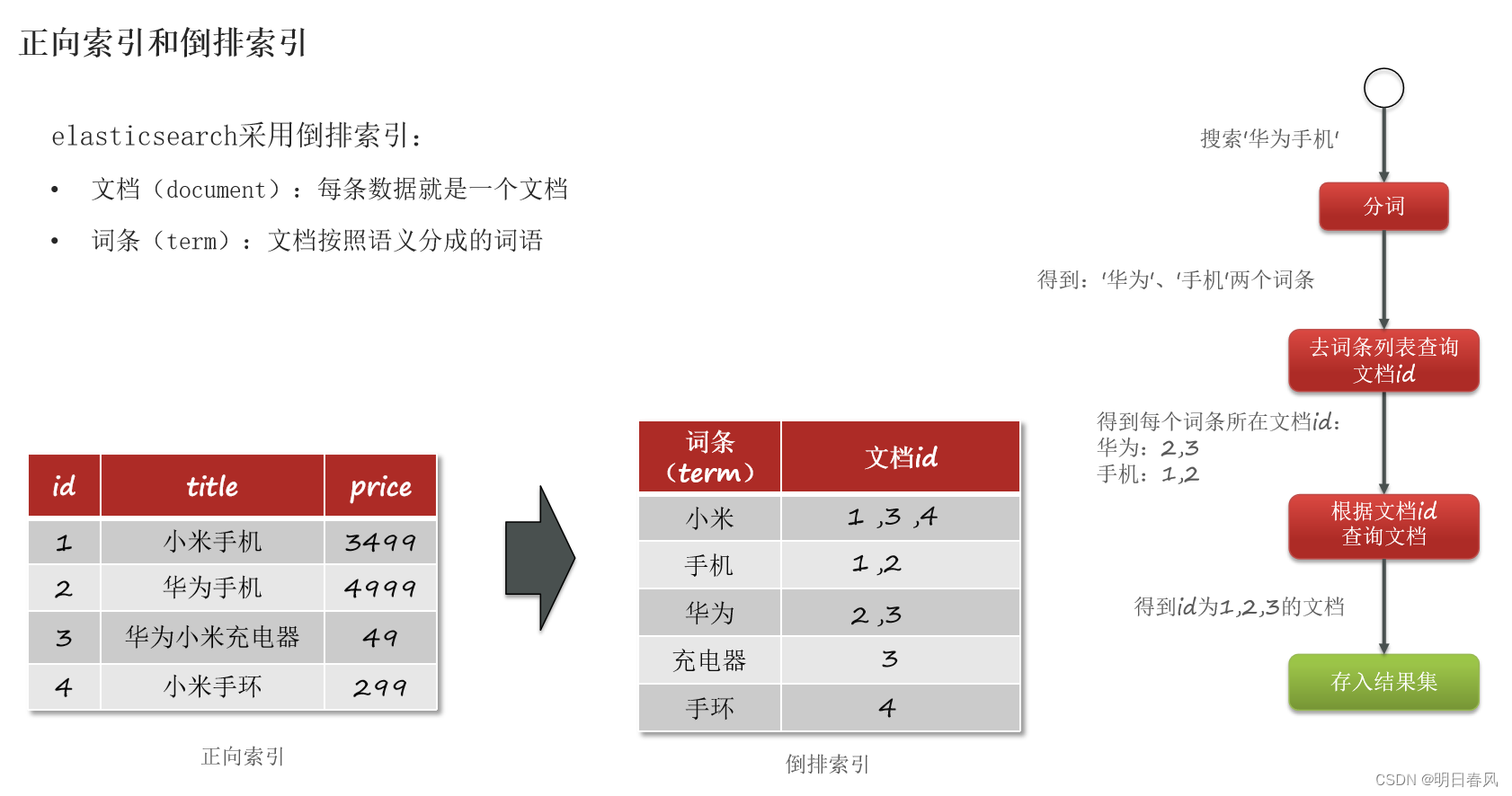
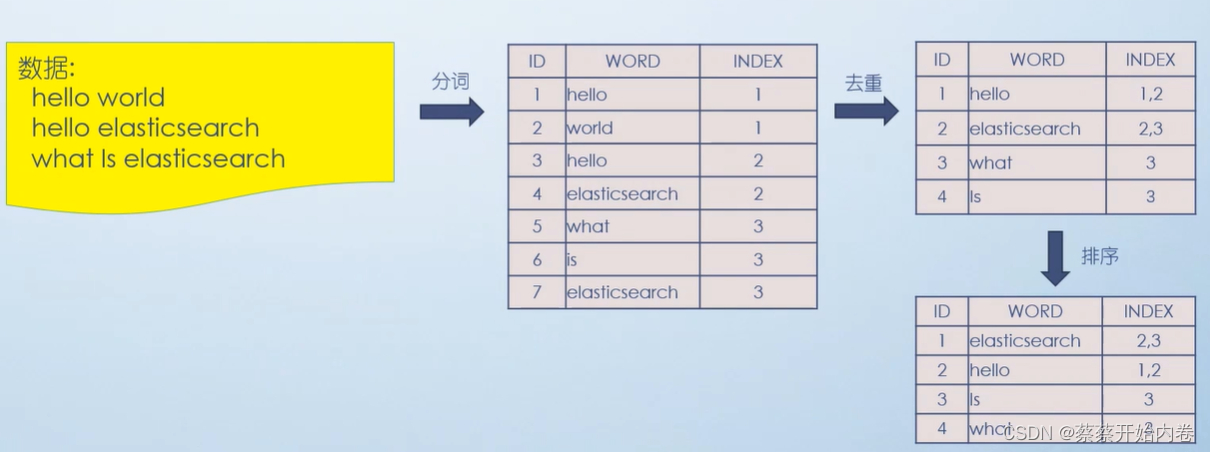
- 倒排索引以支 持全文检索;
- 正排索引以支持 聚合操作。
关于嵌套结构、平面结构——实践表明:
如果能平面宽表存储,咱们就宽表,空间换时间的方式是非常有效的数据建模方式;
除非特殊情况,当子文档更新不频繁的场景,推荐使用 Nested 类型;
子文档更新频繁的场景,推荐使用:Join 类型。
2.Elasticsearch 查询和分析相关问题
2.1问题描述
描述你如何优化复杂的 Elasticsearch 查询,以提高性能。
如果需要对大数据集进行实时分析,你会采取哪些策略?
2.2问题回答
硬件资源层面,要给到位。能 SSD 磁盘的,优先SSD磁盘。这样,写入、检索性能均比普通磁盘要好。能内存高配的尽量高配,推荐64GB,且堆内存设置32GB之内;如果更高配置,有待商榷和验证性能。CPU核数决定并发支持力度,这个和“线程池队列调优”有关系,也不能太低。尤其云服务器场景,受限于硬件资源的分配,别太低。云服务器也要考虑网络带宽,不能太低。否则,即便所谓各种检索技巧,也无处可施。比如:买个1核1GB的云服务器学生机,神仙也帮不了优化。
数据建模层面,做足文章。不推荐上来就直接优化DSL,因为某些情况,优化空间非常少。考虑字段层面是否最优化设置,字段类型是否设置合理;考虑有没有字段借助预处理 ingest pipeline 再继续拆分会不会更好;考虑所谓的多表关联,能不能不关联的宽表空间换时间实现。
复杂检索考虑优化点。耗费性能的检索,是否有替代方案。比如Wildcard能否通过 ngram 分词修改检索方式,能不用,尽量不用;如果使用 filter 过滤提升缓存性能的,是否使用;"profile:true"观察哪个环节出问题,有针对性的优化。
其他因素。检索时,是否有大量写入操作,查看是否还有优化空间;是否采取必要的段合并的策略,以优化检索;其他业务场景有针对性的调优。
3.Elasticsearch 集成与开发问题
3.1问题描述
如何在现有的 Web 应用程序中集成 Elasticsearch?
