课程地址
最近做实验发现自己还是基础框架上掌握得不好,于是开始重学一遍PyTorch框架,这个是课程笔记,这个课还是讲的简略,我半小时的课听了一个半小时。
1. Dataset与DataLoader
Dataset类是处理单个训练样本的,也就是它是实现如何从磁盘中读取训练数据集,包括它的标签,还会做一些数据预处理,最后变成x和y的训练对象。(构建数据集)
DataLoader:我们通过Dataset读取数据集以后,再通过DataLoader将其变为随机梯度下降算法所需要的mini-batch的形式,它会对多个样本组合成一个mini-batch,它也可能在每个周期以后对数据进行一个打乱,甚至它可能会将数据固定地保存在GPU中。
【提问】在深度学习领域,何为mini-batch
【GPT回答】在深度学习领域,mini-batch是指将训练数据集分成小批量进行训练的一种技术。通常情况下,训练数据集很大,一次性将全部数据用于训练会占用大量内存并且计算量巨大。因此,将数据分成小批量进行训练是一种有效的方法。mini-batch训练允许模型在每次迭代中使用部分数据,以逐渐优化模型参数。在每个迭代步骤中,模型接收一批输入数据,计算损失函数,并通过反向传播更新模型参数以减小损失。这一过程反复进行直到达到停止条件,例如达到指定的迭代次数或损失函数收敛到某个阈值。使用mini-batch训练可以提高模型训练的效率和稳定性,同时还可以充分利用计算资源。在深度学习里,mini-batch就像是一批批小份的训练数据,而不是一次性放进去的整份大餐。相当于你在学习时,不是一口吞下整本书,而是分成小段小段地消化。这样做有助于模型更高效地学习和优化参数,也更容易掌握。
1.1 利用torchvision库导入官方内置数据集
下面是官方给的例子,使用torchvision导入FashionMNIST数据集,torchvision库中的datasets中就有FashionMNIST数据集
【提问】FashionMNIST数据集是什么数据集?
【GPT回答】FashionMNIST数据集是一个常用的机器学习和深度学习领域的数据集,用于图像分类任务。它包含了10个类别的灰度服装图片,每个类别有6000张图片,总共包含了60000张图片。这些类别包括了衬衫、裤子、套衫、裙子、外套、凉鞋、衬衫、运动鞋和背包。FashionMNIST的图像大小都是28x28像素,相对于传统的手写数字数据集MNIST,FashionMNIST提供了更具挑战性的图像分类任务。这个数据集被广泛用于测试和比较不同机器学习和深度学习模型的性能。
import torch
from torch.utils.data import Dataset # 引入PyTorch的Dataset模块
from torchvision import datasets # 引入PyTorch的datasets模块
from torchvision.transforms import ToTensor # 引入PyTorch的ToTensor转换
import matplotlib.pyplot as plt # 引入matplotlib.pyplot库用于可视化
# 加载FashionMNIST训练数据集,并将其转换为Tensor格式
training_data = datasets.FashionMNIST(
root="data", # 数据集存储的根目录
train=True, # 指定加载训练数据集
download=True, # 如果数据不存在,是否下载
transform=ToTensor() # 将数据转换为Tensor格式
)
# 加载FashionMNIST测试数据集,并将其转换为Tensor格式
test_data = datasets.FashionMNIST(
root="data", # 数据集存储的根目录
train=False, # 指定加载测试数据集
download=True, # 如果数据不存在,是否下载
transform=ToTensor() # 将数据转换为Tensor格式
)
如果电脑中没有下载过这个数据集,则执行这些代码会自动下载FashionMNIST数据集

最后会下载到项目路径的根目录的data文件夹(如果没有data文件夹,将自动创建)

然后我们要对数据集做一个可视化,还要接着刚才的代码下面继续写:
# 接刚才的代码,对这个数据集做一个可视化
# 下面这段代码用于可视化FashionMNIST数据集中的随机样本图像,并在图像上显示对应的类别名称。
# 定义一个字典,用于将类别标签索引映射为可读的类别名称
labels_map = {
0: "T-Shirt",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle Boot",
}
# 创建一个大小为8x8英寸的图像窗口
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3 # 设置子图的行数和列数为3
