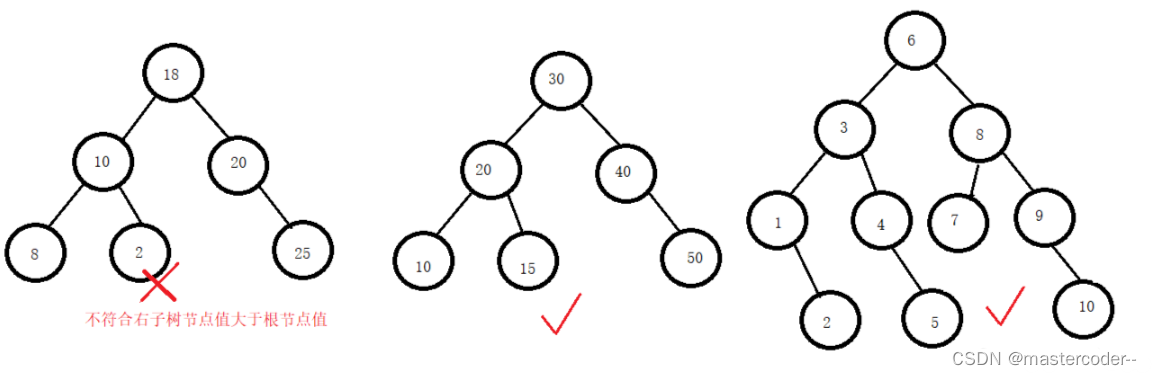
二叉搜索树的概念
二叉树又称二叉排序树(BST,Binary Search Tree),它是一颗空树,也可以是一颗具有下列性质的二叉树:
1.假如它的左子树不为空,那么左子树上的结点值都小于根结点的值。
2.假如它的右子树不为空,那么右子树上的结点值都大于根结点的值。
3.它的左右子树都分别为二叉搜索树
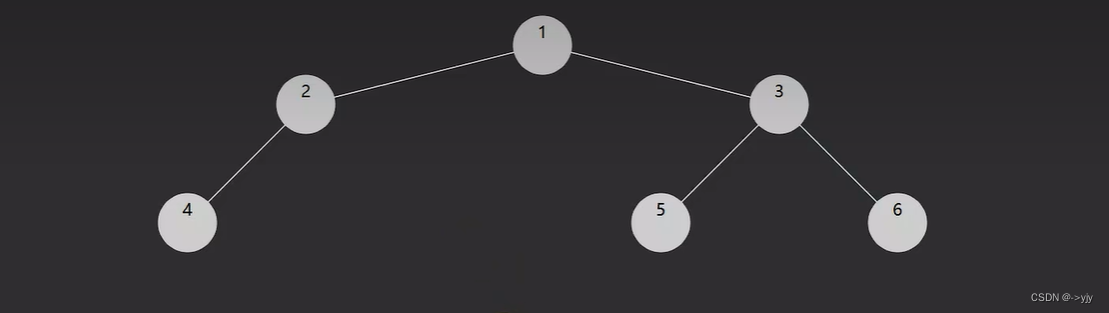
可以看看下图的例子:
再看这颗二叉树搜索树:
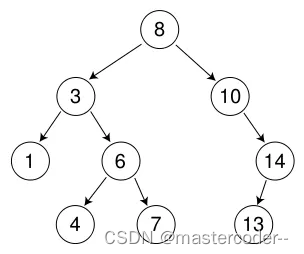
假如我们中序遍历,那么就会得到:
1 3 4 6 7 8 10 13 14可以看到,对二叉树搜索树进行中序遍历,得到的结果为升序序列。
二叉搜索树的实现
结点类
在一整颗树中,当然会有多个结点,那么我们就定义一个结点类,里面包含了结点的值,结点的左指针,结点的右指针。
//结点类
template<class T>
struct TreeNode
{
T _val;//结点值
TreeNode<T>* _left;//左树指针
TreeNode<T>* _right;//右树指针
//构造函数
TreeNode(const T& val = 0)
:_val(val)
, _left(nullptr)
, _right(nullptr)
{}
};二叉搜索类函数要素
在一整颗二叉树搜索树中,我们需要定义一个最初的根结点,假如这颗树为空树,那么我们就令根结点为空,所以我们定义一个成员变量_root作为成员变量。
template<class T>
class FindTree
{
public:
typedef TreeNode<T> node;
//构造函数
FindTree()
//拷贝构造副函数
node* _copy(node* root)
//拷贝构造主函数
FindTree(const FindTree<T>& t)
//赋值运算符重载函数(深拷贝)
FindTree<T>& operator=(FindTree<T> t)
//析构副函数
void _destory(node* root)
//析构主函数
~FindTree()
//插入函数
bool insert(const T& val)
//插入副函数(递归实现)
bool _insertR(node*& root, const T& val)
//插入主函数(递归)
bool insertR(const T& val)
//删除函数
bool erase(const T& val)
//搜索函数
node* find(const T& val)
//搜索副函数(递归)
node* _findR(node* root, const T& val)
//搜索主函数(递归)
node* findR(const T& val)
private:
node* _root;//整个树的根节点
};构造函数
构造函数很简单,只需要令根节点为空就好了,因为一开始啥也没有,是颗空树
typedef TreeNode<T> node;//为了方便命名
//构造函数
FindTree()
:_root(nullptr)//将最初的根结点初始化为空指针
