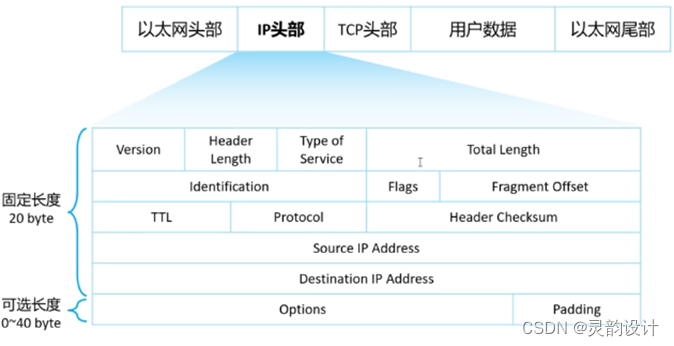
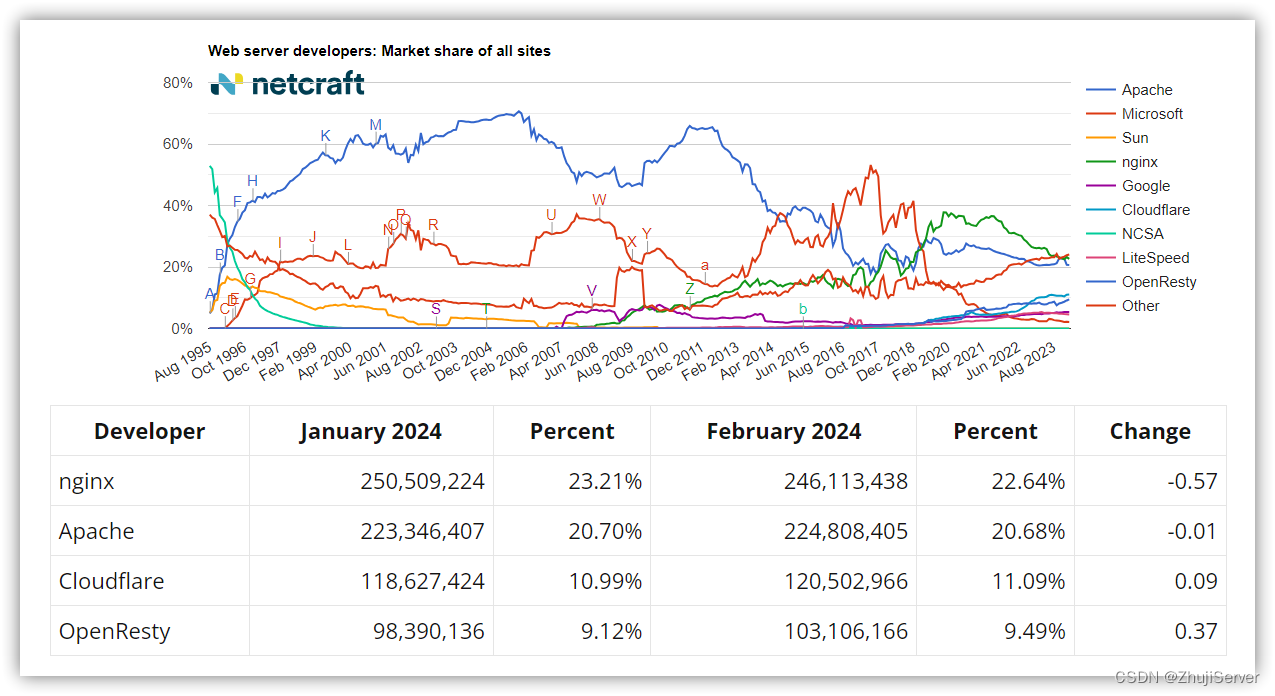
论文地址:IQ-Learn: Inverse soft-Q Learning for Imitation
项目地址:IQ-Learn: Inverse soft-Q Learning for Imitation
一、相关概念:
强化学习(RL):目标是学习一个最大化指定奖励函数的策略。
模仿学习(IL):它不需要仔细手工设计奖励函数,因为它完全依赖于专家行为数据,这使得它更容易扩展到能够收集专家行为(如视频游戏或驾驶)的实际任务。
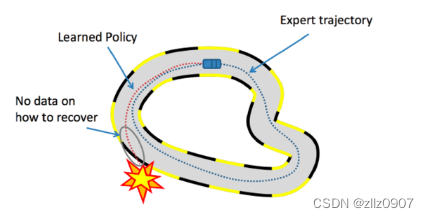
Behavioral Cloning (BC):采用监督学习的方法将环境观察映射到专家行为。
缺点:BC 无法保证模型将推广到看不见的环境观测。当智能体最终处于与任何专家轨迹不同的情况时,BC 容易出现故障。例如,在上图中,如果汽车代理偏离专家轨迹并坠毁,则不知道该怎么办。为了避免犯错误,BC 需要有关环境中所有可能轨迹的专家数据,这使其成为一种数据效率严重低下的方法。
数据集聚合(DAGGER):被提出以交互方式收集更多的专家数据,以从错误中恢复。然而,这需要一个人参与其中,而这种与专家的交互式访问通常是不可行的。相反,我们想模仿人类用来修复错误的试错过程。在上面的例子中,如果汽车可以与环境交互学习“如果我这样做,那么我就会崩溃”,那么它可以自我纠正以避免这种行为。
逆强化学习(IRL):将模仿学习表述为从专家数据中学习奖励函数的问题,使得通过环境交互优化奖励的策略与专家匹配,与强化学习问题相反。
二、基于IRL的模仿学习如何工作?
