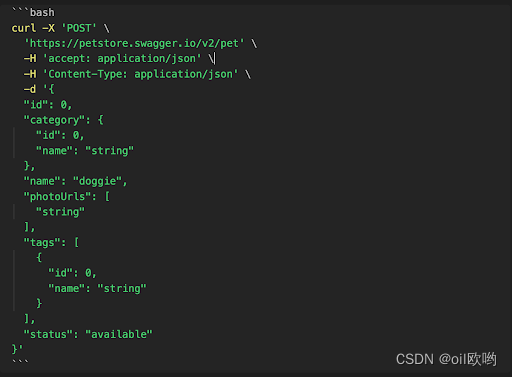
索引失效
CREATE TABLE `tradelog`
(
`id` int(11) NOT NULL,
`tradeid` varchar(32) DEFAULT NULL,
`operator` int(11) DEFAULT NULL,
`t_modified` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `tradeid` (`tradeid`),
KEY `t_modified` (`t_modified`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
1、条件字段函数操作
select count(*)
from tradelog
where month (t_modified)=7;
-- month(t_modified) : 对索引字段做函数操作,可能会破坏索引值的有序性,会导致全表扫描
select *
from tradelog
where id + 1 = 10000;
-- 优化器偷懒,MySQL 优化器不能用 id 索引快速定位到 9999 这一行。
-- 所以,需要你在写 SQL 语句的时候,手动改写成 where id = 10000 -1 才可以。
2、隐式类型转换
select *
from tradelog
where tradeid = 110717;
-- MySQL 中,字符串和数字做比较的话,是将字符串转换成数字
-- 对于优化器来说,这个语句相当于:select * from tradelog where CAST(tradid AS signed int) = 110717;
3、隐式字符编码转换
两个表的字符集不同、字符集相同关联字段类型不同;
连接过程中关联字段会按照转换规则转化, 如果转化驱动表的字段,被驱动表还是会走索引的, 如果转化的是被驱动表的字段,则驱动表不会走, 是直接导致对被驱动表做全表扫描的原因。
只查一行的语句,执行慢
- 1、查询长时间不返回
先执行一下 show processlist 命令,看看当前语句处于什么状态
线程的状态是 Waiting for table metadata lock 表示有一个线程正在表上请求或者持有 MDL 写锁,把 select 语句堵住了。
找到谁持有 MDL 写锁,然后把它 kill 掉select blocking_pid from sys.schema_table_lock_waits
找出造成阻塞的 process id,把这个连接用 kill 命令断开即可线程的状态是 Waiting for table flush 表示的是,现在有一个线程正要对表做 flush 操作
可能情况是:有一个 flush tables 命令被别的语句堵住了,然后它又堵住了我们的 select 语句
-- MySQL 里面对表做 flush 操作的用法 -- 如果指定表 t 的话,代表的是只关闭表 t; -- 如果没有指定具体的表名,则表示关闭 MySQL 里所有打开的表。 -- 这两个语句执行起来都很快,除非它们也被别的线程堵住了 flush tables t with read lock; flush tables with read lock;select * from t where id=1 lock in share mode;
线程的状态是 statistics 表示的是,有一个事务在这行记录上持有一个写锁,select 语句就会被堵住--找到阻塞的线程 blocking_pid -- KILL pid 断开连接,让事务回滚,释放锁 -- 占有行锁的是 update 语句,这个语句已经是之前执行完成了的,现在执行 KILL QUERY,无法让这个事务去掉行锁 select * from t sys.innodb_lock_waits where locked_table=`'test'.'t'`
- 2、查询慢
两个事务,一个事务更新一条数据100万次,
另一个事务使用“快照读”,需要把当前数据执行100万次 undo log 会比较慢
使用当前读,虽然加锁但时间会更快一点
慢查询性能
索引没有设计好
SQL 语句没写好
MySQL 选错了索引
-- SQL 语句没写好/选错了索引
-- 不重发服务,使用 MySQL 提供了 query_rewrite 功能
select *
from t
where id + 1 = 10000;
-- 改写规则
insert into query_rewrite.rewrite_rules(pattern, replacement, pattern_database)
values ("select * from t where id + 1 = ?", "select * from t where id = ? - 1", "db1");
-- 插入的新规则生效
call query_rewrite.flush_rewrite_rules();
order by
尽量使用索引,避免排序
- 使用了索引,无法避免排序(使用的索引和排序的字段不一致)