{}
拷贝构造函数
这里有一个很有意思的点,为什么要写一个副函数?
假如我们将所有代码都写在主函数,然后我们在main函数中调用的时候就会出现问题,我们如何将_root传给拷贝构造函数呢?_root是这个类的私有成员,在外部并不能调用,只能在类内进行调用,所以我们写了个主函数,主函数来将_root传给副函数,然后副函数进行操作,然后在外部调用主函数从而完成拷贝构造,这是一个很巧妙的方法。
注意:这里的拷贝构造完成的是深拷贝
//拷贝构造副函数
node* _copy(node* root)
{
if (root == nullptr)
{
return nullptr;//如果为空则返回空
}
node* copynode = new node(root->key);//拷贝根节点
copynode->_left = _copy(root->left);//进入左树递归拷贝
copynode->_right = _copy(root->right);//进入右树递归拷贝
return copynode;//返回拷贝后的树的根结点
}
//拷贝构造主函数
FindTree(const FindTree<T>& t)
{
_root = _copy(t._root);//从根结点进入递归拷贝
}赋值运算符重载函数
这里直接将实参传给形参,然后用形参与左值调用swap函数进行调换,那么此时左值就完成了赋值,然后函数操作完后,形参自动就会析构。
//赋值运算符重载函数(深拷贝)
FindTree<T>& operator=(FindTree<T> t)
{
swap(_root, t._root);
return *this;
}析构函数
这里采用副函数的意义也是和前面一样,为了能够调用到私有成员_root。
注意:这里的释放方式应该采用后序方法,假如先把根结点释放掉了,那么根结点的左指针与右指针都找不到了,就会析构失败,存在内存泄露的风险。
//析构副函数
void _destory(node* root)
{
if (root == nullptr)//空树不需要释放
{
return;
}
_destory(root->_left);//进入左树递归删除
_destory(root->_right);//进入右树递归删除
delete root;//释放根结点
}
//析构主函数
~FindTree()
{
_destory(_root);//从根结点开始释放
_root = nullptr;//将跟节点置空,防止野指针
}插入函数
在前面已经了解到了二叉搜索树的性质,现在我们就可以理解一下插入函数了:
一.如果是空树,那么直接插入结点作为二叉搜索树的根结点。
二.如果不是空树,则按照二叉搜索树的性质进行插入:
1.假如插入的结点值小于根结点的值,那么需要将结点插入到左子树当中。(进入左子树继续搜索)
2.假如插入的结点值大于根结点的值,那么需要将结点插入到右子树当中。(进入右子树继续搜索)
3.假如插入的结点值等于根结点的值,那么就不需要插入了,插入失败。
然后不断循环,直到遇到一的情况,也就是遇到空树即可插入,如果遇到相同的值,那么就插入失败。
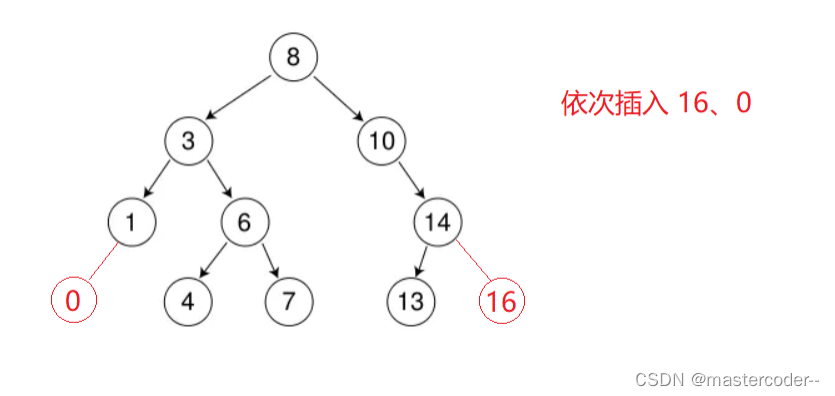
