前言:最近字节跳动提出了一项关于特征一致图像生成的工作StoryDiffusion,可以生成一系列特征主题相关的图像,还可以扩展成具有时间一致性的帧序列,从而组成长视频。这篇博客火速解读这篇最新的工作,包括论文和代码。
目录
第一阶段:基于Consistent Self-Attention的主题相关的图片生成

贡献概述
作者自己概括的三点贡献:
1、我们提出了一个无训练和热插拔注意模块,称为一致自注意力。它可以保持一系列生成的图像中字符的一致性,用于具有高文本可控性的讲故事。
2、我们提出了一种新的运动预测模块,该模块可以预测语义空间中两幅图像之间的转换,称为语义运动预测器。它可以生成比最近流行的图像条件反射方法(如SEINE和SparseCtrl)更容易放大到几分钟的更稳定的远程视频帧。
3、我们表明,我们的方法可以基于预定义的基于文本的故事生成长图像序列或视频,该故事具有建议的一致自注意力和语义运动预测器,其中包含文本提示指定的运动。我们将新框架称为 StoryDiffusion。
方法详解
第一阶段:基于Consistent Self-Attention的主题相关的图片生成

Consistent Self-Attention 对于每一帧在计算Self-Attention 的时候,会随机采样batch 内其他帧的内容,作为Key 和 Value 的一部分,实现了batch 内图像的细节交互。运用Consistent Self-Attention之后,人脸可以保证特别好的保持效果,结合prompt的辅助控制,也能较好的保持衣物细节。
因为保持人物id 的性质,这一部分不仅可以生成关键帧,也可以用作漫画生成,并且可以结合现有的id 保持工具,如photomaker等。
每个图像中的tokens 数量和通道数量,定义一个函数Attention(Xk,Xq,Xv)(X_k, X_q, X_v)来计算自注意力。、和Xk、Xq和XvX_k、X_q和X_v分别表示在注意力计算中使用的查询、键和值。原始的自注意力在每个图像特征IiI_i中独立进行。将特征IiI_i投影到、、Qi、Ki、ViQ_i、K_i、V_i,并送入注意力函数,得到
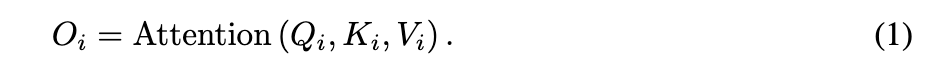
为了在批次内的图像之间建立互动以保持主题一致性,Consistent Self-Attention从批次中的其他图像特征中抽样一些tokens SiS_i。

