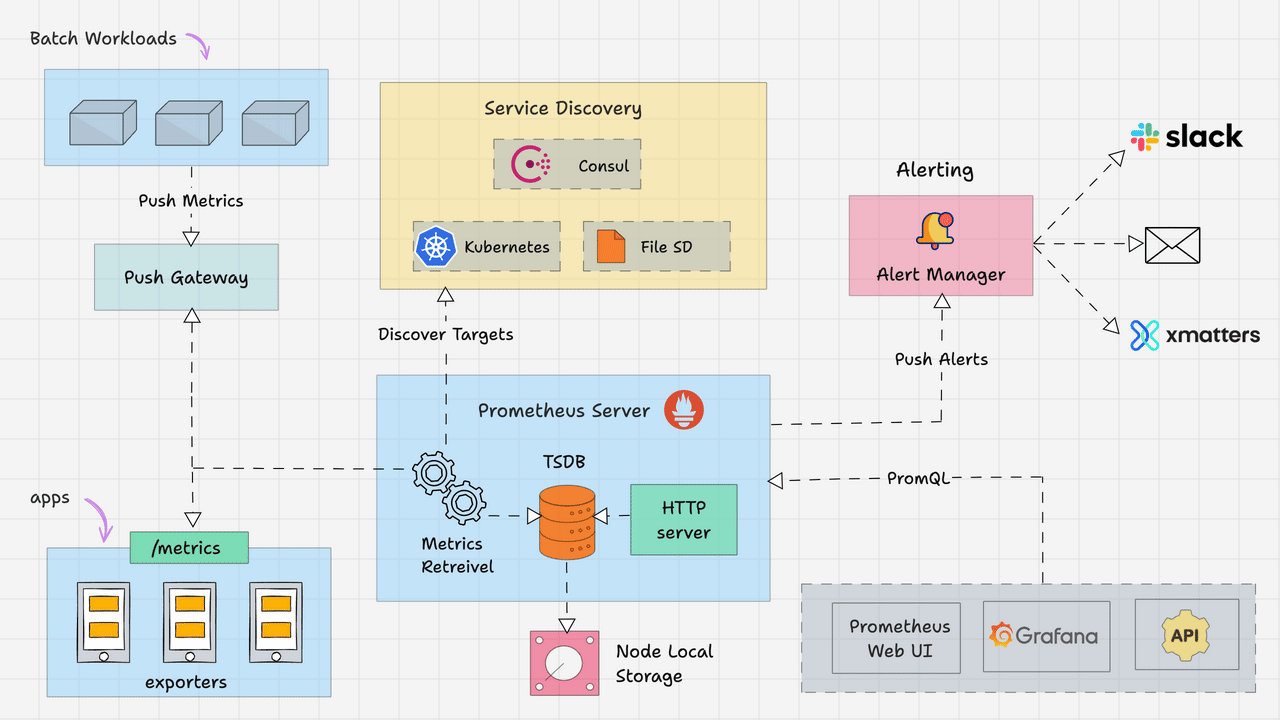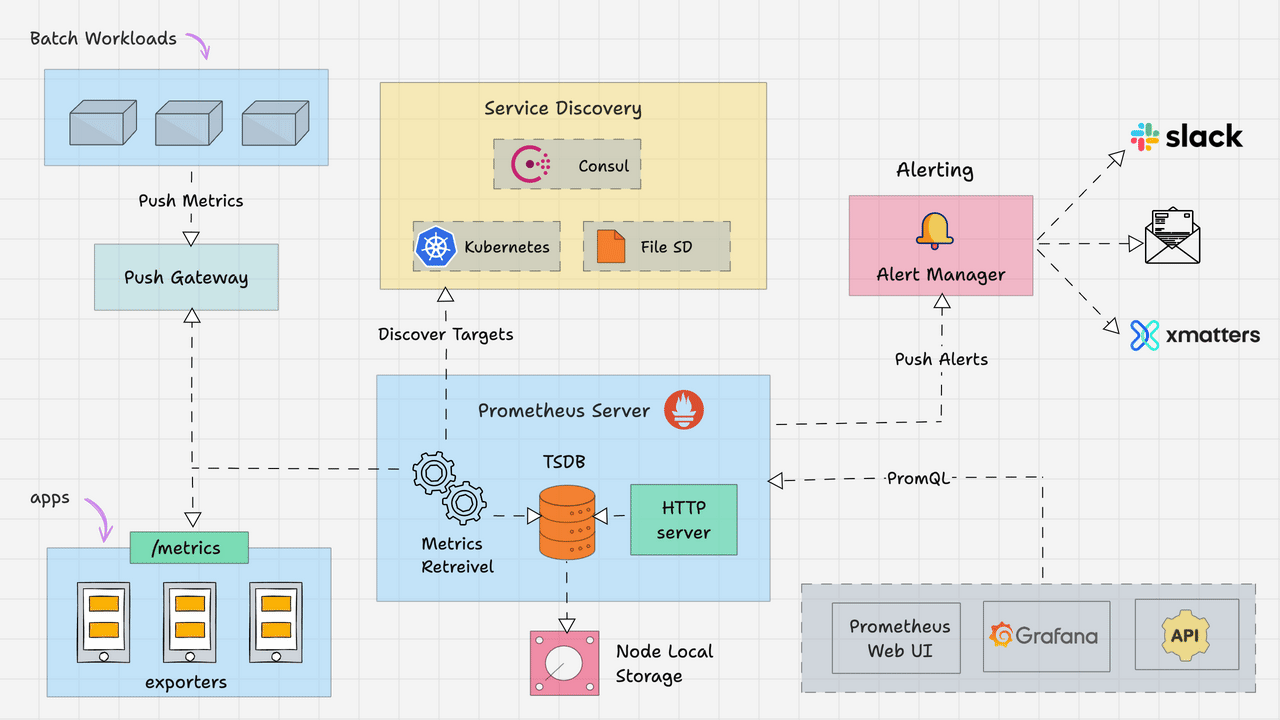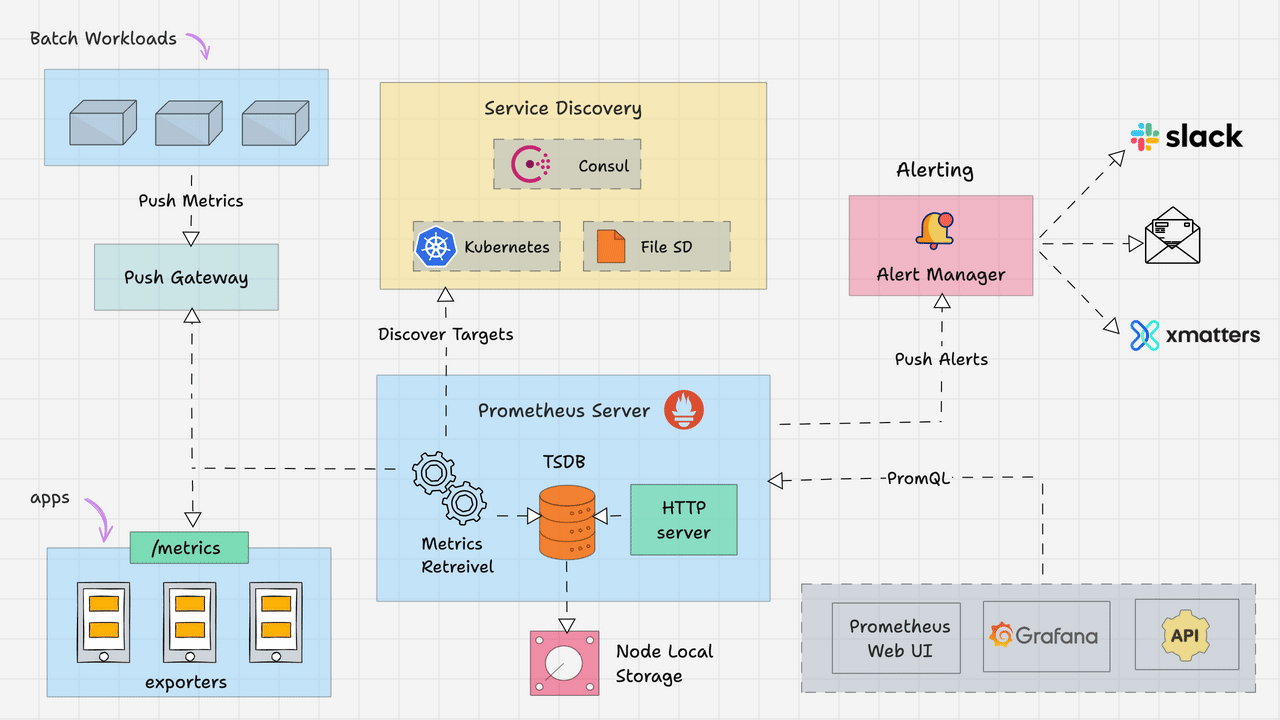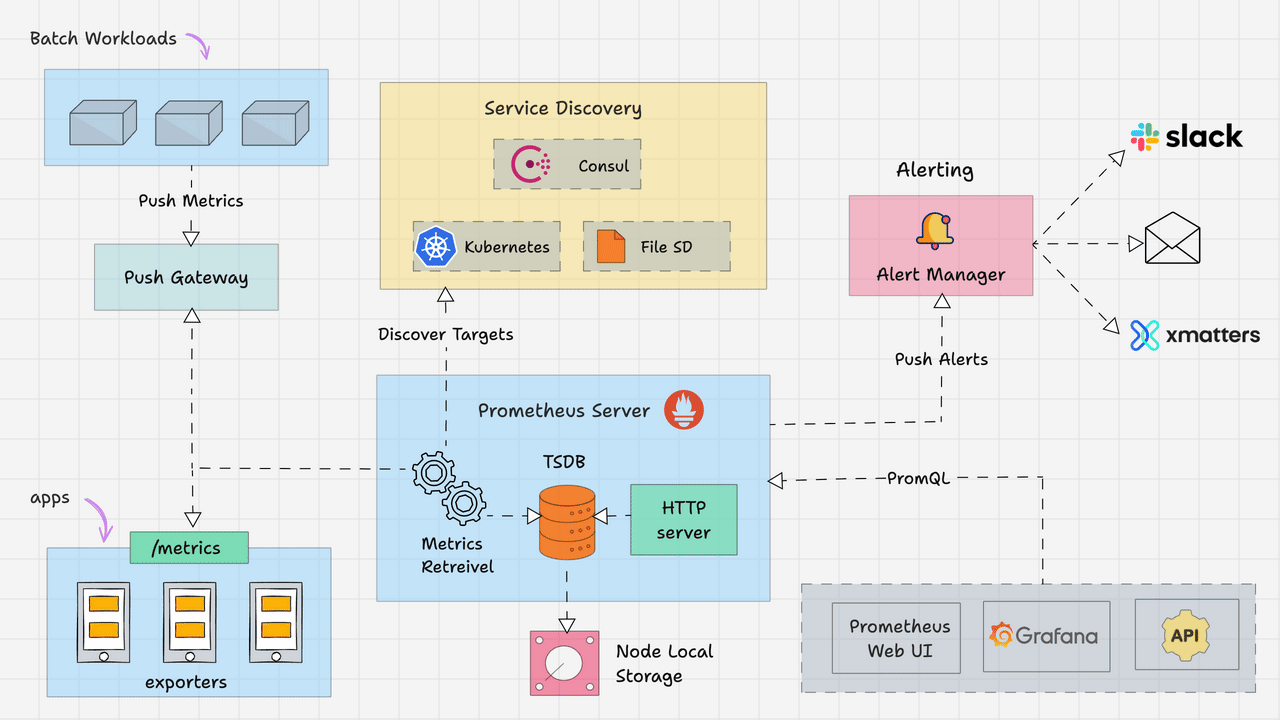
Elasticsearch提供了丰富的内置分析器,以满足不同场景下的文本分析需求。本文将详细介绍几个核心的内置分析器,包括它们的工作原理和使用示例,帮助开发者更好地理解如何在索引和搜索过程中应用这些分析器。
1. Standard Analyzer(标准分析器)
标准分析器是最常用的分析器之一,它基于Unicode文本分割算法切分单词,同时删除大部分标点符号,并将所有单词转为小写形式,以实现标准化处理。此外,标准分析器还支持过滤停用词列表中的词汇,进一步优化索引内容。
示例
POST _analyze
{
"analyzer": "standard",
"text": "The 2019头条新闻 has spread out。"
}
{
"tokens" : [
{
"token" : "the",
"start_offset" : 0,
"end_offset" : 3,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "2019",
"start_offset" : 4,
"end_offset" : 8,
"type" : "<NUM>",
"position" : 1
},
{
"token" : "头",
"start_offset" : 8,