第一种方法是非递归
要先定义一个parent指针和cur指针,parent记录cur的父亲结点,cur记录当前需要对比的结点,因为当我们找到需要插入的节点时,需要连接父亲结点,这时就要用到parent指针了
//插入函数
bool insert(const T& val)
{
if (_root == nullptr)//找到空的地方将值插入
{
_root = new node(val);
return true;
}
node* parent = nullptr;//记录父亲指针
node* cur = _root;//记录当前指针
while (cur)//不为空时候,一直循环查找
{
if (val < cur->_val)//插入的值比结点值小
{
parent = cur;//更新父亲结点
cur = cur->_left;//令当前指针往左走
}
else if (val > cur->key)//插入的值比结点大
{
parent = cur;//更新父亲结点
cur = cur->_right;//令当前指针往右走
}
else//插入的值与结点相同
{
return false;//不需要插入,插入失败
}
}
//当结束循环,说明找到空树,那么可以进行插入
cur = new node(val);
if (val < parent->_val)//插入的值比父亲结点小
{
parent->_left = cur;//往左边插入
}
else//插入的值比父亲结点大
{
parent->_right = cur;//往右边插入
}
return true;//插入成功
}第二种方法是递归法
当插入值比结点值小,那么进入左树递归。
当插入值比结点值大,那么进入右树递归。
直到遇到空树,那么此时就可以直接new一个新结点。
如果遇到相同的值,那么直接返回false结束递归。
这时又会有同学问:为什么这里的是node*& root,为什么不需要对new的结点连接?
首先,node*&的含义是:指针的引用,然后再看我们调用递归的两个函数,每次进入递归,root都是root->_left或者root->_right的指针的引用,所以这时候就可以理解了:此时我们new的结点就是new给root->_left或者root->_right,那么这时候就可以看成root->_left = new或者root->_right = new。
//插入副函数(递归实现)
bool _insertR(node*& root, const T& val)
{
if (root == nullptr)//找到空树,进行插入
{
root = new node(val);
return true;
}
if (val < root->_val)//值比结点小
{
return _insertR(root->_left, val);//进入左树递归
}
else if (val > root->_val)//值比结点大
{
return _inserR(root->_right, val);//进入右树递归
}
else//值与结点相同
{
return false;//不插入
}
}
//插入主函数(递归)
bool insertR(const T& val)
{
