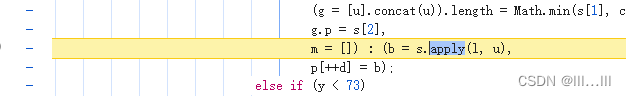前言
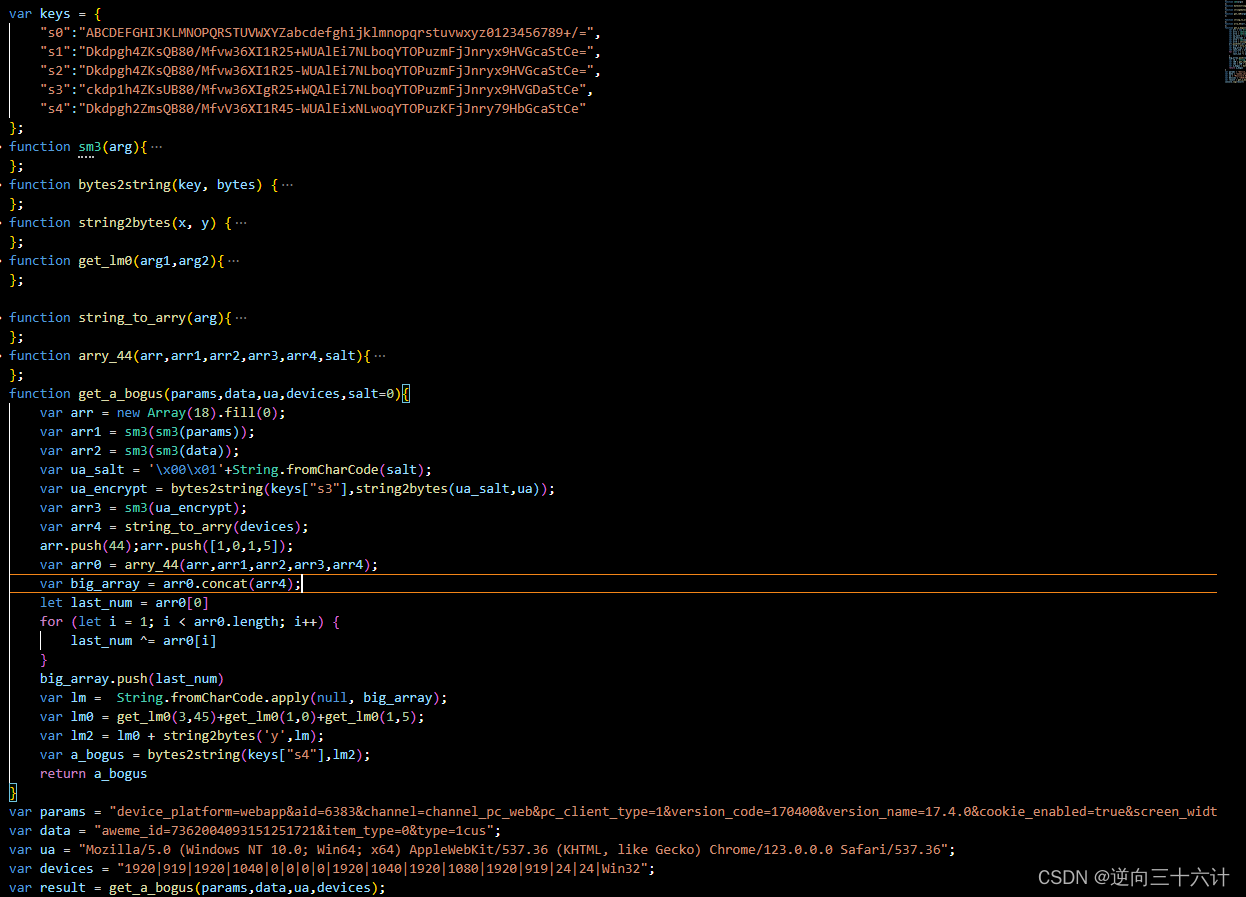
最新版本的a_bogus生成步骤大致分为以下4步:
| 步骤 | 操作 |
|---|---|
| 一 | 根据请求的params、data、useragent以及环境参数生成四个数组 |
| 二 | 通过一些规则把步骤一生成的四个数组组合成一个大数组 |
| 三 | 通过一些随机数生成一个乱码字符串1,根据步骤二生成的大数组生成一个乱码字符串2,把乱码字符串1和乱码字符串2拼接成一个字符串并再次进行处理生成最终的乱码字符串。 |
| 四 | 根据最终的乱码字符串生成a_bogus |
log插桩