1、排序字段存在于多个索引中
2、排序字段,升降序不一致
3、组合索引,k1查询,k2排序
group by
1、如果对 group by 语句的结果没有排序要求,要在语句后面加 order by null;
2、尽量让 group by 过程用上表的索引,确认方法是 explain 结果里没有 Using temporary 和 Using filesort;
3、如果 group by 需要统计的数据量不大,尽量只使用内存临时表;也可以通过适当调大 tmp_table_size 参数,来避免用到磁盘临时表;
4、如果数据量实在太大,使用 SQL_BIG_RESULT 这个提示,来告诉优化器直接使用排序算法得到 group by 的结果。
join
- 使用 left join 时,左边的表不一定是驱动表。
- 如果需要 left join 的语义,就不能把被驱动表的字段放在 where 条件里面做等值判断或不等值判断,必须都写在 on 里面。
- join 将判断条件是否全部放在 on 部分没有区别
优化分页查询
通常使用 <LIMIT M,N> + 合适的 order by 来实现分页查询,这种实现方式在没有任何索引条件支持的情况下,需要做大量的文件排序操作(file sort),性能将会非常得糟糕。如果有对应的索引,通常刚开始的分页查询效率会比较理想,但越往后,分页查询的性能就越差。
在使用 LIMIT 的时候,偏移量 M 在分页越靠后的时候,值就越大,数据库检索的数据也就越多。例如 LIMIT 10000,10 这样的查询,数据库需要查询 10010 条记录,最后返回 10 条记录。也就是说将会有 10000 条记录被查询出来没有被使用到。
- 禁止传入过大的页
- 避免扫描无用的行,覆盖查询+子查询(先查主键,根据主键查数据)
Explain
explain 后使用 show warnings 可以看到优化器优化之后的 SQL
id
SELECT的查询序列号, id如果相同,可以认为是一组,从上往下顺序执行;在所有组中,id值越大,优先级越高,越先执行
select_type
每个select子句的类型
| 取值 | 含义 |
|---|---|
| SIMPLE | 简单SELECT,不使用UNION或子查询等 |
| PRIMARY | 子查询中最外层查询,查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY |
| UNION | UNION中的第二个或后面的SELECT语句 |
| DEPENDENT UNION | UNION中的第二个或后面的SELECT语句,取决于外面的查询 |
| UNION RESULT | UNION的结果,union语句中第二个select开始后面所有select |
| SUBQUERY | 子查询中的第一个SELECT,结果不依赖于外部查询 |
| DEPENDENT SUBQUERY | 子查询中的第一个SELECT,依赖于外部查询 |
| DERIVED | 派生表的SELECT, FROM子句的子查询 |
| UNCACHEABLE SUBQUERY | 一个子查询的结果不能被缓存,必须重新评估外链接的第一行 |
table
显示这一步所访问数据库中表名称
partitions
访问的分区表信息
type
MySQL在表中找到所需行的方式
| 取值 | 含义 |
|---|---|
| ALL | MySQL将遍历全表以找到匹配的行 |
| index | index与ALL区别为index类型只遍历索引树 |
| range | 只检索给定范围的行,使用一个索引来选择行 |
| ref | 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值 |
| eq_ref | 多表连接中使用primary key或者 unique key作为关联条件 |
| const、system | 当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用system |
| NULL | MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。 |
possible_keys
MySQL能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用(该查询可以利用的索引,如果没有任何索引显示 null)
Key
显示MySQL实际决定使用的索引,必然包含在possible_keys中
key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度(key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的)
ref
列与索引的比较,表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
rows
估算出结果集行数,表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数