return _inserR(_root, val);
}删除函数
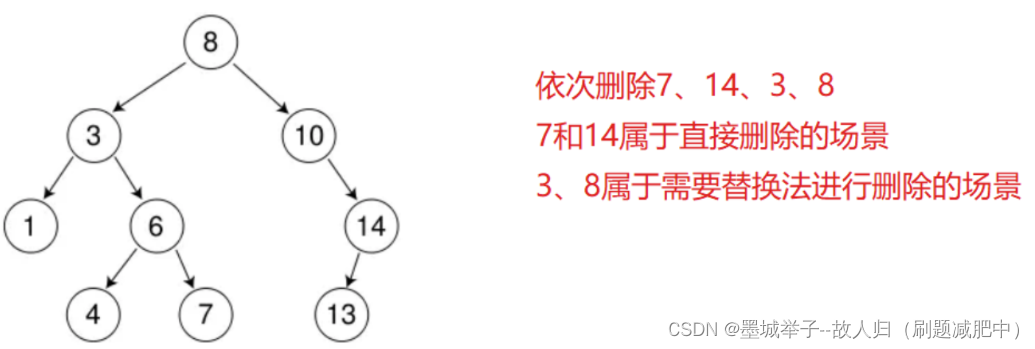
要想删除某个结点,要先考虑删除的情况:
1.要删除的结点没有左右子树。
2.要删除的结点只有左子树。
3.要删除的结点只有右子树。
4.要删除的结点同时有左右子树。
在处理以上四种情况时,我们可以归类成三种,将1归类到2或者归类到3
因为在2情况中,删除后需要将父结点指向结点的左子树。在3情况中,删除后需要将父结点指向结点的右子树,也就是需要继承他们的孩子。那么1情况中,因为左右子树都为空,所以我们将父节点指向左右子树都行。
综上所述,情况分为了三种(去掉1)分析:
1.要删除的结点只有左子树。
先判断要删除的结点到底是父结点的左子树还是右子树,让父结点指向该结点的左子树,后删除该节点,先后顺序不可调换。
2.要删除的结点只有右子树。
先判断要删除的结点到底是父结点的左子树还是右子树,让父结点指向该结点的右子树,后删除该节点,先后顺序不可调换。
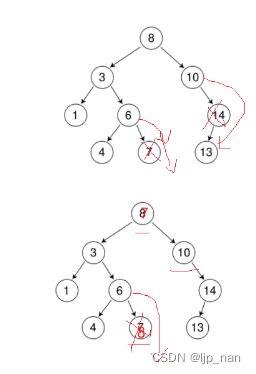
3.要删除的结点同时有左右子树。
同时拥有左右子树很难处理删除后父亲结点的继承问题,因为一个指针不能继承两个结点。这时需要采用替换法,先找到左子树中最大值,或者找到右子树的最小值,然后将两个值替换,然后删除原本中左子树中最大值的结点或者右子树的最小值的结点。
需要注意的是,在1和2的情况下,如果要删除的结点为整颗树的根结点,直接让根结点变成1和2情况下存在的子树根结点即可
在3的情况中,我们还需要定义一个minparent和mincur指针,minparent用来记录寻找左树最大结点的父节点或者寻找右树最小结点的父节点,mincur用来记录记录寻找左树最大的当前结点或者寻找右树最小结点的当前结点。
//删除函数
bool erase(const T& val)
{
node* parent = nullptr;//记录父亲结点
node* cur = _root;//记录当前结点
while (cur)
{
if (val < cur->_val)//值小,更新父亲结点,则左走
{
parent = cur;
cur = cur->_left;
}
else if (val > cur->_val)//值大,更新父亲结点,则右走
{
parent = cur;
cur = cur->_right;
}
else//相同,则找到要删除的结点
{
if (cur->_left == nullptr)//左树为空
{
if (cur == _root)//如果要删除的就是整棵树的根结点
{
_root = cur->_right;//根结点转变成右树
}
else
{
if (cur == parent->_left)//如果当前结点是父结点的左结点
{
parent->_left = cur->_right;
}
else//如果当前结点是父结点的右结点
{
parent->_right = cur->_right;
}
}
delete cur;//删除原结点
return true;
}
else if (cur->_right == nullptr)//右树为空
{