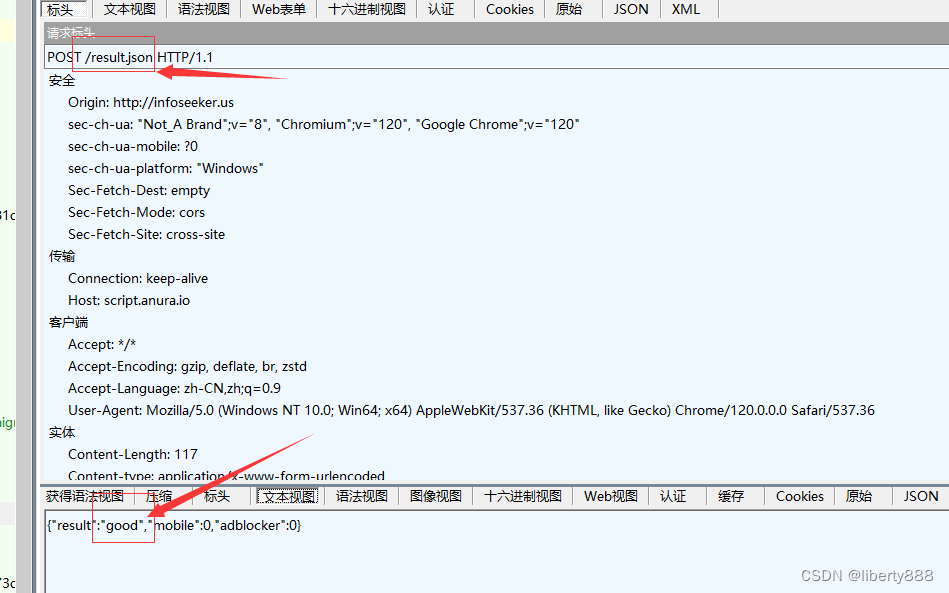
添加合适的日志断点a_bogus的逆向基本上就成功一半了,a_bogus的逆向大部分依赖日志分析,只有步骤三需要动态调试,所以本文的重点会放在打日志断点上,具体的分析逻辑太过繁琐就不细说了。首先打开f12,在页面进行点赞操作,然后找到点赞请求查看调用堆栈,如下图所示:
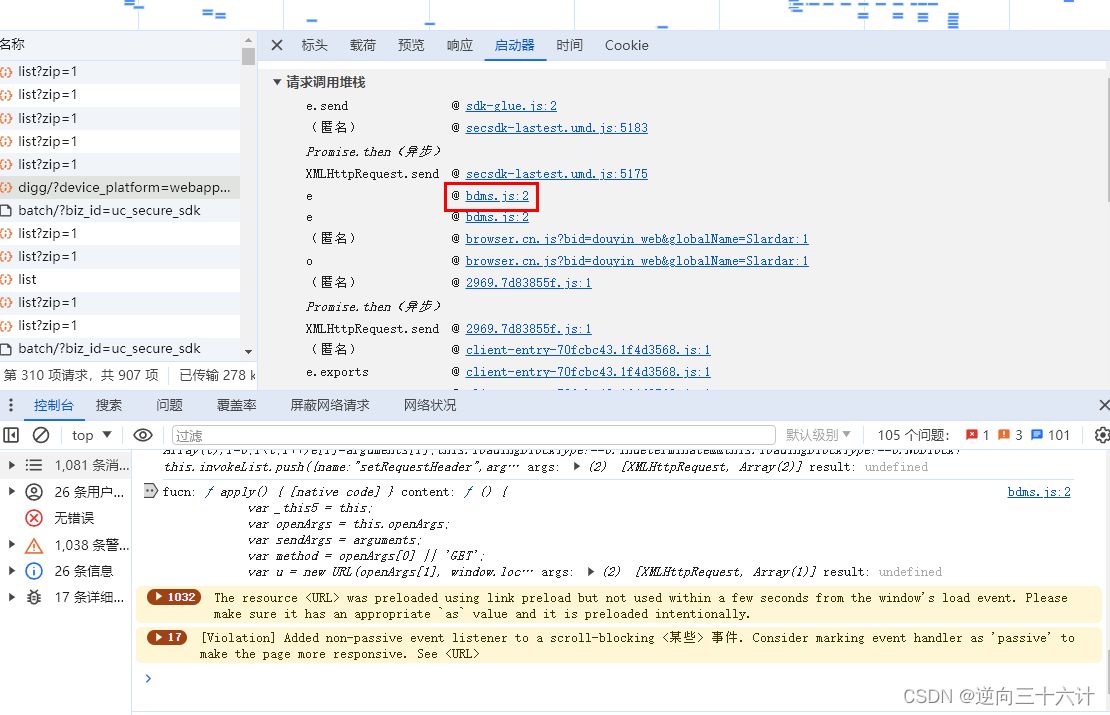
点进标红的位置后来到下图位置,往前翻看代码发现这是一个循环,碰到循环二话不说,先在下图标示位置添加日志断点"fucn:",s,"content:",b,"args:",u,"result:",l,然后清空控制台,再次点击点赞按钮。

