| 研究工作进度安排: (根据学校安排自行修改) 1、查阅资料,拟定写作大纲,完成研究内容、现状、方法的研究等,提交开题报告; 2、基本完成毕业设计及毕业论文草稿的撰写; 3、提交中期检查相关资料,参加中期检查; 4、修改完善毕业设计,完成毕业设计和论文定稿的撰写; 5、提交答辩申请,参加答辩; 6、提交论文最终稿,打印装订论文,整理并上交全套毕业论文(设计)资料。 |
| 参考文献目录: [1] 基于短视频内容理解的用户偏好预测模型研究[D]. Muhammad Irbaz Siddique.北京交通大学,2023 [2] 基于人像聚类的短视频推荐系统的研究与实现[D]. 郝艳峰.辽宁大学,2022 [3] 基于前景理论的视频推荐方法研究[D]. 李天鹏.河南财经政法大学,2021 [4] 高校视频公开课点播平台智能推荐系统的设计与实现[D]. 陈汉福.华南理工大学,2022 [5] 基于物品协同过滤的个性化视频推荐算法改进研究[D]. 卜旭松.宁夏大学,2021 [6] 基于图论的个性化视频推荐算法研究[D]. 陈壁生.华南理工大学,2023 [7] 基于深度观看兴趣网络的视频推荐系统设计与实现[D]. 刘端阳.北京邮电大学,2021 |
| 指导教师意见: 签名: 2023年3月 29日 |
| 教研室主任意见: 签名: 2023年3 月29日 |

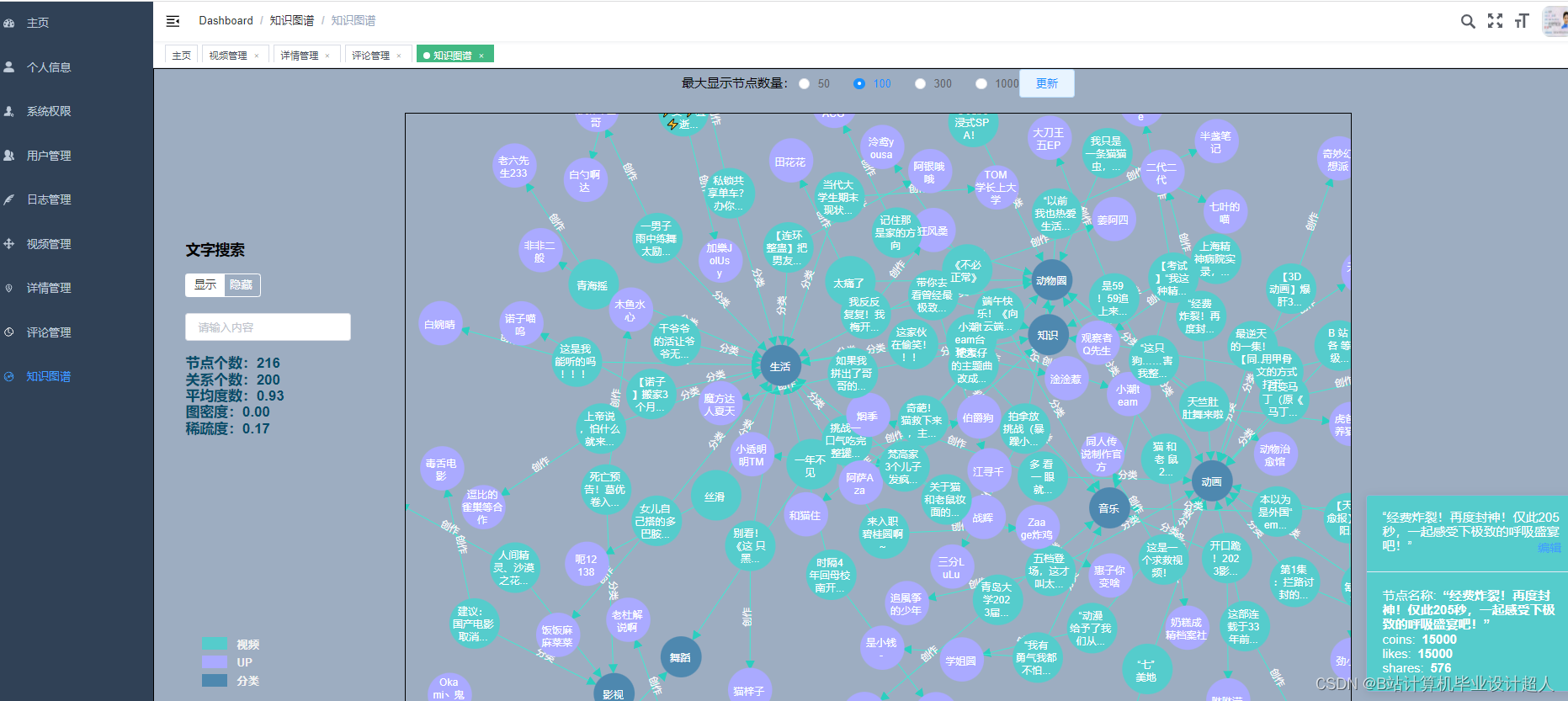
