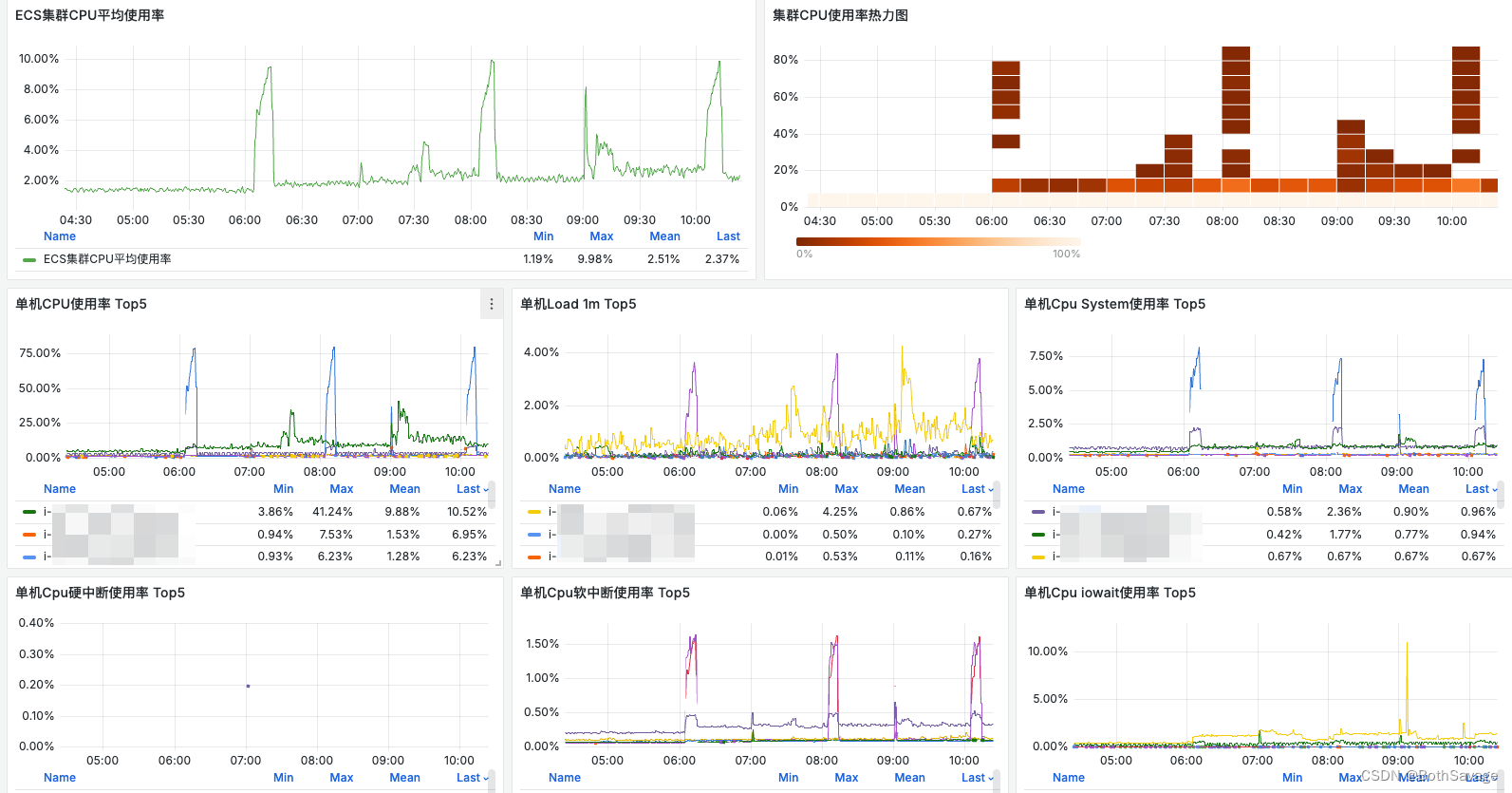
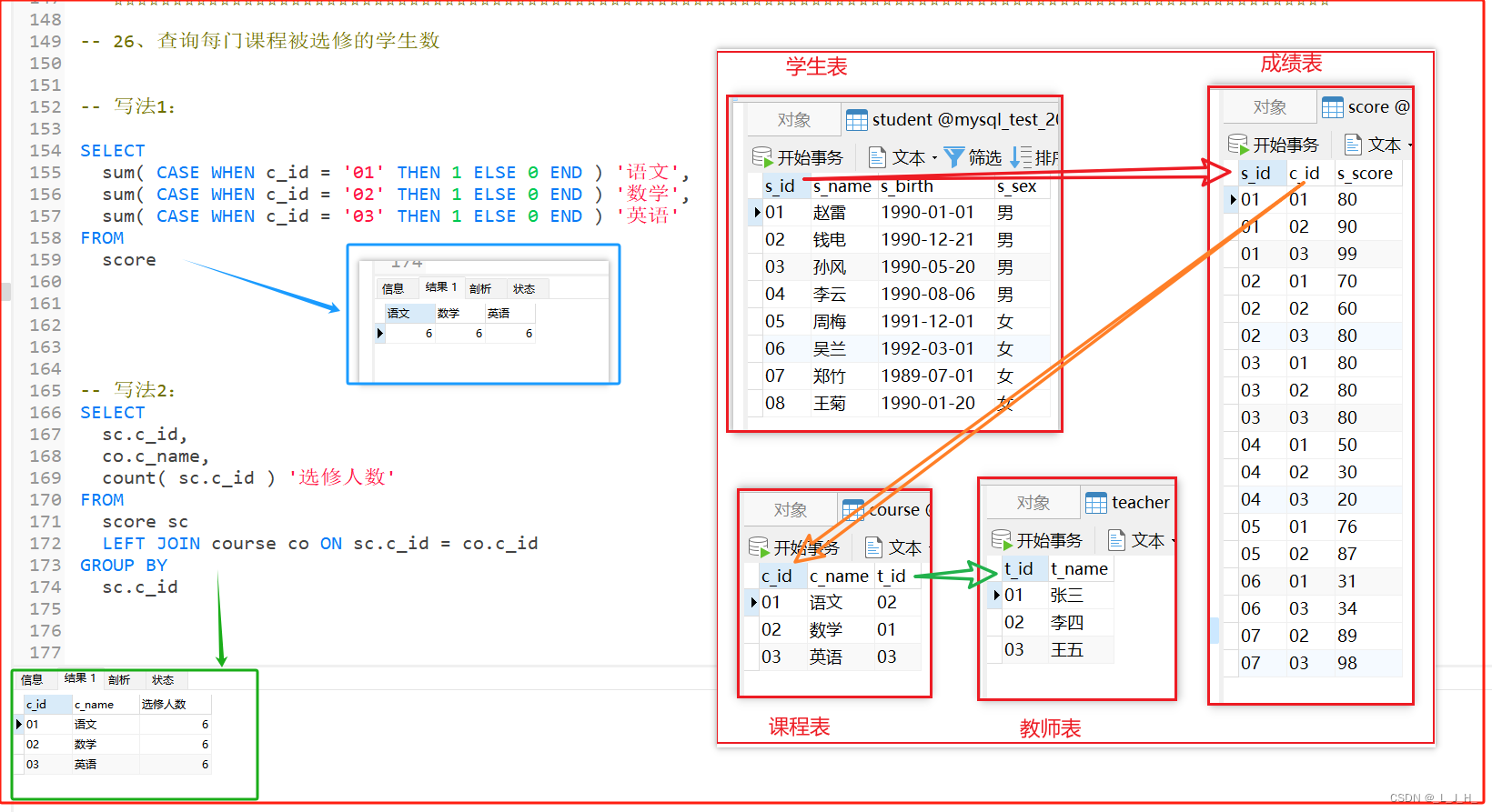
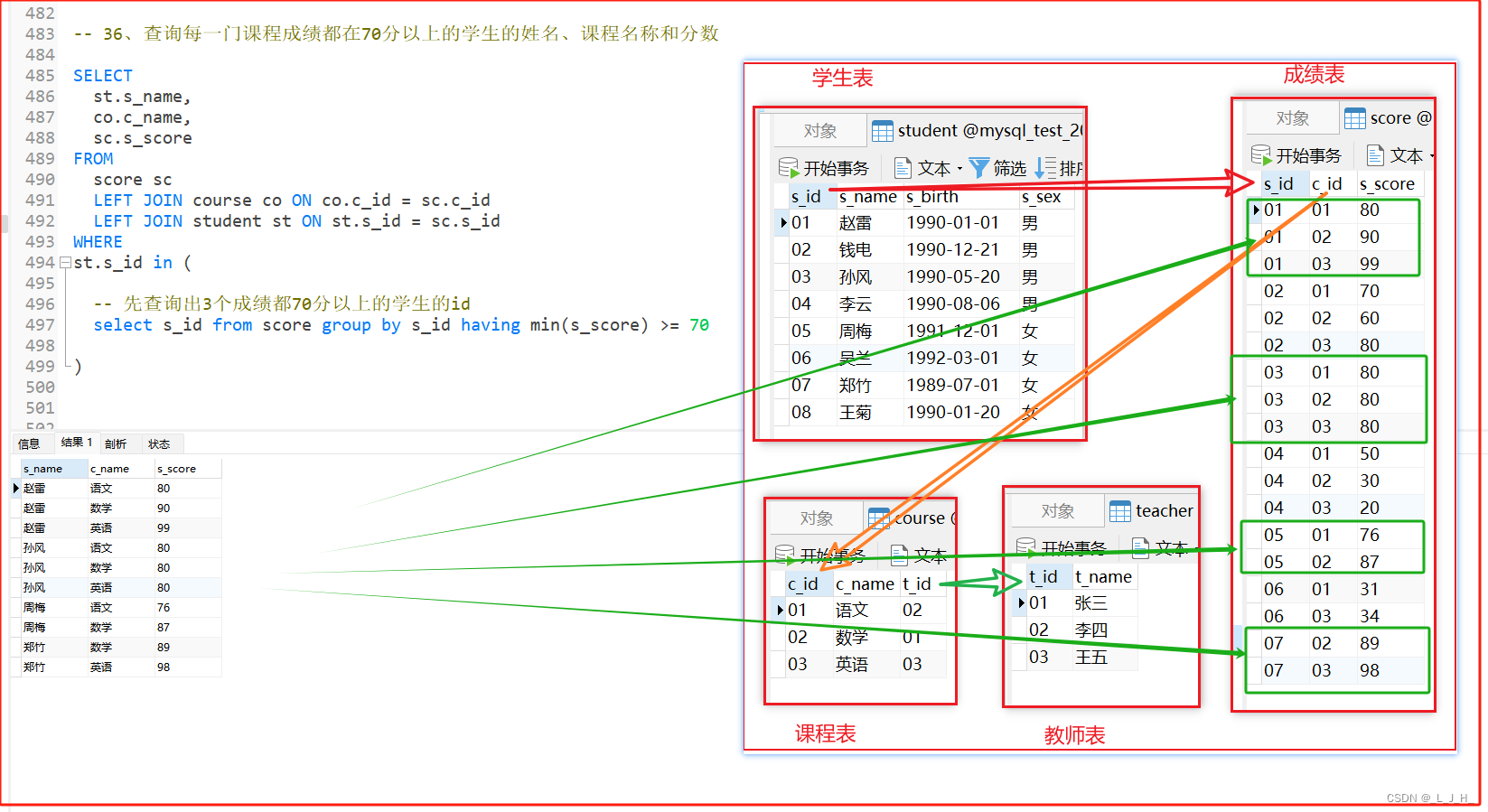
具体需求为:mysql有一个表model_cluster_info, 字段包括id, city_code, household等,现要求按city_code分组并排序,返回在相同city_code下households特定排名的记录(如60%)
mysql5.7,我用用户自定义变量实现了:
SET @rank_row_num = 0, @prev_city_code = NULL;
SELECT t1.city_code as cityCode,
t1.myColumn as `value`,
CASE
WHEN t1.rank = t2.target_rank_30 THEN 30
WHEN t1.rank = t2.target_rank_60 THEN 60
END AS percent
FROM (SELECT city_code,
myColumn,