# 循环创建子图并显示FashionMNIST训练集中的随机样本图像
for i in range(1, cols * rows + 1):
sample_idx = torch.randint(len(training_data), size=(1,)).item() # 随机选择一个样本的索引
img, label = training_data[sample_idx] # 获取该索引对应的图像和标签
figure.add_subplot(rows, cols, i) # 在图像窗口中添加子图
plt.title(labels_map[label]) # 设置子图标题为该样本的类别名称
plt.axis("off") # 关闭子图的坐标轴
plt.imshow(img.squeeze(), cmap="gray") # 显示图像,squeeze()用于去除维度为1的维度,cmap="gray"指定灰度色彩映射
plt.show() # 显示图像窗口
如果可视化成功,你将看到下面的窗口:
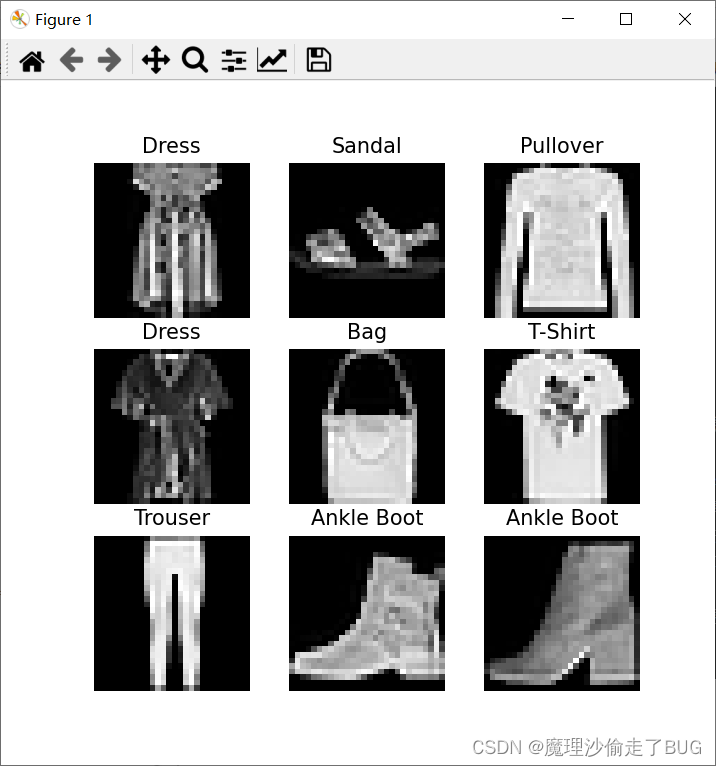
如果出现报错:OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
你需要在最开始调库的代码后面加上这样一段:
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
完整的代码:
import torch
from torch.utils.data import Dataset # 引入PyTorch的Dataset模块
from torchvision import datasets # 引入PyTorch的datasets模块
from torchvision.transforms import ToTensor # 引入PyTorch的ToTensor转换
import matplotlib.pyplot as plt # 引入matplotlib.pyplot库用于可视化
# 加如下代码
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
# 加载FashionMNIST训练数据集,并将其转换为Tensor格式
training_data = datasets.FashionMNIST(
root="data", # 数据集存储的根目录
train=True, # 指定加载训练数据集
download=True, # 如果数据不存在,是否下载
transform=ToTensor() # 将数据转换为Tensor格式
)
# 加载FashionMNIST测试数据集,并将其转换为Tensor格式
test_data = datasets.FashionMNIST(
root="data", # 数据集存储的根目录
train=False, # 指定加载测试数据集
download=True, # 如果数据不存在,是否下载
transform=ToTensor() # 将数据转换为Tensor格式
)
# 接刚才的代码,对这个数据集做一个可视化
# 下面这段代码用于可视化FashionMNIST数据集中的随机样本图像,并在图像上显示对应的类别名称。
# 定义一个字典,用于将类别标签索引映射为可读的类别名称
labels_map = {
0: "T-Shirt",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle Boot",
}
# 创建一个大小为8x8英寸的图像窗口
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3 # 设置子图的行数和列数为3
# 循环创建子图并显示FashionMNIST训练集中的随机样本图像
for i in range(1, cols * rows + 1):
sample_idx = torch.randint(len(training_data), size=(1,)).item() # 随机选择一个样本的索引
img, label = training_data[sample_idx] # 获取该索引对应的图像和标签
figure.add_subplot(rows, cols, i) # 在图像窗口中添加子图
plt.title(labels_map[label]) # 设置子图标题为该样本的类别名称
plt.axis("off") # 关闭子图的坐标轴
plt.imshow(img.squeeze(), cmap="gray") # 显示图像,squeeze()用于去除维度为1的维度,cmap="gray"指定灰度色彩映射
plt.show() # 显示图像窗口
1.2 构建自己的Dataset类
要想构建自己的Dataset类,我们需要继承官方的Dataset类
