常用指标:
- 准确率(Accuracy) Accuracy (TP + TN) / (TP + TN + FP + FN) 正确预测的样本数占总样本数的比例。
- 精确率(Precision) Precision TP / (TP + FP) 在所有预测为正的样本中,真正的正样本所占的比例。
- 召回率(Recall) Recall TP / (TP + FN) 在所有实际为正的样本中,被正确预测为正的比例。
1. confusion_matrix_normalized.png和confusion_matrix.png
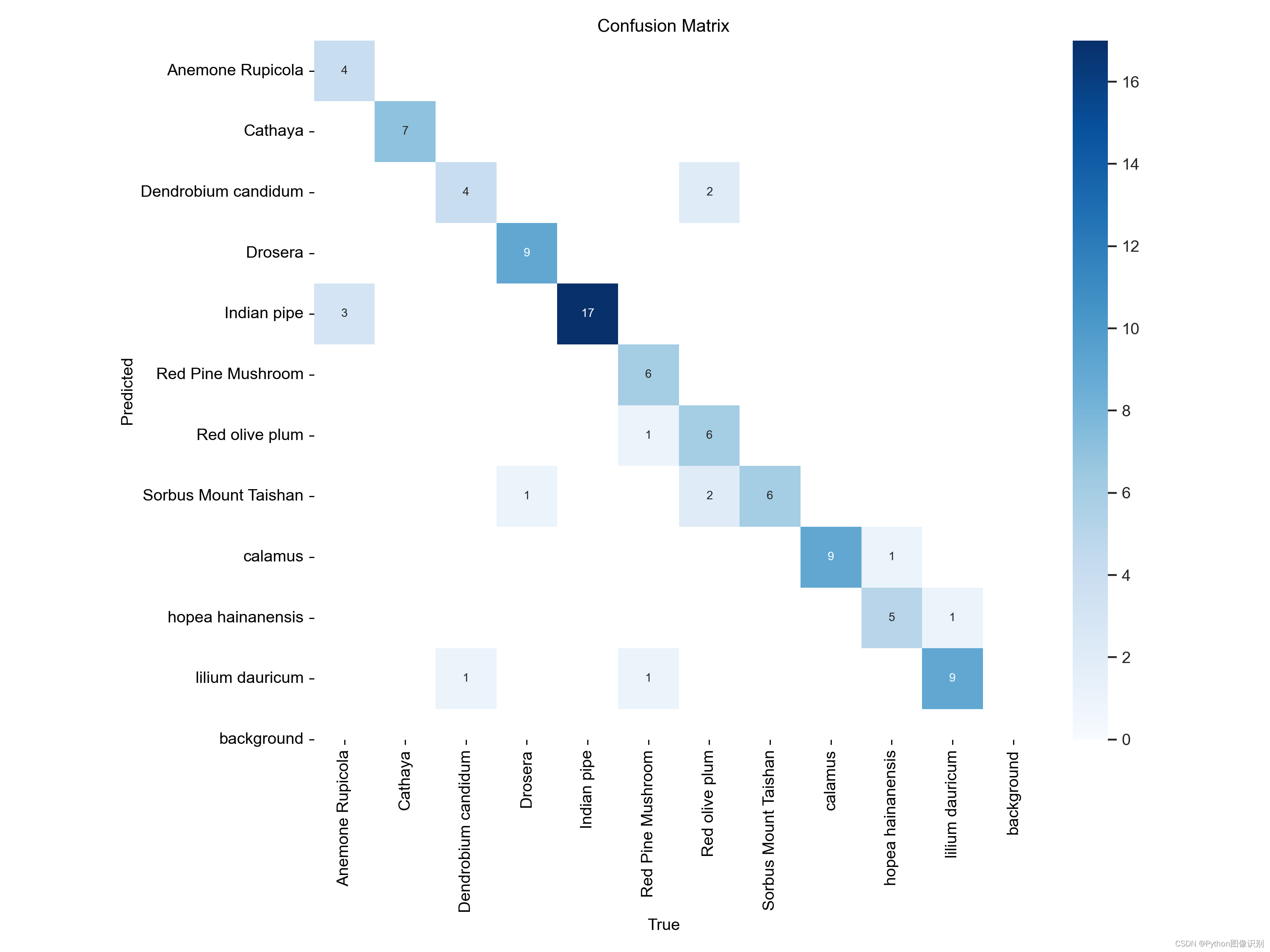
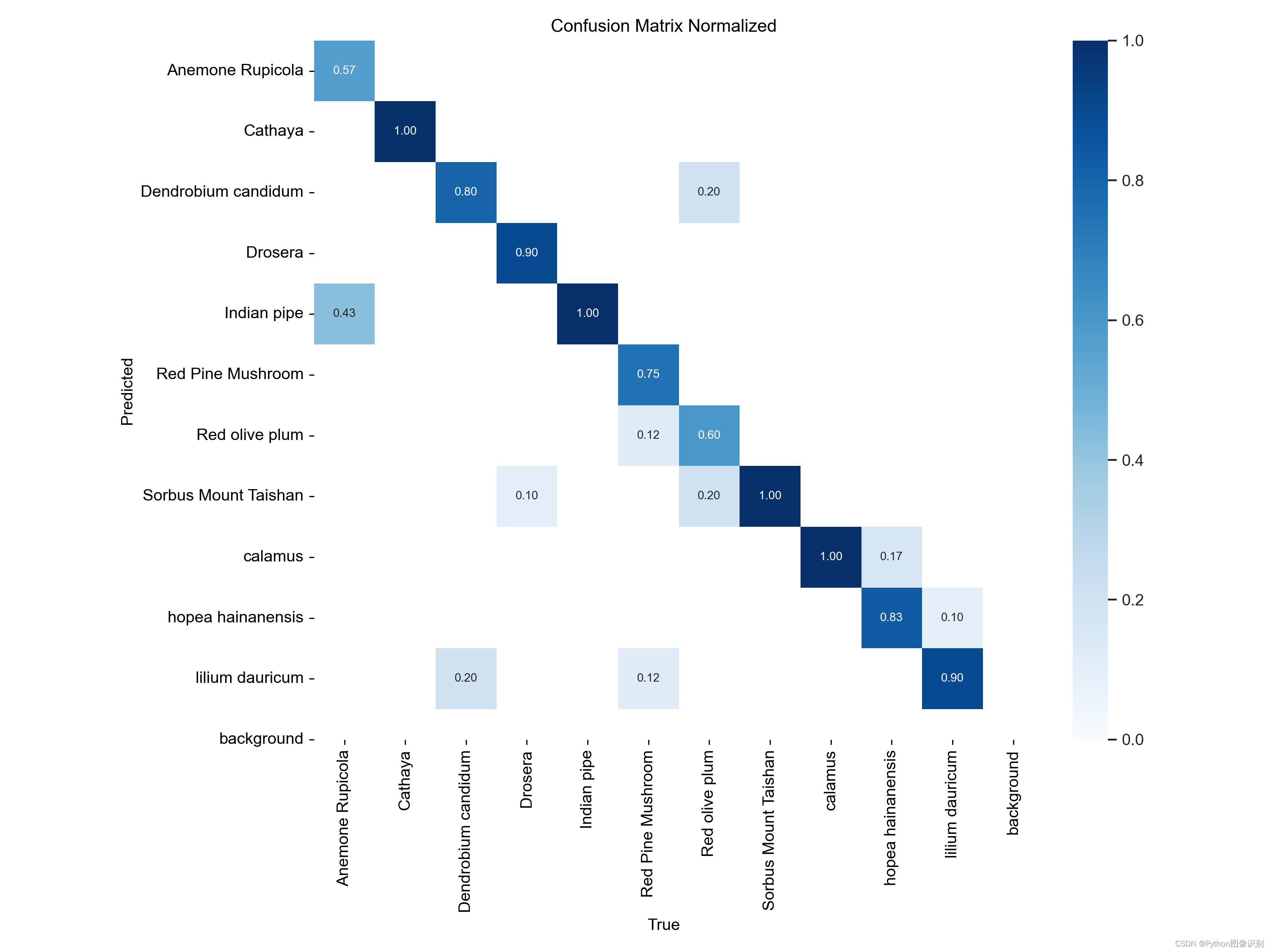
混淆矩阵(Confusion Matrix),是评估分类模型性能的一个常用工具。混淆矩阵通过比较模型的预测结果和实际标签,来展示模型在各个类别上的表现。
混淆矩阵的基本构成:
混淆矩阵是一个表格,表格的行代表实际的类别,列代表模型预测的类别。矩阵中的每个单元格表示模型将某个类别预测为另一个类别的样本数量。
1. 主对角线上的值: 表示模型正确分类的样本数量。也就是说,如果一个类别在主对角线上的值很高,这意味着模型在这个类别上的表现很好。