if (cur == _root)//如果要删除的就是整棵树的根结点
{
_root = cur->_left;//根结点转变成右树;
}
else
{
if (cur == parent->_left)//如果当前结点是父结点的左树
{
parent->_left = cur->_right; //父结点的左树指向当前结点的右树
}
else//如果当前结点是父结点的右结点
{
parent->_right = cur->_right;//父结点的右树指向当前结点的右树
}
}
delete cur;//删除原结点
return true;
}
else//如果该结点同时拥有左右子树,可以用替换法删除。1.选取左子树最大的值替换。2.选取右子树最小的值替换
//这里采用2.右子树最小的值进行替换
{
node* minparent = cur;//记录最小结点的父结点
node* mincur = cur->_right;//进入右子树
while (mincur->_left)//如果左子树不为空,一直循环,直到找到最小值
{
minparent = mincur;
mincur = mincur->_left;
}
cur->_val = mincur->_val;//交换要删除的值与找到的最小值结点
if (mincur = minparent->_left)//如果当前指针为父结点的左
{
minparent->_left = mincur->_right;
}
else //如果当前指针为父结点的右,也就是要删除的结点的右结点就是最小的(删除结点的右结点没有左结点)
{
minparent->_right = mincur->_right;
}
delete mincur; //释放最小结点的指针
return true;
}
}
}
return false;
}查找函数
这个函数比较简单,一直通过对比大小进入左或右子树,然后找到相同的就返回地址即可。
第一种方法,非递归
//搜索函数
node* find(const T& val)
{
node* cur = _root;
while (cur)
{
if (val < cur->_val)//比结点小,往左走
{
cur = cur->_left;
}
else if (val > cur->_val)//比结点大,往右走
{
cur = cur->_right;
}
else//相同,找到,返回结点地址
{
return cur;
}
}
}第二种方法,递归
这里为了调用私有成员_root,也是通过主副函数进行操作。
//搜索副函数(递归)
node* _findR(node* root, const T& val)
{
if (root == nullptr)//没找到,返回空指针
{
return nullptr;
}
if (val < root->val)//比结点小。进入左树递归
{
return _findR(root->_left, val);
}
else if (val > root->val)
{
return _findR(root->_right, val);//比结点大,进入右树递归
}
else//相同,返回结点地址
{
return root;
}
}
//搜索主函数(递归)
