什么是 Redis?
Redis 是完全开源免费的,遵守 BSD 协议,是一个高性能的 key-value 数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis 支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时 候可以再次加载进行使用。
- Redis 不仅仅支持简单的 key-value 类型的数据,同时还提供 list, set,zset,hash 等数据结构的存储。
- Redis 支持数据的备份,即 master-slave 模式的数据备份。
Redis 优势
- 性能极高 – Redis 能读的速度是 110000 次/s,写的速度是 81000 次 /s 。
- 丰富的数据类型 – Redis 支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis 的所有操作都是原子性的,意思就是要么成功执行要么失 败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过 MULTI 和 EXEC 指令包起来。
- 丰富的特性 – Redis 还支持 publish/subscribe, 通知, key 过期等等特性。
Redis 与其他 key-value 存储有什么不同?
- Redis 有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个 不同于其他数据库的进化路径。Redis 的数据类型都是基于基本数据结构的同 时对程序员透明,无需进行额外的抽象。
- Redis 运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高 速读写时需要权衡内存,因为数据量不能大于硬件内存。在内存数据库方面的 另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常 简单,这样 Redis 可以做很多内部复杂性很强的事情。同时,在磁盘格式方面 他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。
Redis 的数据类型?
Redis 支持五种数据类型:string(字符串),hash(哈希),list(列 表),set(集合)及zsetsorted set:有序集合)。
我们实际项目中比较常用的是 string,hash 如果你是 Redis 中高级用户,还 需要加上下面几种数据结构HyperLogLog、Geo、Pub/Sub。
如果你说还玩过 Redis Module,像 BloomFilter,RedisSearch,Redis-ML, 面试官得眼睛就开始发亮了。
使用 Redis 有哪些好处?
- 速度快,因为数据存在内存中,类似于 HashMap,HashMap 的优势就是查 找和操作的时间复杂度都是 O(1)
- 支持丰富数据类型,支持 string,list,set,Zset,hash 等
- 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执 行,要么全部不执行
- 丰富的特性:可用于缓存,消息,按 key 设置过期时间,过期后将会自动删除
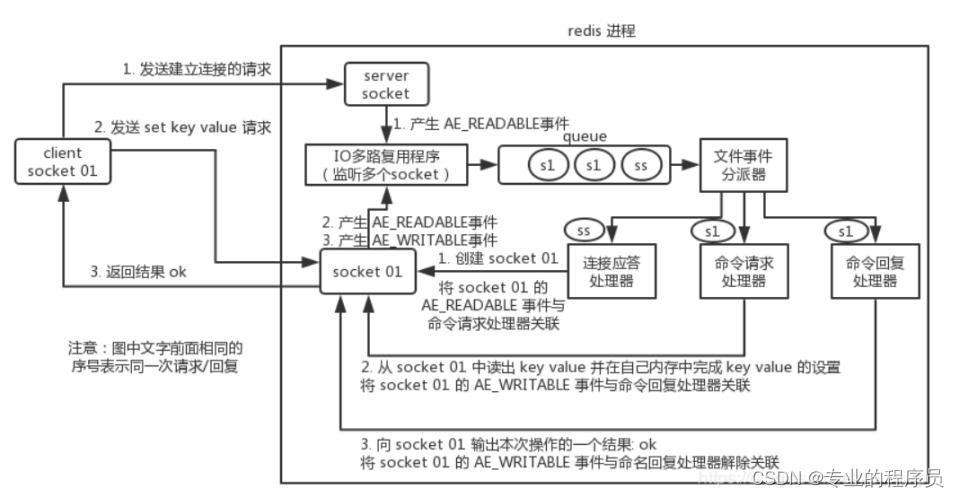
Redis 是单进程单线程的?
Redis 是单进程单线程的,redis 利用队列技术将并发访问变为串行访 问,消除了传统数据库串行控制的开销。
一个字符串类型的值能存储最大容量是多少?
答:512M
Redis 的持久化机制是什么?各自的优缺点?
Redis 提供两种持久化机制 RDB 和 AOF 机制:
RDBRedis DataBase持久化方式:
是指用数据集快照的方式半持久化模式)记录 redis 数据库的所有键值对,在某 个时间点将数据写入一个临时文件,持久化结束后,用这个临时文件替换上次 持久化的文件,达到数据恢复。
优点:
- 只有一个文件 dump.rdb,方便持久化。
- 容灾性好,一个文件可以保存到安全的磁盘。
- 性能最大化,fork 子进程来完成写操作,让主进程继续处理命令,所以 是 IO 最大化。使用单独子进程来进行持久化,主进程不会进行任何 IO 操 作,保证了 redis 的高性能)
- 相对于数据集大时,比 AOF 的启动效率更高。
缺点:
- 数据安全性低。RDB 是间隔一段时间进行持久化,如果持久化之间 redis 发生 故障,会发生数据丢失。所以这种方式更适合数据要求不严谨的时候
AOFAppend-only file)持久化方式:
是指所有的命令行记录以 redis 命令请求协议的格式完全持久化存储)保存为 aof 文件。
优点:
- 数据安全,aof 持久化可以配置 appendfsync 属性,有 always,每进行 一次命令操作就记录到 aof 文件中一次。
- 通过 append 模式写文件,即使中途服务器宕机,可以通过 redis- check-aof 工具解决数据一致性问题。
- AOF 机制的 rewrite 模式。AOF 文件没被 rewrite 之前(文件过大时会 对命令进行合并重写),可以删除其中的某些命令(比如误操作的 flushall))
缺点:
- AOF 文件比 RDB 文件大,且恢复速度慢。
- 数据集大的时候,比 rdb 启动效率低。
Redis 除了做缓存,还能做什么?