@rank_row_num := IF(@prev_city_code = city_code, @rank_row_num + 1, 1) AS rank,
@prev_city_code := city_code
FROM (
SELECT
city_code, COALESCE (${columnName}, 0) AS myColumn
FROM
model_cluster_info
ORDER BY
city_code, myColumn desc
) AS sorted_data) AS t1
JOIN (SELECT city_code,
FLOOR(0.3 * total_count) + 1 AS target_rank_30,
FLOOR(0.6 * total_count) + 1 AS target_rank_60
FROM (SELECT city_code,
COUNT(*) AS total_count
FROM model_cluster_info
GROUP BY city_code) AS city_totals) AS t2 ON t1.city_code = t2.city_code
WHERE t1.rank = t2.target_rank_30
OR t1.rank = t2.target_rank_60;
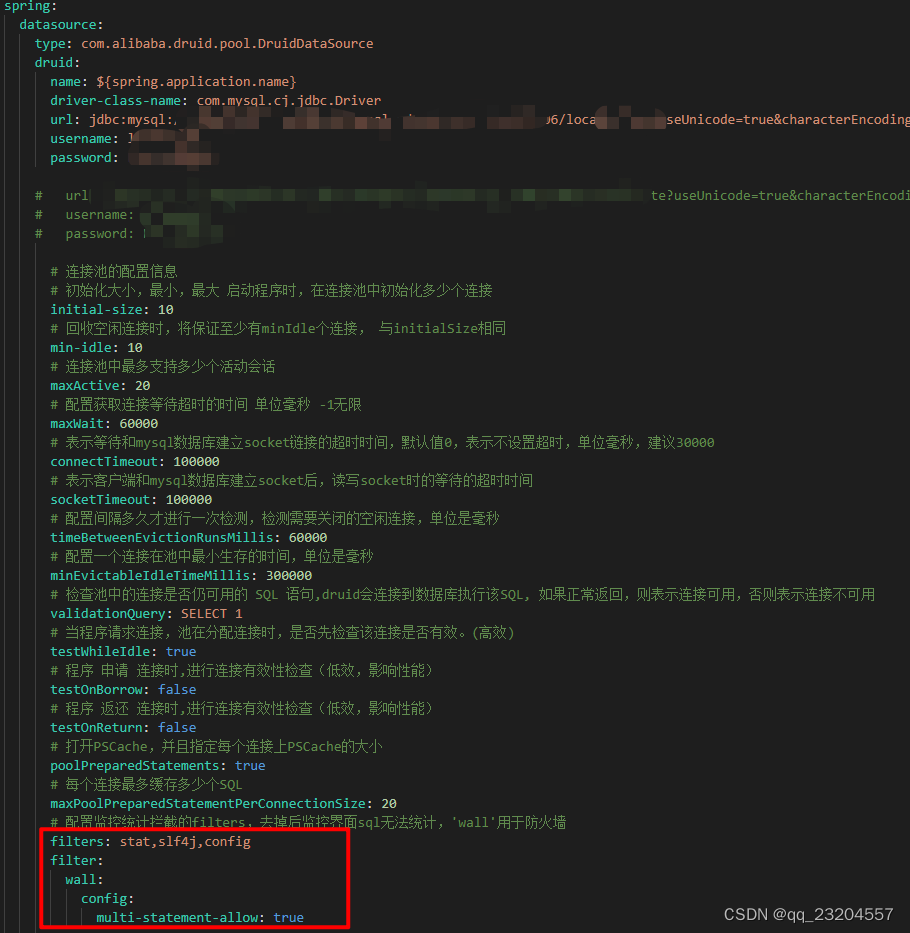
但是应该是会报错Cause: java.sql.SQLException: sql injection violation, dbType mysql, druid-version 1.2.16, “multi-statement not allow : SET”… 。需要改spring.datasource.druid的设置filter.wall.config.multi-statement-allow:
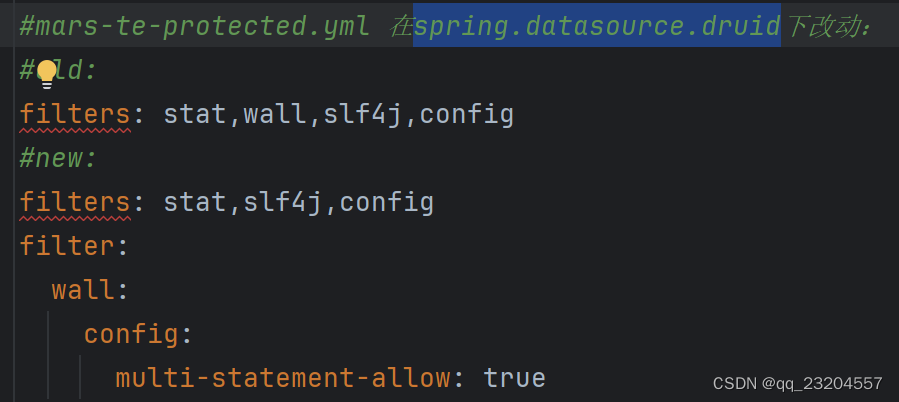
设置完成后:
mysql8.0
但是上述代码在预演、生产环境下跑不通,应该是这两环境是mysql8.0的缘故。所以我为mysql8.0用窗口函数实现如下。而这语法却也是mysql5.7不支持的。
WITH ranked_data AS (SELECT city_code,
COALESCE(${columnName}, 0) as value_adjusted,