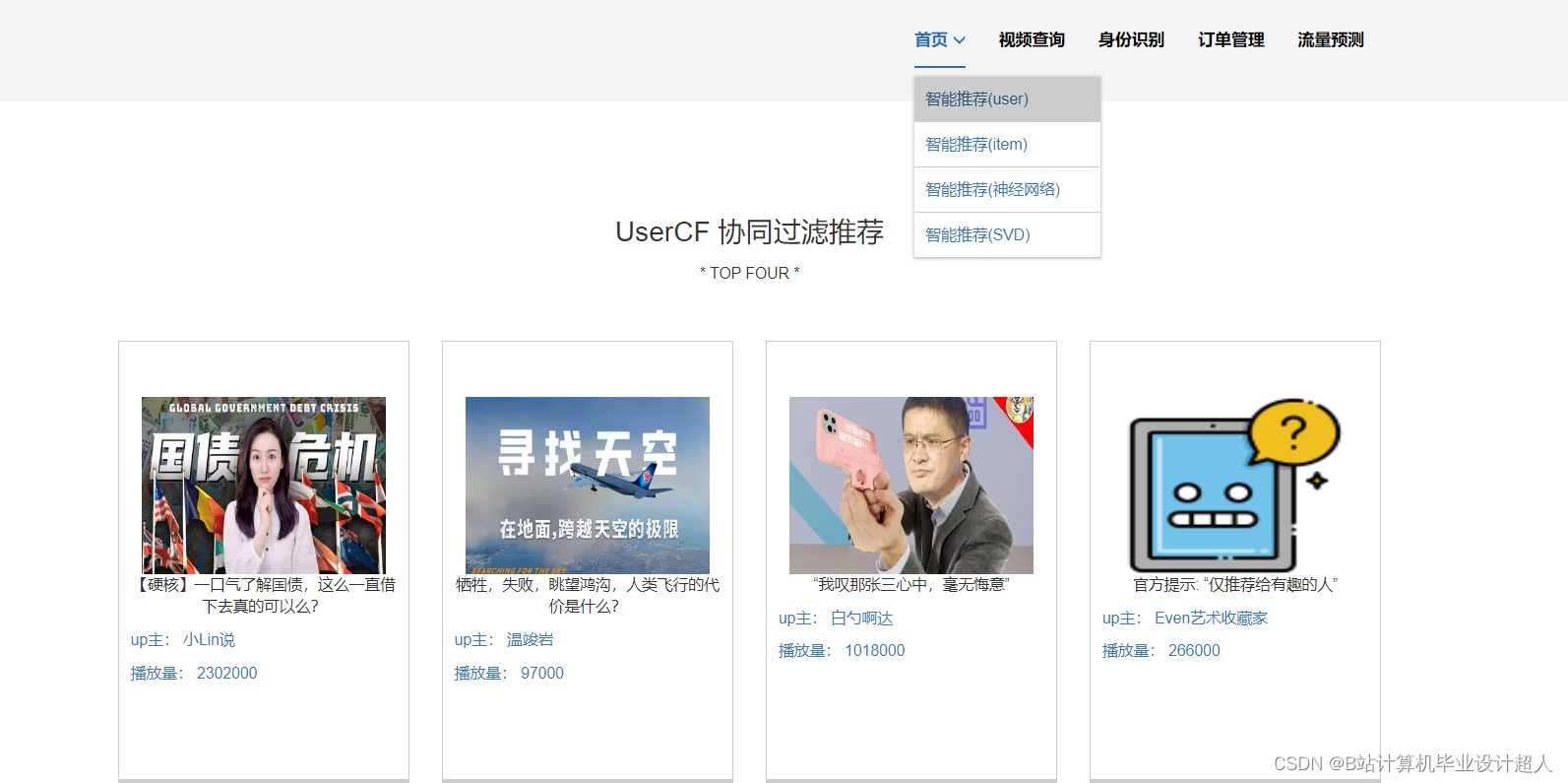
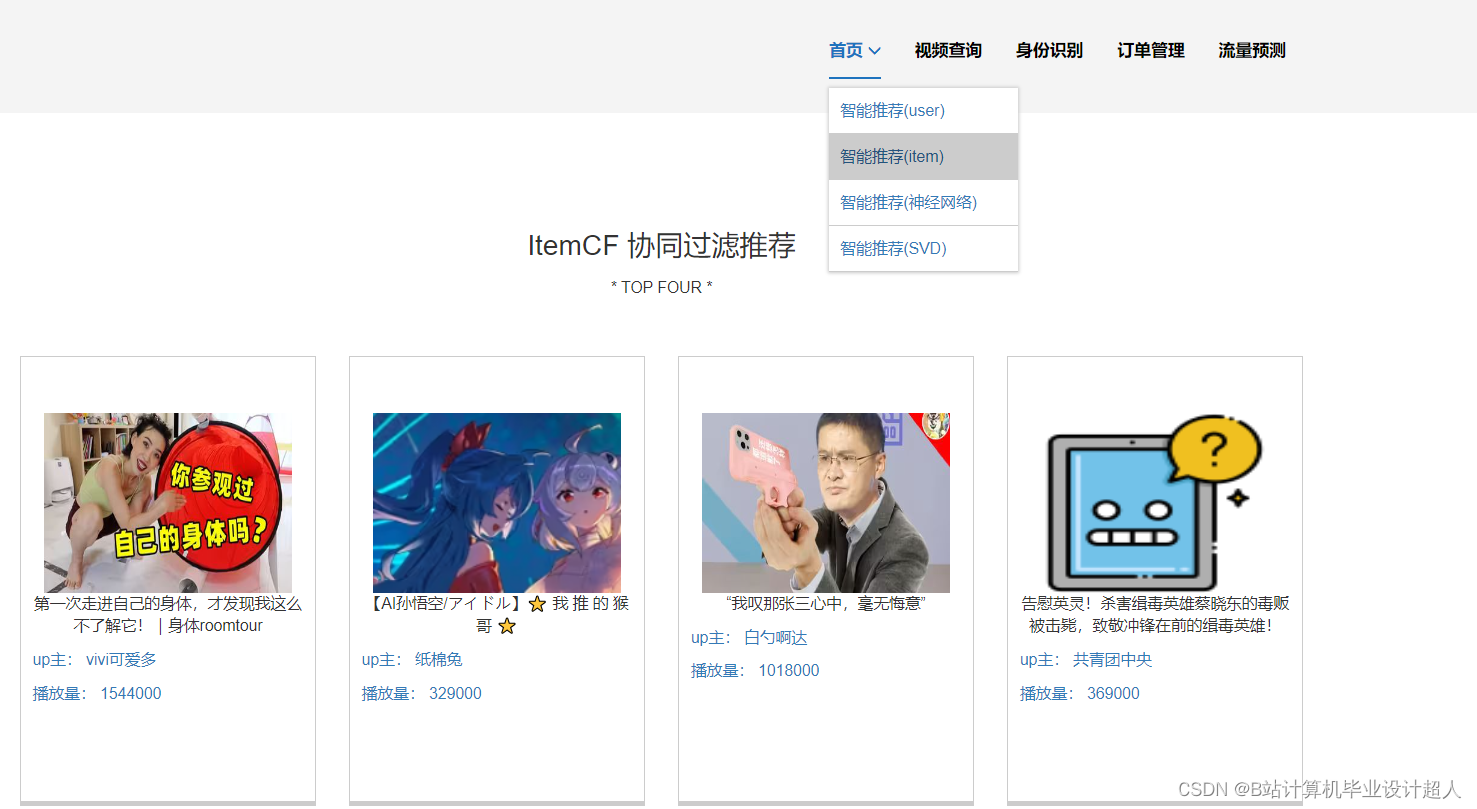
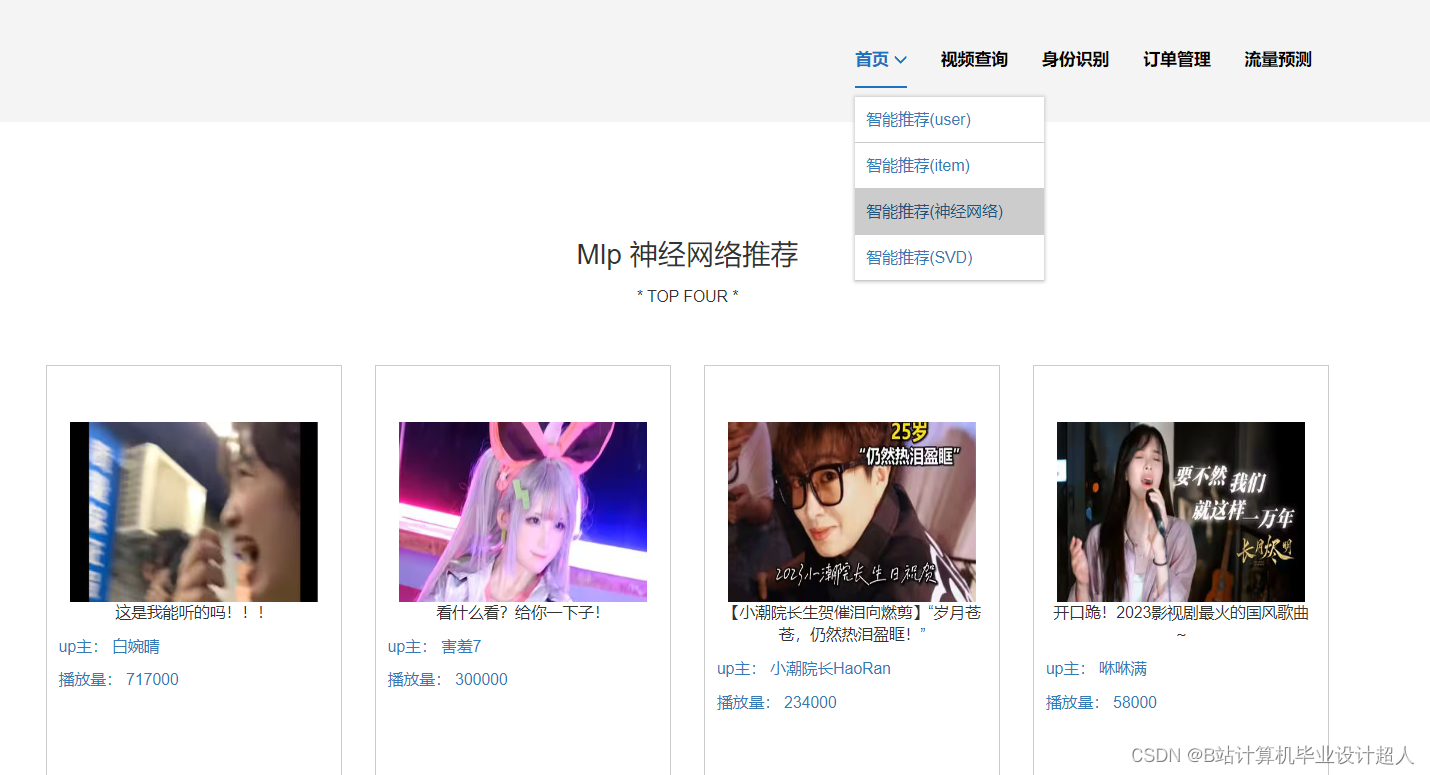
核心算法代码分享如下:
# -*- codeing = utf-8 -*-
# 创建图谱专用的json文件
#
import numpy as np
import pandas as pd
import json
from db import db_util
d = db_util()
db, cursor = d.get_conn()
def build():
s_dict = {}
t_dict = {}
ret = []
ind1 = 10000
ind2 = 20000
ind3 = 30000
rind = 900000
sql = 'select * from tb_detail'
df = pd.read_sql(sql, con=db)
for index, row in df.iterrows():
up_name = row['up_name']
tags = row['tags'].split(',')[0]
if up_name not in s_dict:
ind2 = ind2 + 1
s_dict[up_name] = ind2
index2 = ind2
else:
index2 = s_dict[up_name]
if tags not in t_dict:
ind3 = ind3 + 1
t_dict[tags] = ind3
index3 = ind3
else:
index3 = t_dict[tags]
properties = {"name": row['title'], 'coins': row['coins'], 'likes':row['likes'], 'shares':row['shares']}
start = {'identity': index, 'labels':['视频'], 'properties':properties}
end = {'identity': index2, 'labels':['UP'], 'properties':{"name": up_name}}
relationship = {"identity": rind, "start": index,"end": index2,
"type": "type", "properties": {"name": "创作"}}
rind = rind + 1
segments = []
segments.append(dict(start=start, relationship=relationship, end=end))
end = {'identity': index3, 'labels': ['分类'], 'properties': {"name": tags}}
relationship = {"identity": rind, "start": index, "end": index3,
"type": "type", "properties": {"name": "分类"}}
rind = rind + 1
segments.append(dict(start=start, relationship=relationship, end=end))
p = dict(segments=segments, length=1.0)
ret.append(dict(p=p, score=2))
json_str = json.dumps(ret, ensure_ascii=False)
with open('test.json', 'w', encoding='utf8') as f2:
# ensure_ascii=False才能输入中文,否则是Unicode字符
# indent=2 JSON数据的缩进,美观
json.dump(ret, f2, ensure_ascii=False, indent=2)
print(json_str)
print("end..")
if __name__ == '__main__':
build()
























![[学习笔记]CyberDog小米机器狗 开发学习](https://img-blog.csdnimg.cn/direct/3d57d3cae91941eeba4f7e02152521bc.png)