【注】继承是面向对象编程的术语,在面向对象编程中,继承是一种机制,允许一个类(称为子类或派生类)从另一个类(称为父类或基类)中继承属性和方法。这意味着子类可以重用父类的代码,并且可以在此基础上添加新的属性和方法,或者修改现有的属性和方法,以满足特定的需求。继承提供了代码重用和扩展的便利性,有助于提高代码的可维护性和可扩展性。
我们继承的Dataset类必须要实现三个函数
- __init__构造函数
- __len__数据集长度
- __geiitem__获取元素(按索引获取)
官方给的例子做注释后是这样的:
import os # 导入os模块用于操作系统相关功能
import pandas as pd # 导入pandas库用于数据处理
from torchvision.io import read_image # 从torchvision.io模块中导入read_image函数
# 自定义自己的数据集类
class CustomImageDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
# 初始化函数,接收注释文件路径、图像目录路径以及转换函数参数
self.img_labels = pd.read_csv(annotations_file) # 从CSV文件中读取图像标签数据
# 标签存储在CSV文件中就这样读取,
# 如果是存储在文本文档等格式下,需要自己改一下,
# 看一看pandas读取数据的API,
# 这个csv文件要求第0列是存储图片名,
# 第1列是存储图片的标签,
# 每一行都是一个图片样本向量(图片的名称, 类别的标签)
self.img_dir = img_dir # 设置图像所在的目录路径
self.transform = transform # 设置图像转换函数
self.target_transform = target_transform # 设置标签转换函数
def __len__(self):
# 返回数据集的长度,即图像标签的数量
return len(self.img_labels)
def __getitem__(self, idx):
# 获取指定索引处的图像数据和标签数据
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0]) # 获取图像文件的完整路径,照片的文件名是根据标签文件csv表格中的下标为idx的行,下标为0的列的所有元素中去取得的
image = read_image(img_path) # 读取图像文件
label = self.img_labels.iloc[idx, 1] # 获取图像对应的标签,标签是根据标签文件csv表格中的下标为idx的行,下标为1的列的所有元素中去取得的
if self.transform:
# 如果指定了图像转换函数,则对图像进行转换(归一化,旋转操作以及将图片的长宽都统一成一个格式等等)
image = self.transform(image)
if self.target_transform:
# 如果指定了标签转换函数,则对标签进行转换
label = self.target_transform(label)
return image, label # 返回图像数据和标签数据
transform函数我们后期会提到
1.3 构建自己的DataLoader类
Dataset它只能处理单个样本,通常我们训练的时候,如果只处理一个样本是不切实际的,因此我们要用DataLoader类将多个样本打包成mini-batch成批地进行训练,而且我们还可以用DataLoader对数据进行打乱,降低模型过拟合的可能性,然后DataLoader还使用Python的多线程技术,使得我们读取数据的速度不会影响到GPU训练的速度。
这是官方给的创建DataLoader的例子:
from torch.utils.data import DataLoader
# 第一个参数是数据集,第二个参数是batch_size(每batch批次中的图片个数),shuffle为True表示要打乱数据
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True) # 训练集DataLoader
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True) # 测试集DataLoader,一般来说测试集不需要打乱,它不参与梯度更新,它只是做一个前向的运算而已。
1.3.1 常用的DataLoader的构造函数参数
常用的DataLoader的构造函数参数如下:
- dataset:传入自己定义好的数据集类Dataset
- batch_size:默认值为1,它代表着每批次训练的样本的个数
- shuffle:布尔类型,True为打乱数据集,False为不打乱数据集
- sampler:决定以何种方式对数据进行采样,可以用它默认的sampler,也可以自己实现一个sampler。
【提问】请用通俗易懂的语言告诉我在PyTorch中DataLoader的构造函数的参数sampler有什么作用?
