博主介绍:✌全网粉丝100W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
🍅由于篇幅限制,想要获取完整文章或者源码,或者代做,可以给我留言或者找我聊天。🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人 。
文章包含:项目选题 + 项目展示图片 (必看)
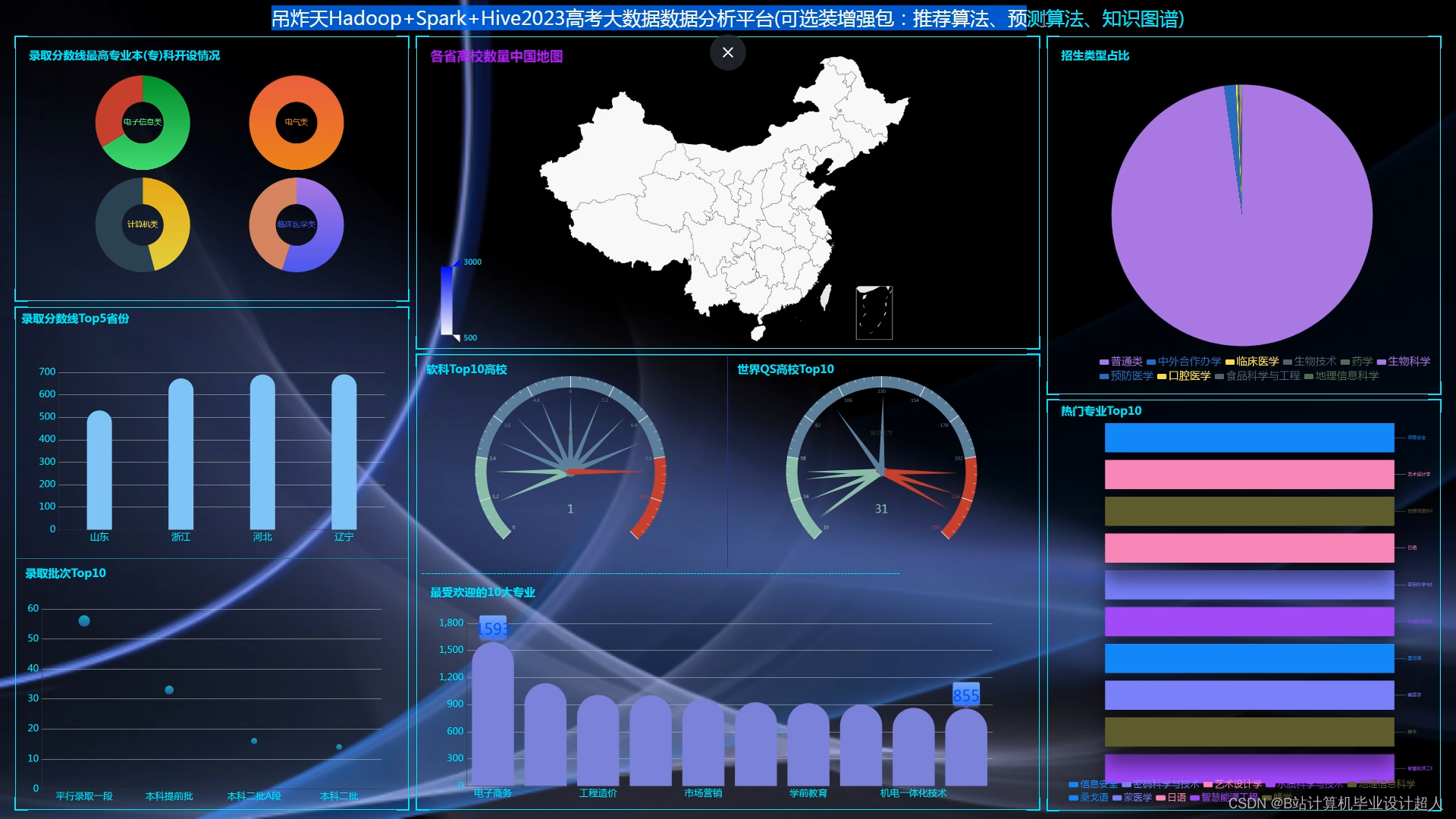
创新点:协同过滤算法基于用户 物品双实现 可视化hadoop+spark 爬虫获取完整数据包含2023年 情感分析 支付 识别 短信 相比老款的优势是新增了强大的爬虫可以完整获取2023数据
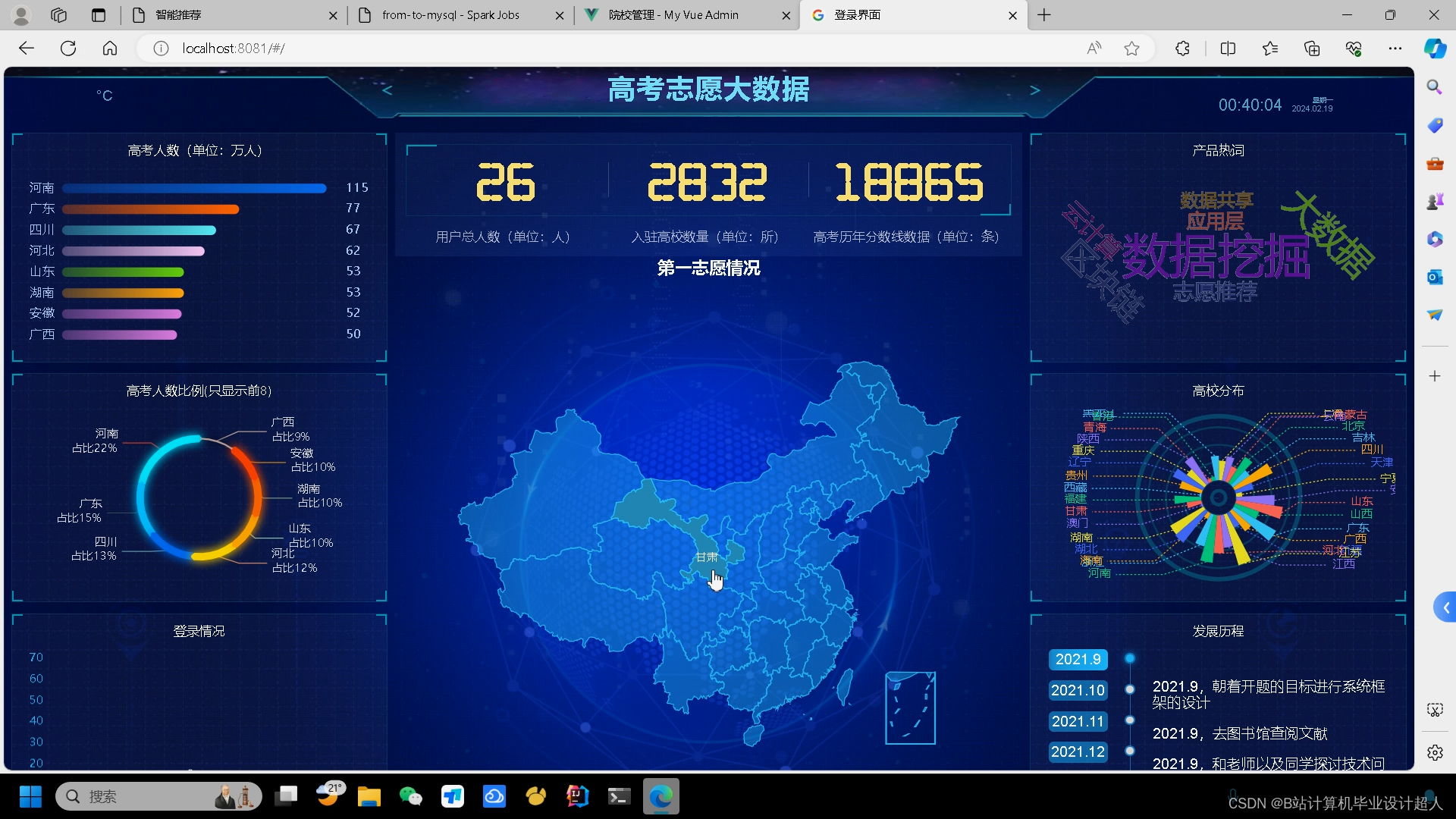




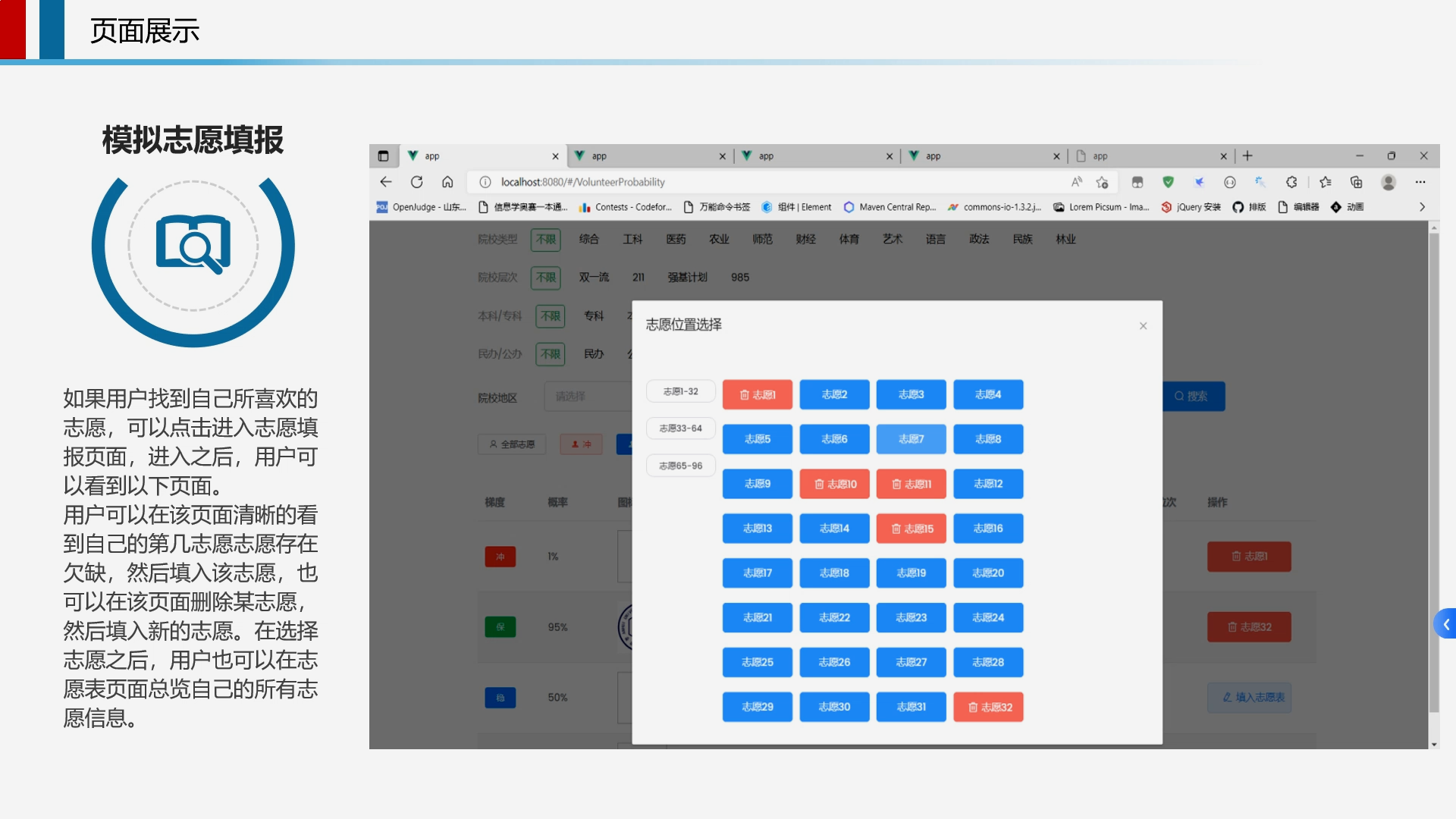
计算机毕业设计吊打导师hadoop+spark高考志愿填报推荐系统 高考大数据 高考分数线预测系统 高考可视化 高考数据分析 高考爬虫 大数据毕业设计 机器学习
import numpy as np
import pandas as pd
from keras.models import Sequential
from keras.layers import LSTM, Dense
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
# 加载数据
# 假设您有一个名为'gaokao_scores.csv'的CSV文件,其中包含两列:'year'和'score'
data = pd.read_csv('gaokao_scores.csv')
# 对数据进行预处理
# 将年份转换为从1977年开始的整数索引
data['year'] = data['year'] - 1977
# 对分数线进行归一化处理
scaler = MinMaxScaler(feature_range=(0, 1))