解释在微服务架构中如何利用 Elasticsearch 来提供搜索服务。
3.2问题回答
基本上说一下自己 Java 或者 Python层面集成 Elasticsearch 实践就可以。
比如:使用的 Java 官方客户端 Java-api(8.x),还是早期的 HighLevelREST API, 更早起的 LowLevelREST API 等。或者使用的 SpringBoot 相关的 API。
或者Python 框架下的 elasticsearch.py、elasticsearch-DSL等。
4.Elasticsearch DSL 相关应用选型等问题
4.1问题描述
你对 Elasticsearch Query DSL 有多熟悉?请给出一个你认为高效的查询例子。
使用 Elasticsearch DSL 编写一个可以处理模糊搜索和自动完成功能的查询。
4.2问题回答
4.2.1你对 Elasticsearch Query DSL 有多熟悉?请给出一个你认为高效的查询例子。
其实就说出 DSL 分类就可以:精确匹配查询(term、exists等)、全文检索(match、match_phrase 等)、Bool 组合检索(must、must_not、filter、should)等。
高效查询比如:基于 filter 的过滤缓存检索,性能比普通没有 filter 好很多,因为有效使用了缓存。
4.2.2使用 Elasticsearch DSL 编写一个可以处理模糊搜索和自动完成功能的查询。
模糊查询的含义,比如:match_phrase 和 slop 结合可以实现,比如:wildcard 可以实现,但有性能问题,比如:regex 正则检索可以实现,也有性能问题。
自动完成功能,需要沟通是不是自动补全功能,这点 ES 支持 auto complete 类似的 API——completion-suggester。
补充
[1] https://www.elastic.co/guide/en/elasticsearch/reference/8.12/search-suggesters.html#completion-suggester
[2]https://docs.elastic.co/search-ui/solutions/ecommerce/autocomplete
[3]https://taranjeet.medium.com/elasticsearch-building-autocomplete-functionality-494fcf81a7cf
[4]https://opster.com/guides/elasticsearch/how-tos/elasticsearch-auto-complete-guide/
[5]https://taranjeet.medium.com/elasticsearch-using-completion-suggester-to-build-autocomplete-e9c120cf6d87
5.Elasticsearch 索引数据同步相关问题
5.1问题描述
描述如何保证数据库和 Elasticsearch 索引间的数据同步。
你是如何处理批量索引和更新大量文档的?
5.2问题回答
5.2.1描述如何保证数据库和 Elasticsearch 索引间的数据同步
保证同步——我用 Logstash 多,主要基于时间戳和自增id实现同步。
这两种机制单纯自己实现方式都能有效保障同步。
如果出现同步异常,也可以通过两侧(源头、目的端)通过ID比对的方式进行排查和核实。
5.2.2你是如何处理批量索引和更新大量文档的?
批量索引——就是基于 bulk API 批量导入或者写入数据。
这里要注意的点就是:bulk 值不适宜上来调整的非常大,比如:上来就10万、100万等。
而是根据线程池和队列:逐步调大进行性能测试,不如:5000、10000、20000这种,直到找到性能接近瓶颈且合适的值即可。
更新大量文档——非必要不使用更新操作。
6.Elasticsearch 性能调优和索引维护相关问题
6.1问题描述
在开发过程中,你会如何处理 Elasticsearch 的索引碎片化?
有没有经验进行索引的映射迁移或重建?
6.2问题回答
6.2.1在开发过程中,你会如何处理 Elasticsearch 的索引碎片化?
索引碎片化不是专有词汇,ES 官方文档并没有这种称呼。需要核实多大是碎片。
这里,咱们推荐两个维度考虑这个问题。
- 维度1:架构层面,单分片的最大值尽量控制在 30 GB- 50GB,过大了不便于维护,过小了性能会有影响。
- 维度2:不定期在非业务密集区域实现段合并,以保证性能优化。
6.2.2有没有经验进行索引的映射迁移或重建?
看数据量大小
- 如果数据量不大,直接 reindex 数据迁移;
- 如果数据量适中,使用 reindex + slice 的方式迁移;
- 如果数据过大,推荐 elasticdump(适合跨集群同步),索引快照和恢复的方式保障数据迁移的高可用性。
- 如果跨集群,其实也可以使用:reindex, 但是要配置白名单。
- 如果版本兼容,快照和恢复机制也是推荐的
7.Elasticsearch 错误处理和日志相关问题
7.1问题描述
如何处理 Elasticsearch 相关的异常和错误?
在你的开发工作中,你是如何进行日志记录和监控 Elasticsearch 行为的?