【GPT回答】在PyTorch中,DataLoader的构造函数的参数sampler用于指定数据采样的策略。通俗地说,采样器决定了数据集中样本的顺序以及每次迭代中使用哪些样本。
具体来说,当你创建一个DataLoader对象时,如果提供了sampler参数,PyTorch将根据指定的采样策略来确定每次迭代中要使用的数据样本。这可以帮助你自定义数据的加载顺序或者进行特定的采样方式,比如随机采样、顺序采样、权重采样等。
总之,sampler参数允许你在数据加载过程中灵活地控制样本的选择方式,以满足你的特定需求,例如在训练过程中对数据进行随机化处理或者按照一定的顺序进行加载。
- batch_sampler:与sampler参数不同,batch_sampler参数用于指定每个批次中样本的采样策略。
- num_workers:默认值为0,它是指数据加载的子进程数量,以加快数据加载的速度,提高训练效率。一般数值设定取决于CPU的核心数,通常数字大到一定程度,其加载速度也不会再提高了。
- collate_fn:collate_fn参数允许你定义如何对样本进行批次化处理,以便神经网络可以有效地处理不同大小或结构的样本。也就是对每个批次做一个处理。通常情况下,当你从数据集中加载一批样本时,这些样本可能具有不同的大小或者结构。而神经网络需要接受固定大小的批次作为输入,因此需要将这些不同大小的样本组合成统一大小的批次。collate_fn参数允许你自定义如何将样本列表转换为批次。例如,你可以使用该参数来填充或截断样本,使它们具有相同的大小,或者进行其他任何类型的预处理操作以满足你的需求。相当于transform函数,但是transform函数是对单个样本进行处理,而collate_fn参数是对一个小批次的样本做处理。
- pin_memory:布尔类型,默认值为False,用于指定是否将数据加载到固定的内存区域(pinned memory)中。固定内存区域是指一块被操作系统锁定的内存,这样可以防止它被移动,从而提高数据传输的效率。当pin_memory参数设置为True时,PyTorch会尝试将从数据集加载的数据存储在固定的内存中,这对于GPU加速的情况下可以提高数据传输效率,因为GPU可以直接从固定内存中访问数据,而不需要进行额外的内存拷贝操作。需要注意的是,只有当你使用GPU进行训练时,才会考虑使用pin_memory参数。对于CPU训练来说,pin_memory参数的影响通常不太明显。而且这个东西对训练速度的影响还有待考究。
- drop_last:布尔类型,默认为False,如果你的总样本数目不是每个批次batch的整数倍的话,这时候我们可以将drop_last设置为True,让最后那个小批次(样本数没达到batch-size的批次)丢掉。
1.3.2 将数据送入DataLoader
官方还是用FashionMNIST数据集做例子,展示了将数据集送入DataLoader后,遍历DataLoader:
# 展示图片和标签
# 从训练数据集加载一个批次的数据(DataLoader对象是一个可迭代的对象,用next是获取可迭代对象的第一个元素)
train_features, train_labels = next(iter(train_dataloader))