"end_offset" : 9,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "条",
"start_offset" : 9,
"end_offset" : 10,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "新",
"start_offset" : 10,
"end_offset" : 11,
"type" : "<IDEOGRAPHIC>",
"position" : 4
},
{
"token" : "闻",
"start_offset" : 11,
"end_offset" : 12,
"type" : "<IDEOGRAPHIC>",
"position" : 5
},
{
"token" : "has",
"start_offset" : 13,
"end_offset" : 16,
"type" : "<ALPHANUM>",
"position" : 6
},
{
"token" : "spread",
"start_offset" : 17,
"end_offset" : 23,
"type" : "<ALPHANUM>",
"position" : 7
},
{
"token" : "out",
"start_offset" : 24,
"end_offset" : 27,
"type" : "<ALPHANUM>",
"position" : 8
}
]
}
2. Simple Analyzer(简单分析器)
简单分析器在非字母字符处进行切分,并将所有字符转为小写。与标准分析器相比,它更加“简单粗暴”,不保留任何非字母字符,适用于那些需要快速分割且不关心标点符号和数字的场景。
示例
POST _analyze
{
"analyzer": "simple",
"text": "The 2019头条新闻 hasn’t spread out。"
}
{
"tokens" : [
{
"token" : "the",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 0
},
{
"token" : "头条新闻",
"start_offset" : 8,
"end_offset" : 12,
"type" : "word",
"position" : 1
},
{
"token" : "hasn",
"start_offset" : 13,
"end_offset" : 17,
"type" : "word",
"position" : 2
},
{
"token" : "t",
"start_offset" : 18,
"end_offset" : 19,
"type" : "word",
"position" : 3
},
{
"token" : "spread",
"start_offset" : 20,
"end_offset" : 26,
"type" : "word",
"position" : 4
},
{
"token" : "out",
"start_offset" : 27,
"end_offset" : 30,
"type" : "word",
"position" : 5
}
]
}
3. Whitespace Analyzer(空格分析器)
空格分析器以空格作为分隔符来切分文本,保留文本中所有的字符,包括数字、标点符号等,适合于需要精确控制分词边界的场景。
示例
POST _analyze
{
"analyzer": "whitespace",
"text": "The 2019头条新闻hasn’t spread out。"
}
{
"tokens" : [
{
"token" : "The",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 0
},
{
"token" : "2019头条新闻hasn’t",
"start_offset" : 4,
"end_offset" : 18,
"type" : "word",
"position" : 1
},
{
"token" : "spread",
"start_offset" : 19,
"end_offset" : 25,
"type" : "word",
"position" : 2
},
{
"token" : "out。",
"start_offset" : 26,
"end_offset" : 30,
"type" : "word",
"position" : 3
}
]
}
4. Stop Analyzer(停用词分析器)
停用词分析器在简单分析器的基础上增加了停用词过滤功能,移除了英语中最常见的非实质意义词汇(如“a”,“the”,“is”等),适用于希望进一步减少噪声、提高索引效率的情况。
示例
POST _analyze
{
"analyzer": "stop",
"text": "The quick brown fox jumps over the lazy dog."