2016 年,Ho 和 Ermon 将逆强化学习作为两个 AI 模型之间的最小最大值博弈(minimax game),与 GAN生成模型相似。在这种形式中,智能体策略模型(generator)生成与环境交互的行为,以使用 RL 从奖励模型中获得最高奖励,而奖励模型(“鉴别器discriminator”)试图将智能体策略行为与专家行为区分开来。与 GAN 类似,鉴别器充当奖励模型,指示操作的专家程度。
因此,如果策略做了一些不像专家的事情,它就会从鉴别器那里得到低回报,并学会纠正这种行为。这个 minimax 游戏有一个独特的平衡解,称为鞍点解(由于优化的几何鞍形)。在均衡状态下,鉴别器学习奖励,使得基于该奖励的政策行为趋向专家行为。通过对策略和鉴别器的这种对抗性学习,可以使用很少的演示来达到专家的表现。受这种启发的技术被称为对抗性模仿(Adversarial Imitation)。
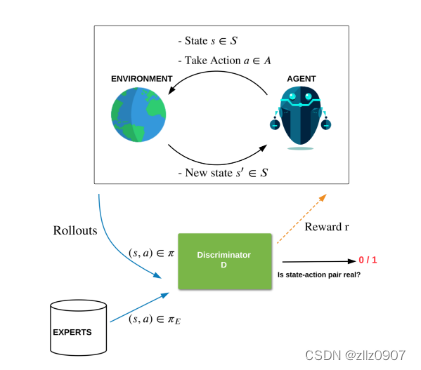
设置对抗性模仿学习,智能体和鉴别器玩最小最大值游戏。鉴别器学习区分策略和专家行为,根据行为的专家程度给予奖励,而智能体使用鉴别器奖励来学习策略,以产生更像专家的行为。
不幸的是,由于对抗性模仿是基于 GAN 的,因此它受到同样的限制,例如模式崩溃(mode collapse)和训练不稳定,因此训练需要仔细的超参数调整和梯度惩罚等技巧。此外,强化学习的过程使训练变得复杂,因为不可能通过简单的梯度下降来训练生成器。GAN和RL的这种融合形成了一种非常脆弱的组合,这在像Atari这样基于图像的复杂环境中效果不佳。由于这些挑战,行为克隆仍然是最普遍的模仿方法。
三、Learning Q-functions for Imitation
这是一种非对抗性模仿方法,学习Q函数来恢复专家行为。
在 RL 中,Q 函数测量智能体从当前状态开始并选择特定操作可以获得的未来奖励的预期总和。通过使用神经网络学习 Q 函数,该神经网络将智能体的当前状态和潜在动作作为输入,可以预测智能体获得的总体预期未来奖励。由于预测的是总体奖励,而不仅仅是采取这一步的奖励,因此确定最优策略非常简单,只需在当前状态下依次采取预测 Q 函数值最高的行动即可。这种最优策略可以表示为 Q 函数在给定状态下所有可能行动的 argmax。因此,Q 函数是一个非常有用的量,它提供了环境中奖励函数和最优行为策略之间的联系。
在 IL 中,由于以往方法存在上述问题,简单、稳定、数据高效的方法一直遥不可及。此外,对抗性方法的不稳定性也使得逆 RL 计算难以解决。对 IL 采用非对抗方法可能会解决该领域面临的许多难题。在 RL 中,Q 函数可以从奖励函数中确定最佳行为策略,它的显著成功是否值得 IL 借鉴?