# 打印特征(图像)和标签的形状,用于查看批次的大小信息
print(f"Feature batch shape: {train_features.size()}")
print(f"Labels batch shape: {train_labels.size()}")
# 获取批次中第一个图像并去除可能的单维度
img = train_features[0].squeeze()
# 获取第一个标签
label = train_labels[0]
# 使用matplotlib的imshow函数显示图像
plt.imshow(img, cmap="gray")
plt.show()
# 打印图像对应的标签
print(f"Label: {label}")
完整的代码:
import torch
from torch.utils.data import Dataset # 引入PyTorch的Dataset模块
from torchvision import datasets # 引入PyTorch的datasets模块
from torchvision.transforms import ToTensor # 引入PyTorch的ToTensor转换
import matplotlib.pyplot as plt # 引入matplotlib.pyplot库用于可视化
# 防止报错
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
# 加载FashionMNIST训练数据集,并将其转换为Tensor格式
training_data = datasets.FashionMNIST(
root="data", # 数据集存储的根目录
train=True, # 指定加载训练数据集
download=True, # 如果数据不存在,是否下载
transform=ToTensor() # 将数据转换为Tensor格式
)
# 加载FashionMNIST测试数据集,并将其转换为Tensor格式
test_data = datasets.FashionMNIST(
root="data", # 数据集存储的根目录
train=False, # 指定加载测试数据集
download=True, # 如果数据不存在,是否下载
transform=ToTensor() # 将数据转换为Tensor格式
)
# 接刚才的代码,对这个数据集做一个可视化
# 下面这段代码用于可视化FashionMNIST数据集中的随机样本图像,并在图像上显示对应的类别名称。
# 定义一个字典,用于将类别标签索引映射为可读的类别名称
labels_map = {
0: "T-Shirt",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle Boot",
}
# 创建一个大小为8x8英寸的图像窗口
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3 # 设置子图的行数和列数为3
