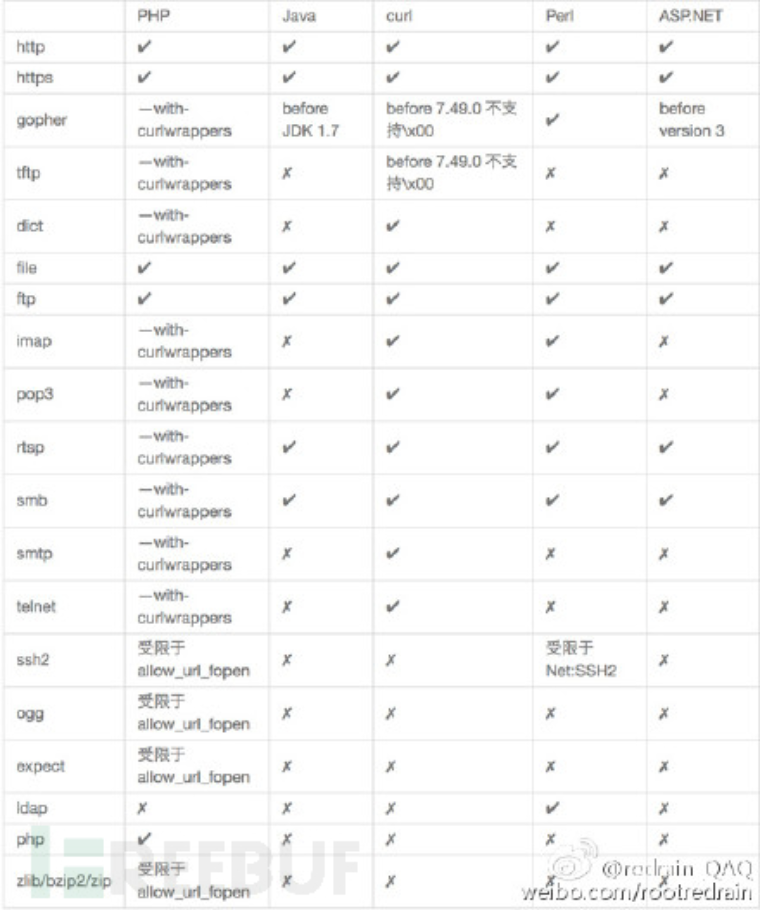
PyTorch为我们提供了Dataset和DataLoader类分别负责可被Pytorch使用的数据集的创建以及向训练传递数据的任务。一般在项目中,我们需要根据自己的数据集个性化pytorch中储存数据集的方式和数据传递的方式,需要自己重写一些子类。
torch.utils.data.Dataset 是一个表示数据集的抽象类。任何自定义的数据集都需要继承这个类并覆写相关方法。数据集主要有两个功能,一个是读取本地的数据集并储存起来,另外一个是负责处理索引(index)到样本(sample)映射。
因此,在定义自己的数据集时,一般我们需要重写init,getitem,len这三个方法,在init中,执行加载数据集和储存数据集的任务,getitem中执行根据索引(index)从数据集中取出一个样本。len方法则返回数据集中的样本数。
例子:
import torch
import torch.utils.data.dataset as Dataset
#创建子类
class mydataset(Dataset.Dataset):
#初始化,定义数据内容和标签
def __init__(self, Data, Label):
self.Data = Data
self.Label = Label
#返回数据集大小
def __len__(self):
return len(self.Data)
#得到数据内容和标签
def __getitem__(self, index):
data = torch.Tensor(self.Data[index])
label = torch.Tensor(self.Label[index])
return data, label
在我们创建了自己的dataset后,就可以用这个dataset创建我们的dataloader了,一般来说在PyTorch项目中加载数据集的流程是这样的: 1. 创建Dateset。 2. 将Dataset作为参数传递给DataLoader,创建dataloader。 3. DataLoader迭代按照batch大小产生训练数据提供给模型。dataloader的定义为:
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None)
解释其中几个比较关键的:dataset就是我们自己重写后的数据集;batch_size是超参,即设置的batch大小;shuffle是否打乱数据;drop_last是否截断数据(如果样本数量与batchsize不能整除的情况下);num_workers是同时参与数据读取的线程数量,多线程技术可以加快数据读取,但是如果项目不大,设置为0就行,免得引入新问题;collate_fn,数据整理函数,这个方法可以被传递进去,把一个batch的数据变成你想要的样子。
给一个自定义的collate_fn函数的例子:
def collate_fn(data):
img = [i[0][0] for i in data]
txt = [i[0][1] for i in data]
labels = [i[1] for i in data]
img = torch.stack(img).cuda()
txt = torch.stack(txt).cuda()
labels = torch.LongTensor(labels).cuda()
return img, txt ,labels
那么我们的一般流程为:
# 创建Dateset(自定义)
dataset = mydataset()
# Dataset传递给DataLoader
dataloader = DataLoader(dataset,batch_size=64,shuffle=False,num_workers=8,collate_fn=my_collate_fn)
# DataLoader迭代产生训练数据提供给模型
for i in range(epoch):
for index,(img,txt,label) in enumerate(dataloader):
pass