四、Inverse Q-Learning (IQ-Learn)

逆 Q 学习(IQ-Learn)算法直接从专家行为数据中学习 Q 函数。我们的主要见解是,Q 函数不仅可以代表最优行为策略,而且还可以代表奖励函数,因为对于给定策略而言,从单步奖励到 Q 函数的映射是双射(既是单射又是满射)的。这就避免了逆向模仿公式中对政策和奖励函数进行困难的最小博弈,只需用一个变量(Q 函数)来表示这两个函数。将这一变量变化插入原始的逆向 RL 目标中,就会产生一个更简单的、只涉及单一 Q 函数的最小化问题;我们将其称为逆向 Q-learning 问题。我们的逆 Q-learning 问题与对抗 IL 的 minimax 游戏有着一一对应的关系,因为每个潜在的 Q 函数都可以映射到一对判别器和生成器网络。这意味着我们既保持了 IRL 的通用性和唯一均衡特性,又产生了一种可用于模仿的简单非对抗算法。
为了直观地理解我们的方法,下面是一种可视化方法--现有的 IRL 方法解决的是一个涉及策略(π) 和奖励 (r) 的最小博弈(minimax game)问题,通过利用 RL(如左图所示),在唯一的鞍点(saddle point solution)(π∗, r∗)上找到与专家行为相匹配的政策。IQ-Learn 提出了一个从奖励到 Q 函数的简单转换,从而通过策略 (π) 和 Q 函数 (Q) 来解决这个问题,找到相应的解 (π∗, Q∗)(如右图所示)。现在最重要的是,如果我们知道了 Q 函数,那么我们就明确知道了它的最优策略:这个最优策略就是简单地选择在给定状态下能使 Q 函数最大化的(softmax)行动。因此,IQ-Learn 不需要 RL 来寻找策略!
现在,我们不需要在所有可能的奖励和策略空间中进行优化,而只需要沿着该空间中与 Q 函数及其最优策略的选择(红线)相对应的流形进行优化。沿着流形 J∗ 的新目标是凹形的,且只取决于 Q 函数变量,因此可以使用简单的梯度下降方法找到唯一的最优点。

在学习过程中,对于离散的行动空间,IQ-Learn 会优化目标 J∗,在流形上采取与 Q 函数(绿线)相关的梯度步骤,最终收敛到全局最优鞍点。对于连续行动空间,计算精确梯度往往难以实现,因此 IQ-Learn 额外学习了策略网络。它会分别更新 Q 函数(绿线)和策略(蓝线),以保持接近流形。

这种方法非常简单,只需修改更新规则,就能利用专家示范和可选的环境互动来训练 Q 网络。IQ-Learn 更新是一种对比学习形式,其中专家行为的奖励较高,而政策行为的奖励较低;奖励的参数使用 Q 函数。在离散行动空间的现有 Q-learning 算法和连续行动空间的soft actor-critic (SAC)方法的基础上,只需不到 15 行的代码就能轻松实现。
五、IQ-Learn 优点
- 它使用梯度下降法优化单一训练目标,并为 Q 函数学习单一模型。
- 在数据非常稀少的情况下,甚至在单一专家示范的情况下,它也能表现出色。
- 实施简单,可在两种环境下工作:可访问环境(在线 IL)或不可访问环境(离线 IL)。
- 它可以扩展到复杂的基于图像的环境,并已证明理论上可以收敛到唯一的全局最优。
- 最后,它还可用于恢复奖励,并为策略行为增加可解释性。
尽管这种方法非常简单,但我们惊讶地发现,在 OpenAI Gym、MujoCo 和 Atari 等流行的模仿学习基准测试中,它的表现大大超过了许多现有方法,包括那些更加复杂或针对特定领域的方法。在所有这些基准测试中,IQ-Learn 是唯一一种依靠少量专家示范(少于 10 次)就能成功达到专家级性能的方法。采用简单 LSTM 策略的 IQ-Learn 在复杂的开放世界环境 Minecraft 中也有出人意料的出色表现,它能够从人类玩家的视频中学习解决各种任务,如建造房屋、创建瀑布、笼养动物和寻找洞穴。
我们还尝试在只有部分专家数据可用的情况,或者专家的环境或目标发生了变化的情况下进行模仿,这更接近现实世界。我们能够证明,IQ-Learn 可以在没有专家行动的情况下进行模仿,只依赖专家的观察,从而实现从视频中学习。此外,IQ-Learn 对专家行为和目标在环境中的分布变化具有令人惊讶的鲁棒性,对新的未知环境具有很强的泛化能力,并能充当meta-learner。