data['score'] = scaler.fit_transform(data['score'].values.reshape(-1, 1))
# 将数据分为训练集和测试集
train_size = int(len(data) * 0.7)
test_size = len(data) - train_size
train, test = data[0:train_size, :], data[train_size:len(data), :]
# 创建训练数据
def create_dataset(dataset, look_back=1):
X, y = [], []
for i in range(len(dataset) - look_back - 1):
a = dataset[i:(i + look_back), 0] # 年份
X.append(a)
y.append(dataset[i + look_back, 1]) # 分数线
return np.array(X), np.array(y)
look_back = 3 # 选择一个合适的回溯期
X_train, y_train = create_dataset(train, look_back)
X_test, y_test = create_dataset(test, look_back)
# 重塑输入数据以符合LSTM的输入要求
X_train = np.reshape(X_train, (X_train.shape[0], 1, X_train.shape[1]))
X_test = np.reshape(X_test, (X_test.shape[0], 1, X_test.shape[1]))
# 创建LSTM模型
model = Sequential()
model.add(LSTM(4, input_shape=(1, look_back)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
# 训练模型
model.fit(X_train, y_train, epochs=100, batch_size=1, verbose=2)
# 进行预测
trainPredict = model.predict(X_train)
testPredict = model.predict(X_test)
# 将预测结果反归一化
trainPredict = scaler.inverse_transform(trainPredict)
y_train = scaler.inverse_transform([y_train])
testPredict = scaler.inverse_transform(testPredict)
y_test = scaler.inverse_transform([y_test])
# 计算并打印均方误差
trainScore = np.sqrt(mean_squared_error(y_train[0], trainPredict[:, 0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = np.sqrt(mean_squared_error(y_test[0], testPredict[:, 0]))
print('Test Score: %.2f RMSE' % (testScore))
# 可视化预测结果
trainPredict = trainPredict.reshape(trainPredict.shape[0])
y_train = y_train.reshape(y_train.shape[0])
testPredict = testPredict.reshape(testPredict.shape[0])
y_test = y_test.reshape(y_test.shape[0])
plt.figure(figsize=(10, 5))
plt.plot(y_test, color='red', label='Real Gaokao Score')
plt.plot(testPredict,