其中,RandSample表示随机采样函数。采样后,将采样的tokens SiS_i与图像特征Ii配对,形成一个新的tokens 集PiP_i。然后,我们对PiP_i进行线性投影,生成Consistent Self-Attention的新键KPiK_{P_i}和值VPiV_{P_i}。在这里,原始的查询QiQ_i不会改变。最后,计算自注意力如下:
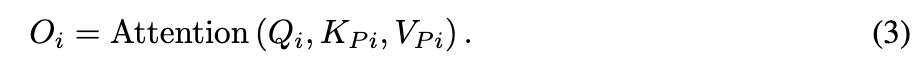
代码如下:
def ConsistentSelfAttention(images_features, sampling_rate, tile_size):
"""
images_tokens: [B, C, N]
sampling_rate: Float (0-1)
tile_size: Int
"""
output = zeros(B, N, C), count = zeros(B, N, C), W = tile_size
for t in range(0, N - tile_size + 1):
# Use tile to override out of GPU memory
tile_features = images_tokens[t:t + W, :, :]
reshape_featrue = tile_feature.reshape(1, W*N, C).repeat(W, 1, 1)
sampled_tokens = RandSample(reshape_featrue, rate=sampling_rate, dim=1) # Concat the tokens from other images with the original tokens
token_KV = concat([sampled_tokens, tile_features], dim=1)
token_Q = tile_features # perform attention calculation:
X_q, X_k, X_v = Linear_q(token_Q), Linear_k(token_KV), Linear_v(token_KV)
output[t:t+w, :, :] += Attention(X_q, X_k, X_v) count[t:t+w, :, :] += 1
output = output/count
return output第二阶段:转换视频生成
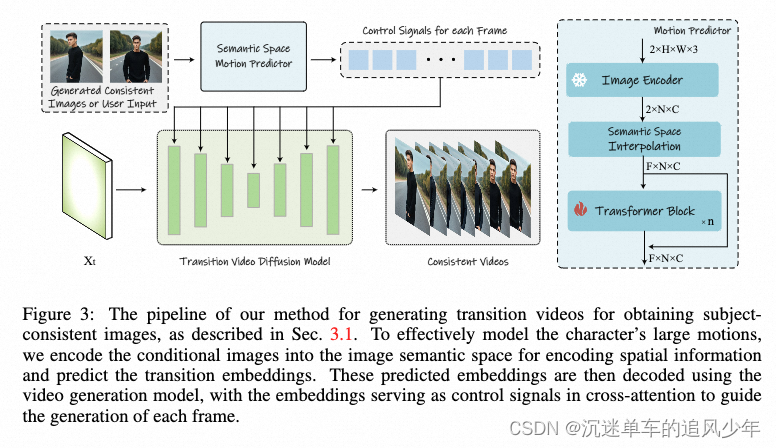
生成的主题一致图像序列可以通过在相邻图像对之间插入帧来进一步细化为视频。这可以被视为一个具有已知起始和结束帧条件的视频生成任务。然而,在经验上观察到,最近的方法,如SparseCtrl和SEINE,在两个图像之间的差异较大时无法稳定地连接两个条件图像。
这种限制源自它们完全依赖于时间模块来预测中间帧,而这可能不足以处理图像对之间的巨大状态差异。时间模块在每个空间位置上独立操作像素,因此,在推断中间帧时可能不充分考虑空间信息。这使得难以建模长和具有物理意义的运动。
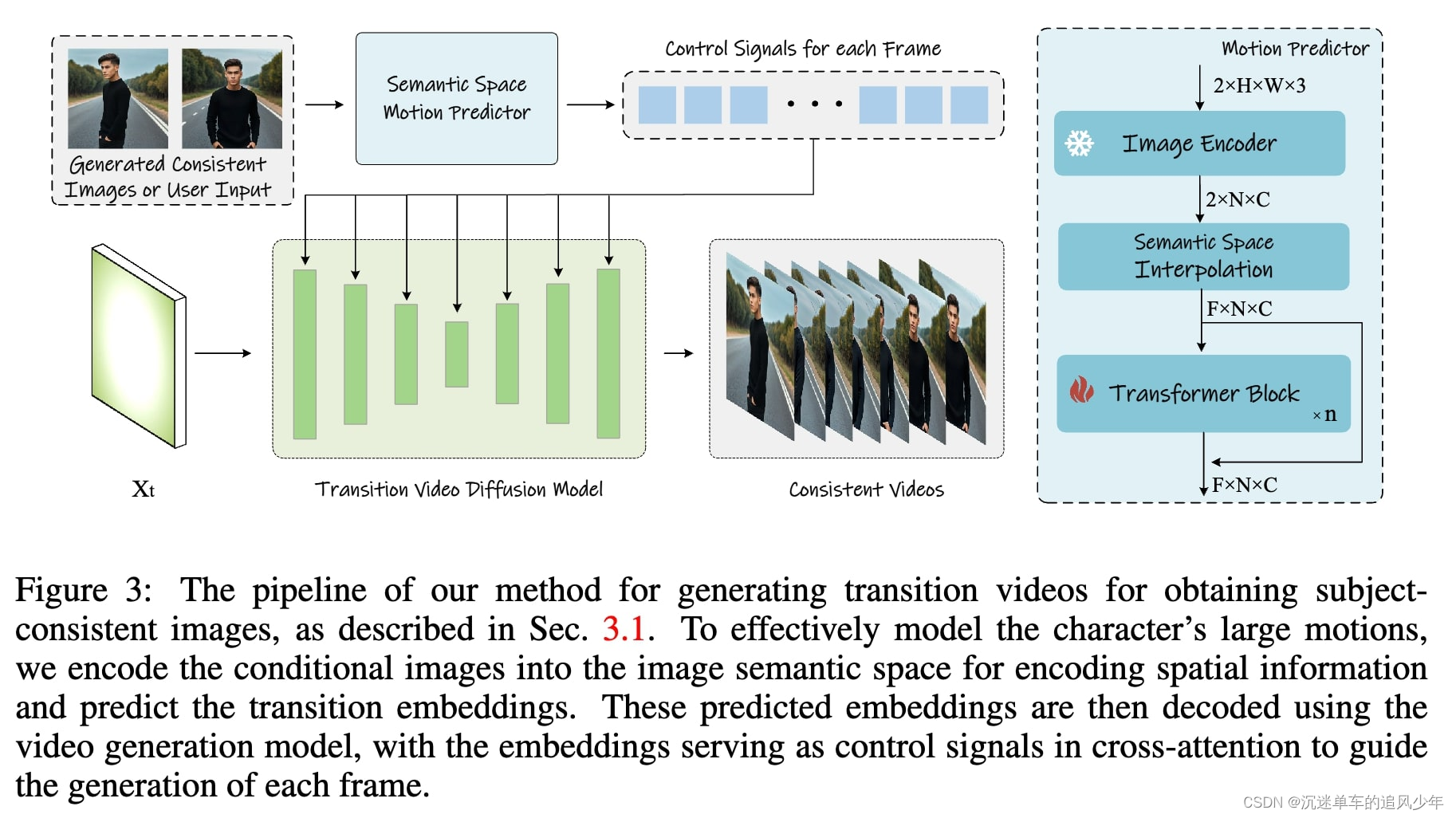
为了解决这个问题,本文提出了语义运动预测器,它将图像编码成图像语义空间中的向量,以捕获空间信息,从而更准确地预测给定起始帧和结束帧之间的运动。
具体来说,在语义运动预测器中,首先使用一个函数 EE 来建立从 RGB 图像到图像语义空间向量的映射,对空间信息进行编码。我们不直接使用线性层作为 EE,而是利用预训练的 CLIP 图像编码器作为 EE,以利用其零次学习能力来增强性能。利用 EE,给定的起始帧 FsF_s 和结束帧 FeF_e 被压缩为图像语义空间向量 KsK_s 和 KeK_e。