ROW_NUMBER() OVER (PARTITION BY city_code ORDER BY COALESCE(${columnName}, 0) DESC) as row_number_within_group, COUNT(*) OVER (PARTITION BY city_code) as total_rows_in_group
FROM model_cluster_info)
SELECT city_code AS cityCode,
value_adjusted AS `value`,
CASE
WHEN row_number_within_group = CEIL(total_rows_in_group * 0.6) THEN 60
WHEN row_number_within_group = CEIL(total_rows_in_group * 0.3) THEN 30
END AS percent
FROM ranked_data
WHERE row_number_within_group = CEIL(total_rows_in_group * 0.6)
OR row_number_within_group = CEIL(total_rows_in_group * 0.3)
其它解法
以下方法就是依靠最基础的联表及分组查询,在mysql5.7、8.0都可以,但是更慢。而偏偏生产环境的是个数据上百万的大表。
select * from (
SELECT g1.id
, g1.city_code
, g1.households
, COUNT(*) AS rank
FROM model_cluster_info AS g1
JOIN model_cluster_info AS g2
ON g1.city_code = g2.city_code
AND g2.households >= g1.households
GROUP BY g1.id
) T where rank = 30





















![[游戏陪玩系统] 陪玩软件APP小程序H5游戏陪玩成品软件源码-线上线下可爆改家政,整理师等功能](https://img-blog.csdnimg.cn/direct/cae2fac7a652406d87f95b049067c3c4.png)