- 分布式锁 : 通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。
- 限流 :一般是通过 Redis + Lua 脚本的方式来实现限流。
- 消息队列 :Redis 自带的 list 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
- 复杂业务场景 :通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景比如通过 bitmap 统计活跃用户、通过 sorted set 维护排行榜。
String 的应用场景有哪些?
String 是 Redis 中最简单同时也是最常用的一个数据结构。String 是一种二进制安全的数据结构,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。
String 的常见应用场景如下:
- 常规数据(比如 session、token、序列化后的对象、图片的路径)的缓存;
- 计数比如用户单位时间的请求数(简单限流可以用到)、页面单位时间的访问数;
- 分布式锁(利用
SETNX key value命令可以实现一个最简易的分布式锁);
String 还是 Hash 存储对象数据更好呢?
- String 存储的是序列化后的对象数据,存放的是整个对象。Hash 是对对象的每个字段单独存储,可以获取部分字段的信息,也可以修改或者添加部分字段,节省网络流量。如果对象中某些字段需要经常变动或者经常需要单独查询对象中的个别字段信息,Hash 就非常适合。
- String 存储相对来说更加节省内存,缓存相同数量的对象数据,String 消耗的内存约是 Hash 的一半。并且,存储具有多层嵌套的对象时也方便很多。如果系统对性能和资源消耗非常敏感的话,String 就非常适合。
在绝大部分情况,我们建议使用 String 来存储对象数据即可!
String 的底层实现是什么?
Redis 是基于 C 语言编写的,但 Redis 的 String 类型的底层实现并不是 C 语言中的字符串(即以空字符 \0 结尾的字符数组),而是自己编写了 SDS(Simple Dynamic String,简单动态字符串) 来作为底层实现。
SDS 最早是 Redis 作者为日常 C 语言开发而设计的 C 字符串,后来被应用到了 Redis 上,并经过了大量的修改完善以适合高性能操作。
使用 Redis 实现一个排行榜怎么做?
Redis 中有一个叫做 sorted set 的数据结构经常被用在各种排行榜的场景,比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
相关的一些 Redis 命令: ZRANGE (从小到大排序) 、 ZREVRANGE (从大到小排序)、ZREVRANK (指定元素排名)。
Set 的应用场景是什么?
Redis 中 Set 是一种无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 HashSet 。
Set 的常见应用场景如下:
- 存放的数据不能重复的场景:网站 UV 统计(数据量巨大的场景还是
HyperLogLog更适合一些)、文章点赞、动态点赞等等。 - 需要获取多个数据源交集、并集和差集的场景:共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集) 、订阅号推荐(差集+交集) 等等。
- 需要随机获取数据源中的元素的场景:抽奖系统、随机点名等等。
使用 Set 实现抽奖系统怎么做?
如果想要使用 Set 实现一个简单的抽奖系统的话,直接使用下面这几个命令就可以了:
SADD key member1 member2 ...:向指定集合添加一个或多个元素。SPOP key count: 随机移除并获取指定集合中一个或多个元素,适合不允许重复中奖的场景。SRANDMEMBER key count: 随机获取指定集合中指定数量的元素,适合允许重复中奖的场景。
使用 Bitmap 统计活跃用户怎么做?
Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。
你可以将 Bitmap 看作是一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)。
如果想要使用 Bitmap 统计活跃用户的话,可以使用日期(精确到天)作为 key,然后用户 ID 为 offset,如果当日活跃过就设置为 1。
初始化数据:
> SETBIT 20210308 1 1
(integer) 0
> SETBIT 20210308 2 1
(integer) 0
> SETBIT 20210309 1 1
(integer) 0
统计 20210308~20210309 总活跃用户数:
> BITOP and desk1 20210308 20210309
(integer) 1
> BITCOUNT desk1
(integer) 1
统计 20210308~20210309 在线活跃用户数:
> BITOP or desk2 20210308 20210309
(integer) 1
> BITCOUNT desk2
(integer) 2
使用 HyperLogLog 统计页面 UV 怎么做?
使用 HyperLogLog 统计页面 UV主要需要用到下面这两个命令:
PFADD key element1 element2 ...:添加一个或多个元素到 HyperLogLog 中。PFCOUNT key1 key2:获取一个或者多个 HyperLogLog 的唯一计数。
1、将访问指定页面的每个用户 ID 添加到 HyperLogLog 中。
PFADD PAGE_1:UV USER1 USER2 ...... USERnCopy to clipboardErrorCopied
2、统计指定页面的 UV。
PFCOUNT PAGE_1:UV
欢迎使用我创建的面试题小程序