随后,在图像语义空间中,训练了一个基于 Transformer 结构的预测器来执行每个中间帧的预测。预测器首先执行线性插值,将两个帧 KsK_s 和 KeK_e 扩展为序列 K1、K2、...、KLK_1、K_2、...、K_L,其中 L 是所需的视频长度。然后,序列 K1、K2、...、KLK_1、K_2、...、K_L 被送入一系列 Transformer 块 B 来预测过渡帧:

接下来,需要将图像语义空间中预测的这些帧解码为最终的过渡视频。受图像提示方法的启发,将这些图像语义嵌入 P1、P2、...、PLP_1、P_2、...、P_L 定位为控制信号,将视频扩散模型定位为解码器,以利用视频扩散模型的生成能力。我们还插入额外的线性层将这些嵌入投影到键和值中,涉及到 U-Net 的跨注意力。
形式上,在扩散过程中,对于每个视频帧特征 ViV_i,我们将文本嵌入 T 和预测的图像语义嵌入 PiP_i 连接起来。跨注意力计算如下:

与先前的视频生成方法类似,我们通过计算预测过渡视频 O=(O1、O2、...、OL)O = (O_1、O_2、...、O_L) 和 L 帧地面真实值 G=(G1、G2、...、GL)G = (G_1、G_2、...、G_L) 之间的均方误差损失来优化我们的模型。

通过将图像编码到图像语义空间以整合空间位置关系,语义运动预测器能够更好地建模运动信息,从而实现生成具有大运动的平滑过渡视频。
代码
https://github.com/HVision-NKU/StoryDiffusion?tab=readme-ov-file
个人感悟
1、2023年上半年的时候VideoZero为代表的基于图像生成模型的zero-shot视频生成方法火了一段时间,方法也是魔改attention;只不过之前的工作更多是魔改cross- attention。毕竟是zero-shot的方法,当时复现的时候发现效果很不稳定,无法落地。
2、个人还是更倾向于把时间一致性的能力交给基模型;不过放出的demo效果很好,后面博主会着手复现其工作,博采众长吧。
3、开源yyds,看时间线应该是投稿了nips,个人认为中的几率很大。