找到刚刚点赞的请求,复制a_bogus的值在控制台搜索。

可以看到已经定位到a_bogus生成的日志,红框里面就是生成a_bogus的方法以及传入的参数,args就是l = s.apply(b, u)里面的u,我们可以根据u的值打条件断点,这样做的目的是为了减少一些不必要的日志,我们先回到上面打日志断点的位置打上条件断点typeof u == "object" && u[0]==0 && u[1]==1 && u[3].indexOf("device_platform=webapp")==0 && u[4].indexOf("aweme_id=")==0 && u[5].indexOf("Mozilla/5.0")==0 。
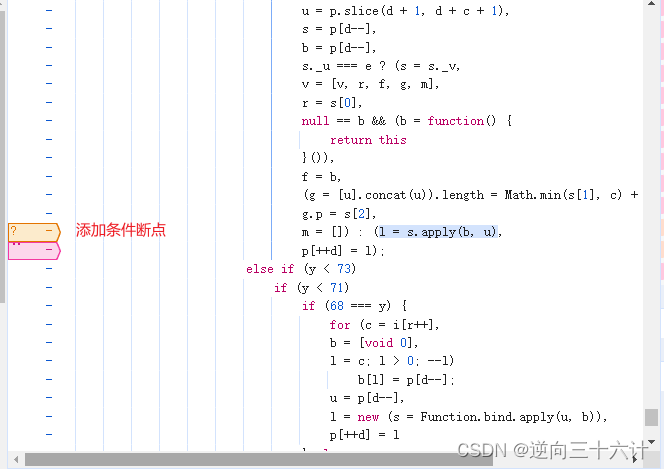
然后回到控制台双击生成a_bogus的方法,我们会发现跳到了另外一个循环里面,往上翻看代码,类似的循环还有很多。

要把所有的apply方法都打上断点有两个方法,第一个方法比较麻烦,就是在bdms.js源码页面搜索“apply”关键字,然后把所有循环里面的apply都打上日志断点,第二个方法是把bdms.js下载到本地,然后修改源码,在头部添加hook Function.prototype.apply,然后
// 保存原始的 Function.prototype.apply 方法
const originalApply = Function.prototype.apply;
// 修改 Function.prototype.apply 方法
Function.prototype.apply = function (thisArg, args) {
// 调用原始的 apply 方法来执行函数
const result = originalApply.call(this, thisArg, args);
// 输出结果
if (window.$_islog) {
try {
console.log("Function:", this, "\n 参数:", args, "\n结果:", JSON.stringify(result));
} catch (e) {
console.log("Function:", this, "\n 参数:", args, "\n结果:", result);
}
}
// 返回结果
return result;
};
第一个方法虽然麻烦,但是不会出什么问题,第二个方法必须要添加一个开关,在前面条件断点的位置的前一行以下代码,
if(typeof u == "object" && u[0]==0 && u[1]==1 && u[3].indexOf("device_platform=webapp")==0 && u[4].indexOf("aweme_id=")==0 && u[5].indexOf("Mozilla/5.0")==0
){
window.$_islog=true
}
在条件断点位置的下一行添加以下代码,
if(window.$_islog=false){
window.$_islog=false
}
这样就能过滤掉没用的日志,否则日志太多会把内存撑爆。
还有一些涉及位运算的关键位置也要打上日志断点,这个没有快捷方法,只能手动找出来。



以上截图只是其中几处,还有一些我就不一一列出来了,鉴于这种情况,我建议使用第一种方法打断点,替换js文件省不了多少事,可能还会出现一些问题。打上这些断点后就可以进行前期的分析了,前期分析完了之后就需要在循环的开头处打断日志断点了,这个断点日志是最多的,所以要放在最后打,如果一开始就打上整个日志会非常的混乱,

断点内容:"索引m", m,"索引r", r, "值p: ", JSON.stringify(p, function(key, value) {if (value == window) {return undefined} return value}), "值v: ", JSON.stringify(v, function(key, value) {if (value == window) {return undefined} return value}), "值l: ", JSON.stringify(l, function(key, value) {if (value == window) {return undefined} return value})
步骤一分析
在还原第一步代码的时候会发现一个数组, [1937774191, 1226093241,388252375,3666478592,2842636476,372324522,3817729613,2969243214]
数组的内容是固定的,随便copy一个数字百度一下就会发现这是SM3密码杂凑算法,params,data都是经过两次SM3加密后生成一个数组,useragent是先转成乱码,乱码经过base64加密(这里不是标准的base64,key改了),把base64解密结果进行SM3加密生成数组。环境参数就是1920|919|1920|1040|0|0|0|0|1920|1040|1920|1080|1920|919|24|24|Win32,这是直接是遍历每个字符转为Unicode编码值,结果放入数组。
步骤二分析
第二步是最麻烦的,params、data、useragent生成的数组都只挑选了几个元素出来,再通过两个时间戳、aid(6383)、6241等进行一些位运算,最终生成一个44位的数组,这一步需要动态调试。44位的数组和环境参数数组拼接成一个大数组,大数组的最后一个元素是44位数组的1-43位跟44进行^运算生成的。
第三步第四步比较简单,通过日志就能还原出来。