Extra
| 取值 | 含义 |
|---|---|
| Using filesort | 表示的就是需要排序 |
| Using index | 表示的就是使用了覆盖索引 |
| Using temporary | 表示的是需要使用临时表 |
| Block Nested Loop | 表示 join 语句使用 Block Nested-Loop Join 算法,在大表上的 join 操作,这样可能要扫描被驱动表很多次,会占用大量的系统资源。所以这种 join 尽量不要用。 |
| Using MRR | 表示的是用上了 MRR 优化,由于在 read_rnd_buffer 中按照 id 做了排序,所以最后结果集也是按照主键 id 递增顺序的 |
| Using join buffer (Block Nested Loop) | 表示的是用 BNL 算法 |
| Using where | 需要在服务层过滤数据(mysql分为服务层和存储引擎层) |
| using index condition | 需要回表查询数据,但是有部分数据是在二级索引过滤后,再回表查询数据,减少了回表查询的数据行数 |
Show Profile 分析 SQL 执行性能
SHOW PROFILE [type [, type] ... ]
[FOR QUERY n]
[LIMIT row_count [OFFSET offset]]
type 参数:
| ALL:显示所有开销信息
| BLOCK IO:阻塞的输入输出次数
| CONTEXT SWITCHES:上下文切换相关开销信息
| CPU:显示 CPU 的相关开销信息
| IPC:接收和发送消息的相关开销信息
| MEMORY :显示内存相关的开销,目前无用
| PAGE FAULTS :显示页面错误相关开销信息
| SOURCE :列出相应操作对应的函数名及其在源码中的调用位置 (行数)
| SWAPS:显示 swap 交换次数的相关开销信息
可以通过 set 语句在 Session 级别开启该功能:
select @@profiling;
set @@profiling=1;
Show Profiles 只显示最近发给服务器的 SQL 语句,默认情况下是记录最近已执行的 15 条记录,可以重新设置 profiling_history_size 增大该存储记录,最大值为 100。
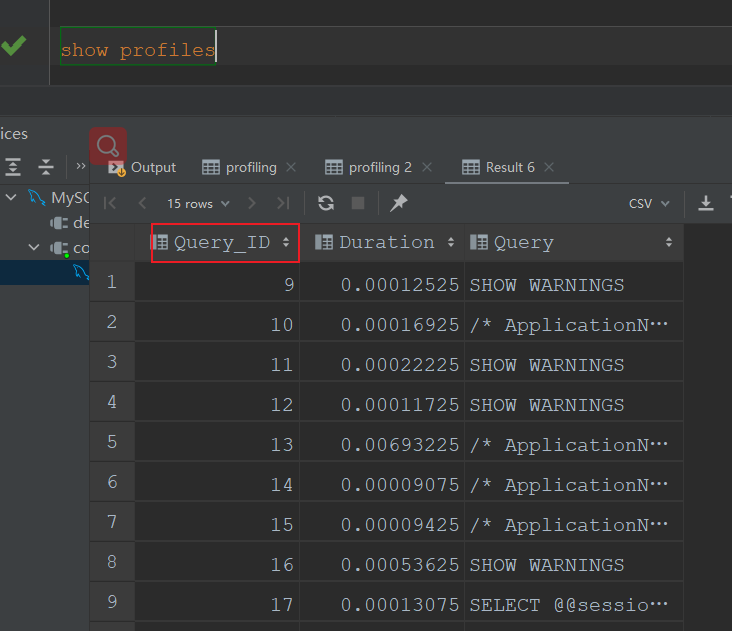
获取到 Query_ID 之后,再通过 Show Profile for Query ID 语句,就能够查看到对应 Query_ID 的 SQL 语句在执行过程中线程的每个状态所消耗的时间了:
慢日志
#慢查询日志配置
,slow_query_log的值为OFF,表示慢查询日志是禁用的
show variables like '%slow_query_log%';
#开启慢查询日志
,1表示开启,0表示关闭
set global slow_query_log =1;
#
将慢查询日志的阈值设置为 0,表示这个线程接下来的语句都会被记录入慢查询日志中
set long_query_time=0;
optimizer_trace
/* 打开 optimizer_trace,只对本线程有效 */
SET
optimizer_trace='enabled=on';
/* @a 保存 Innodb_rows_read 的初始值 */
select VARIABLE_VALUE
into @a
from performance_schema.session_status
where variable_name = 'Innodb_rows_read';
/* 执行语句 */
select city, name, age
from t
where city = '杭州'
order by name limit 1000;
/* 查看 OPTIMIZER_TRACE 输出 */
SELECT *
FROM `information_schema`.`OPTIMIZER_TRACE`;
/* @b 保存 Innodb_rows_read 的当前值 */
select VARIABLE_VALUE
into @b
from performance_schema.session_status
where variable_name = 'Innodb_rows_read';
/* 计算 Innodb_rows_read 差值
表示整个执行过程扫描的行数
*/
select @b - @a;
R_TRACE 输出 */
SELECT *
FROM `information_schema`.`OPTIMIZER_TRACE`;
/* @b 保存 Innodb_rows_read 的当前值 */
select VARIABLE_VALUE
into @b
from performance_schema.session_status
where variable_name = 'Innodb_rows_read';
/* 计算 Innodb_rows_read 差值
表示整个执行过程扫描的行数
*/
select @b - @a;