7.2问题回答
第一,不定期查看日志或者出了问题第一时间查看日志,普通日志会记录集群故障。比如:wildcard 出错,出问题日志能看到。
第二,必要时候,开启慢日志查询。比如:想知道哪个IP地址近期操作频繁,想知道近期哪个聚合比较拉胯。
第三,日志可视化,ELKB实现,日志通过logstash 同步到 Elasticsearch,并借助 Kibana 进行数据的可视化。
以上维度,保障集群问题及时发现也便于我们提前发现问题并解决问题。
8.Elasticsearch API使用和最佳实践相关问题
8.1问题描述
描述你使用Elasticsearch REST API时的一些最佳实践。
如何使用 Elasticsearch 的聚合 API来提取关键业务指标?
8.2问题回答
REST API 举例
- 能用 filter 的咱们就走缓存过滤。
- 将核心 API 脚本实现,监控内存使用率,磁盘使用率、CPU使用率,一旦出问题及时邮件预警。
聚合API:聚合核心就三个维度
- Metric 指标聚合;
- bucket 分桶聚合;
- pipeline 基于聚合的子聚合。
三种方式都可以,需要结合业务灵活使用聚合方式。
9.Elasticsearch 安全性和权限控制相关问题
9.1问题描述
描述在应用程序中实现 Elasticsearch 安全性的策略。
你是如何在 Elasticsearch 中管理细粒度的访问控制?
9.2问题回答
9.2.1描述在应用程序中实现 Elasticsearch 安全性的策略
描述在应用程序中实现 Elasticsearch 安全性的策略?——针对这个问题,
我这边一般是 8.X 高版本,已经自带强调 SSL 证书访问,Kibana 也是安全配置的。
这样之后,Http访问就变成了 Https 访问。
那么在 Python 和 Java 客户端的程序访问也是需要把 Elasticsearch 配置的证书拷贝到给定的工程路径下的。
9.2.2你是如何在 Elasticsearch 中管理细粒度的访问控制?
ES 是能支持到字段级别,不过是收费功能。实际项目中我们使用的开源版本,并未使用这功能。
10.Elasticsearch 容错性和高可用性
10.1问题描述
你如何确保你开发的Elasticsearch应用具备高容错性?
当 Elasticsearch 集群不可用时,你的应用程序如何处理?
10.2问题回答
高容错性是否可以理解为高可用性,如果是高可用性策略
第一:副本策略,多节点集群至少一个副本,确保某个节点宕机后,副本提升为主分片,确保集群的高可用性。
但是,实践验证过,副本不是越多越好,副本越多,意味着牺牲的存储空间越大,一般数据量大的集群扛不住那么多的冗余存储。一般至少一个即可(个人理解的经验值)。除非极其高可用要求的场景,可以超过1个副本,其他不建议。
第二:集群的不定时快照和恢复策略,确保集群万一故障能恢复到某一个时刻的可用状态。
高版本支持 SLM快照生命周期管理功能,这一切的自动化和定时机制变得更加方便和快捷。
11.Elasticsearch 监控和警报机制
11.1问题描述
在开发过程中,你如何利用监控工具如 Elasticsearch 的 X-Pack 或其他插件来观察集群的健康状况?
你如何设置和处理与 Elasticsearch 相关的警报?
11.2问题回答
11.2.1在开发过程中,你如何利用监控工具如 Elasticsearch 的 X-Pack 或其他插件来观察集群的健康状况?
x-pack 插件高版本 7.X 版本已经集成,不再需要二次安装。
一般借助 kibana 的可视化,使用 Metricbeat 收集指标数据,同步到 Elasticsearch ,借助kibana 进行集群数据监控的可视化。
11.2.2你如何设置和处理与 Elasticsearch 相关的警报?
警报部分是收费功能,成本原因没有用。
不过第三方的 yelp 公司的开源 elasticalert 插件可以用和集成,不确认最新版本是否支持,早期版本用过。
还有,自己开发了必要的 python+shell 脚本,监控集群的健康状态,确保集群出现:cpu、磁盘、内存警戒线一到(自己定义的),就能第一时间收到预警邮件信息。
都是些Elasticsearch的面试分享,欢迎大家批评指正