}
{
"tokens" : [
{
"token" : "quick",
"start_offset" : 4,
"end_offset" : 9,
"type" : "word",
"position" : 1
},
{
"token" : "brown",
"start_offset" : 10,
"end_offset" : 15,
"type" : "word",
"position" : 2
},
{
"token" : "fox",
"start_offset" : 16,
"end_offset" : 19,
"type" : "word",
"position" : 3
},
{
"token" : "jumps",
"start_offset" : 20,
"end_offset" : 25,
"type" : "word",
"position" : 4
},
{
"token" : "over",
"start_offset" : 26,
"end_offset" : 30,
"type" : "word",
"position" : 5
},
{
"token" : "lazy",
"start_offset" : 35,
"end_offset" : 39,
"type" : "word",
"position" : 7
},
{
"token" : "dog",
"start_offset" : 40,
"end_offset" : 43,
"type" : "word",
"position" : 8
}
]
}
5. Keyword Analyzer(关键字分析器)
关键字分析器不对文本进行任何切分,而是将整个文本作为一个不可分割的整体(token)处理。适用于索引那些不应被拆分的字符串,如电子邮件地址、主机名等。
示例
POST _analyze
{
"analyzer": "keyword",
"text": "ContactUs@example.com"
}
{
"tokens" : [
{
"token" : "ContactUs@example.com",
"start_offset" : 0,
"end_offset" : 21,
"type" : "word",
"position" : 0
}
]
}
6. Pattern Analyzer(模式分析器)
模式分析器允许使用正则表达式来定义文本的分割规则,同时支持小写转换和停用词过滤,为文本分析提供了高度的定制性。
示例
POST _analyze
{
"analyzer": "pattern",
"text": "2023-04-01 Release Notes",
"pattern": "\\d{4}-\\d{2}-\\d{2} | [A-Za-z]+"
}
7. Language Analyzers(语言分析器)
Elasticsearch内置了一系列针对特定语言的分析器,如english、chinese等,它们能够根据相应语言的特点进行文本分析,包括正确处理词形变化、停用词等,适合多语言环境下的索引构建。
示例(中文)
POST _analyze
{
"analyzer": "ik_max_word",
"text": " ElasticSearch是一个开源的分布式全文搜索引擎。"
}
{
"tokens" : [
{
"token" : "elasticsearch",
"start_offset" : 1,
"end_offset" : 14,
"type" : "ENGLISH",
"position" : 0
},
{
"token" : "是",
"start_offset" : 14,
"end_offset" : 15,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "一个",
"start_offset" : 15,
"end_offset" : 17,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "一",
"start_offset" : 15,
"end_offset" : 16,
"type" : "TYPE_CNUM",
"position" : 3
},
{
"token" : "个",
"start_offset" : 16,
"end_offset" : 17,
"type" : "COUNT",
"position" : 4
},
{
"token" : "开源",
"start_offset" : 17,
"end_offset" : 19,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "的",
"start_offset" : 19,
"end_offset" : 20,
"type" : "CN_CHAR",
"position" : 6
},
{
"token" : "分布式",
"start_offset" : 20,
"end_offset" : 23,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "分布",
"start_offset" : 20,
"end_offset" : 22,
"type" : "CN_WORD",
"position" : 8
},
{
"token" : "式",
"start_offset" : 22,
"end_offset" : 23,
"type" : "CN_CHAR",
"position" : 9
},
{
"token" : "全文",
"start_offset" : 23,
"end_offset" : 25,
"type" : "CN_WORD",
"position" : 10
},
{
"token" : "搜索引擎",
"start_offset" : 25,
"end_offset" : 29,
"type" : "CN_WORD",
"position" : 11
},
{
"token" : "搜索",
"start_offset" : 25,
"end_offset" : 27,
"type" : "CN_WORD",
"position" : 12
},
{
"token" : "索引",
"start_offset" : 26,
"end_offset" : 28,
"type" : "CN_WORD",
"position" : 13
},
{
"token" : "引擎",
"start_offset" : 27,
"end_offset" : 29,
"type" : "CN_WORD",
"position" : 14
}
]
}
8. Fingerprint Analyzer(指纹分析器)
指纹分析器通过一种特殊算法生成文本的“指纹”,它会将文本转为小写,删除扩展词和重复词,并将每个分词按字典序排序输出,常用于生成唯一标识或简化文本比较。
示例
POST _analyze
{
"analyzer": "fingerprint",
"text": "This is a test sentence with duplicate words."
}
{
"tokens" : [
{
"token" : "a duplicate is sentence test this with words",
"start_offset" : 0,
"end_offset" : 45,
"type" : "fingerprint",
"position" : 0
}
]
}
通过合理选择和配置这些内置分析器,开发者可以高效地处理各种文本数据,优化搜索性能和结果的相关性。