2. 非对角线上的值: 表示模型将一个类别错误地预测为另一个类别的样本数量。值越大,表示模型在这两个类别之间的混淆越严重。
3. 背景: 通常混淆矩阵中会有一个表示背景或非目标类别的行和列。在这个例子中,“background”就是背景类别,它表示模型将背景错误分类的数量。
混淆矩阵是一个表格,用于显示分类模型在测试数据上的预测结果与实际标签之间的关系。它将实际标签分为正例(Positive)和负例(Negative),将预测结果划分为真阳性(True Positive)、真阴性(True Negative)、假阳性(False Positive)和假阴性(False Negative)四种情况。
- 真阳性(True Positive):模型正确预测为正例的样本数。
- 真阴性(True Negative):模型正确预测为负例的样本数。
- 假阳性(False Positive):模型错误地将负例预测为正例的样本数。
- 假阴性(False Negative):模型错误地将正例预测为负例的样本数。
confusion_matrix_normalized.png 是经过归一化处理的混淆矩阵图。归一化后的混淆矩阵显示的是预测结果的相对比例或百分比,可以更清楚地了解模型在不同类别上的分类准确性。
confusion_matrix.png 则是未经过归一化处理的混淆矩阵图,显示的是预测结果的绝对数量。
这两个图表可以帮助您分析模型在不同类别上的分类性能,进而评估模型的准确性、召回率和误报率等指标。
精确率和召回率的计算方法
- 精确率Precision=TP / (TP+FP), 在预测是Positive所有结果中,预测正确的比重
- 召回率recall=TP / (TP+FN), 在真实值为Positive的所有结果中,预测正确的比重
2. results.png
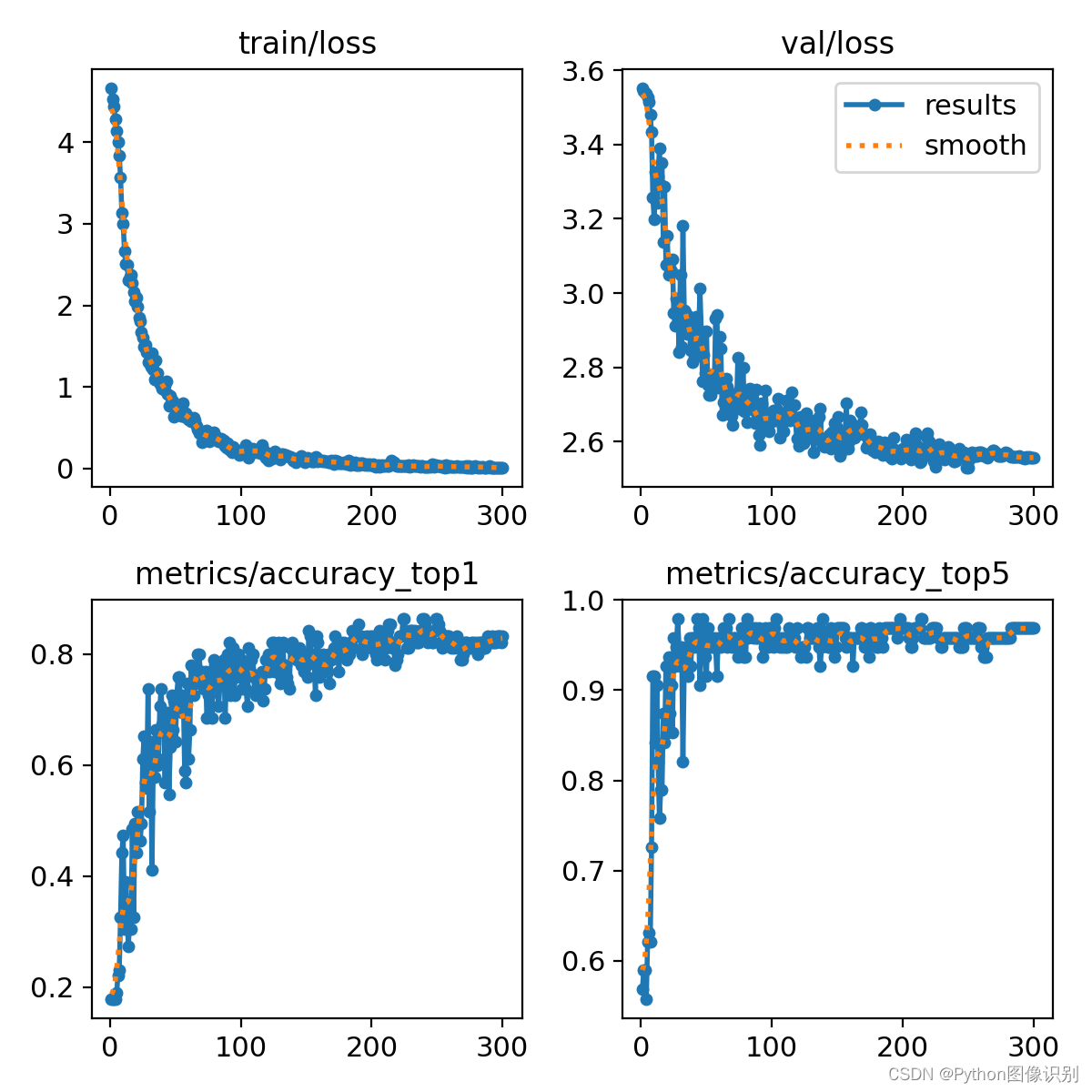
这张表格显示了深度学习模型在训练过程中的一些关键指标,包括损失值(loss)和准确率(accuracy)。表格分为两个部分:训练集(train)和验证集(val)。
损失值(Loss)
训练损失(train/loss):表示模型在训练集上的平均损失。损失值是衡量模型预测与实际值之间差异的指标。损失值越低,表示模型在训练集上的拟合效果越好。
验证损失(val/loss):表示模型在验证集上的平均损失。验证集是模型在训练过程中未见过的数据,验证损失用于评估模型的泛化能力,即对新数据的预测能力。
准确率(Accuracy)
. 准确率(metrics/accuracy top1):通常称为Top-1准确率,表示模型第一次预测即准确匹配到正确类别的比例。在多分类问题中,这是最直接的准确率度量。
Top-5准确率(metrics/accuracy top5):表示在模型的前五个预测中至少有一个正确匹配到正确类别的比例。在某些情况下,如果问题允许多个正确答案或者为了衡量模型的健壮性,Top-5准确率也是一个重要的指标。
曲线变化
训练损失:随着训练的进行,损失值从3.6逐渐下降到2.6左右,这表明模型在训练集上的表现在改善。
验证损失:验证损失也呈现下降趋势,从3.4下降到3.0左右
Top-1准确率:准确率从0.6逐渐提升到0.9左右,说明模型的预测准确度在提高。
Top-5准确率:Top-5准确率从0.8提升到1.0,这表明在模型的前五个预测中,所有情况下至少有一个是正确的,这是一个非常强的表现。
3. train_batchx
训练数据示意图

4. val_batch0_labels 和 val_batch0_pred
val_batchx_labels:验证集第x轮的实际标签
val_batchx_pred:验证集第x轮的预测标签



































![[oeasy]python0015_键盘改造_将esc和capslock对调_hjkl_移动_双手正位](https://img-blog.csdnimg.cn/img_convert/8a6873206abc03291204d643d5a7db02.png)