node* findR(const T& val)
{
return _findR(_root, val);
}二叉搜索树的应用
K模型
K模型即只有ker作为关键码,结构中只需要存储key即可,关键码即为搜索到的值例如:给一个单词word,判断该单词是否拼写正确,具体判断方式如下:
1.以词库中的所有单词分别作为key,构建一颗二叉搜索树。
2.在二叉搜索树中搜索该单词是否存在,存在就正确,不存在就错误。
KV模型
每一个关键码key,都对应着值value,也就是<key,value>键值对
1.例如在英汉词典就是英文与中文的对应关系,通过英文可以快速找到与其对应的中文,英文单词与对应的中文<word,chinese>就构成一种键值对。
2.再例如统计单词次数,统计成功后,给定单词就可以快速找到其对应的次数,单词与其出现的次数<word,count>就是一种键值对。
二叉搜索树的性能分析
在进行插入和删除操作的时候,都需要先查找,查找效率就代表了二叉搜索树中各个操作的性能。
例如,对有n个结点的二叉搜索树,假如每个元素查找的概率相同,那么二叉搜索树平均查找长度是结点在二叉搜索树的深度的函数,也就是结点越深,比较次数越多。
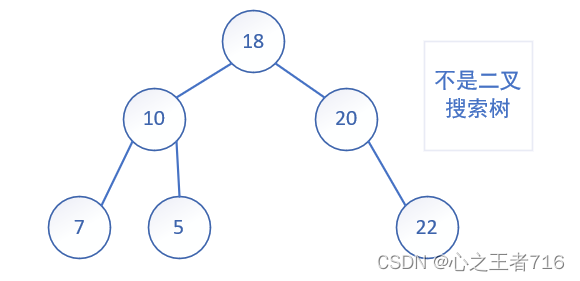
但是对于同一个关键码集合,如果各个关键码插入的次序不同,那么得到的二叉搜索树的结构也不同,例如下列树:
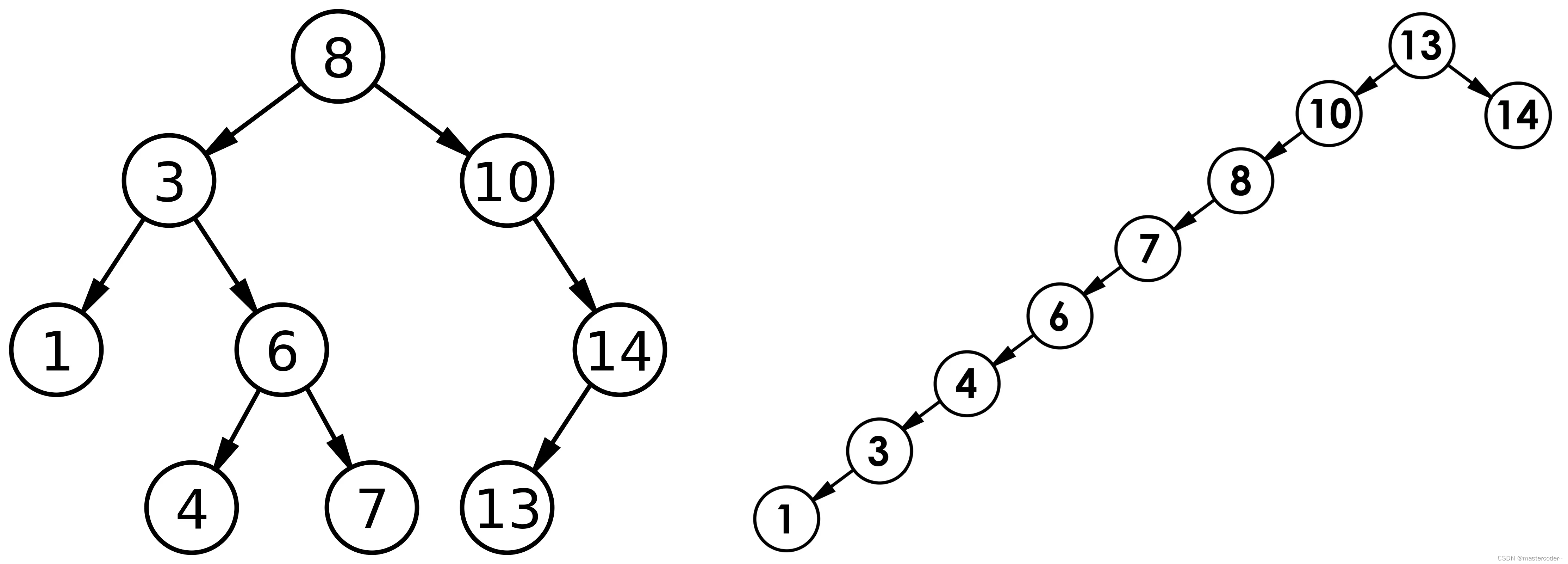
最优情况下,二叉搜索树为完全二叉树或者接近完全二叉树,那么比较的平均次数为:logn,最长时间复杂度为O(logn)
最差情况下,二茬搜索树为单支树,或者接近单支树,那么比较的平均次数为:n/2,最长时间复杂度为O(n)
![[<span style='color:red;'>C</span>++][<span style='color:red;'>数据</span><span style='color:red;'>结构</span>]<span style='color:red;'>二</span><span style='color:red;'>叉</span><span style='color:red;'>搜索</span><span style='color:red;'>树</span>:介绍和实现](https://img-blog.csdnimg.cn/direct/98cf784cdbd643e79920cdcdffd0d17a.png)
![[<span style='color:red;'>C</span>++][<span style='color:red;'>数据</span><span style='color:red;'>结构</span>][<span style='color:red;'>二</span><span style='color:red;'>叉</span><span style='color:red;'>搜索</span><span style='color:red;'>树</span>]详细讲解](https://img-blog.csdnimg.cn/direct/43c125502de743c6bc5e860cd1c8495e.png)