# 循环创建子图并显示FashionMNIST训练集中的随机样本图像
for i in range(1, cols * rows + 1):
sample_idx = torch.randint(len(training_data), size=(1,)).item() # 随机选择一个样本的索引
img, label = training_data[sample_idx] # 获取该索引对应的图像和标签
figure.add_subplot(rows, cols, i) # 在图像窗口中添加子图
plt.title(labels_map[label]) # 设置子图标题为该样本的类别名称
plt.axis("off") # 关闭子图的坐标轴
plt.imshow(img.squeeze(), cmap="gray") # 显示图像,squeeze()用于去除维度为1的维度,cmap="gray"指定灰度色彩映射
plt.show() # 显示图像窗口
from torch.utils.data import DataLoader
# 第一个参数是数据集,第二个参数是batch_size(每batch批次中的图片个数),shuffle为True表示要打乱数据
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
# 展示图片和标签
# 从训练数据集加载一个批次的数据(DataLoader对象是一个可迭代的对象,用next是获取可迭代对象的第一个元素)
train_features, train_labels = next(iter(train_dataloader))
# 打印特征(图像)和标签的形状,用于查看批次的大小信息
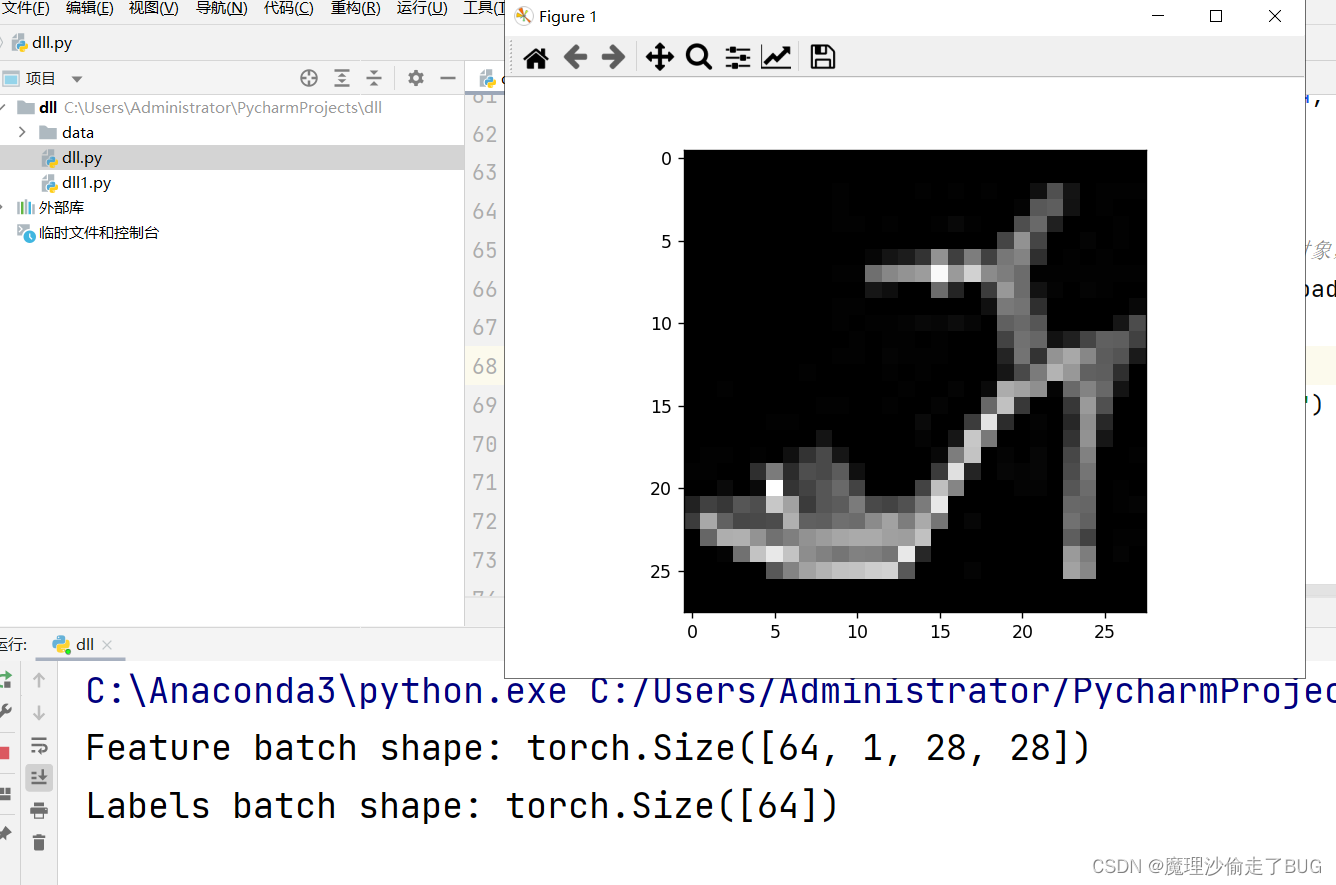
print(f"Feature batch shape: {train_features.size()}")
print(f"Labels batch shape: {train_labels.size()}")
# 获取批次中第一个图像并去除可能的单维度
img = train_features[0].squeeze()
# 获取第一个标签
label = train_labels[0]
# 使用matplotlib的imshow函数显示图像
plt.imshow(img, cmap="gray")
plt.show()
# 打印图像对应的标签
print(f"Label: {label}")
除了对训练样本进行可视化展示以外,还打印特征(图像)和标签的形状,用于查看批次的大小信息:



























![[附源码]SpringBoot+Vue网盘项目_仿某度盘](https://img-blog.csdnimg.cn/img_convert/702b7f30139045f1abc92a079b00ed92.webp?x-oss-process=image/format,png)
