Tutorial/xtuner at camp2 · InternLM/Tutorial · GitHub
视频链接:https://b23.tv/BrTSfsl
PDF链接:https://pan.baidu.com/s/1JFtvBWgEGFWJq8pHafvIUg?pwd=6666
提取码:6666
1、Finetune简介
为什么微调?基础模型不能满足特定领域需求。
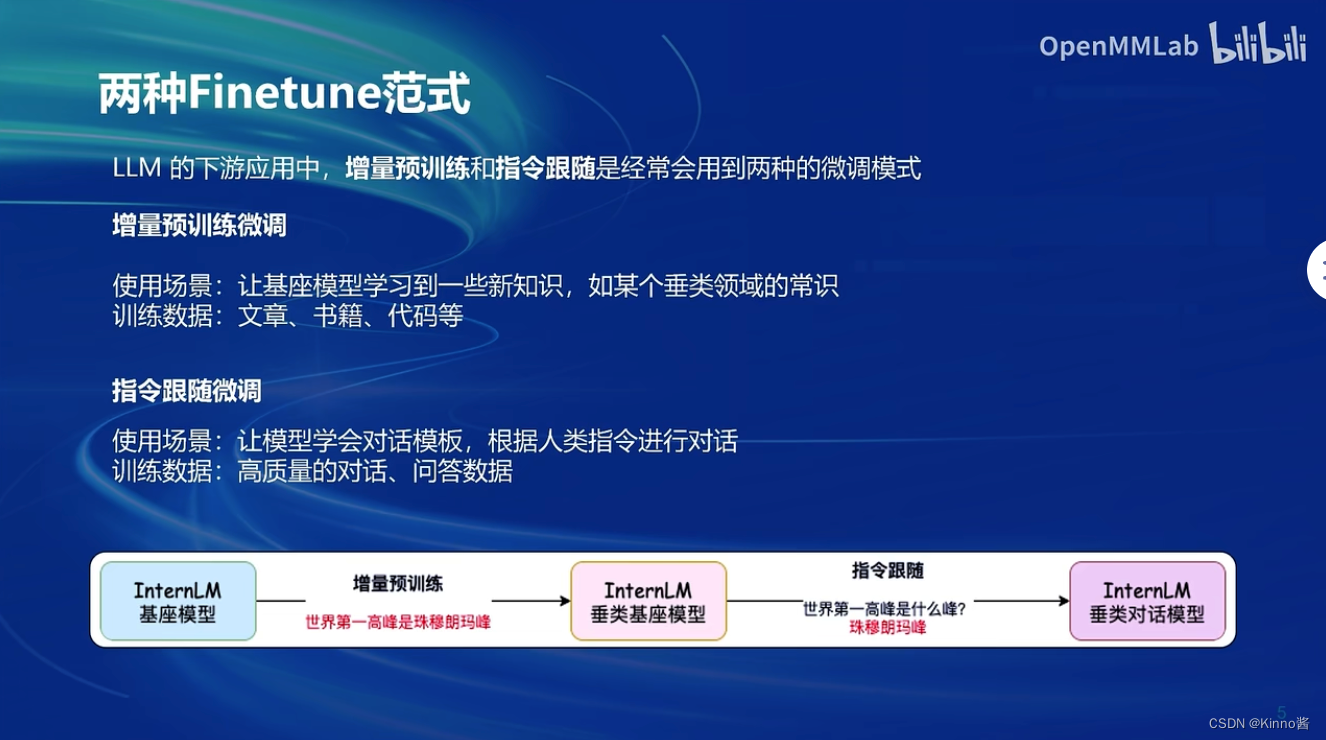
两种Finetune范式:
- 增量预训练:简单的增加新的知识
- 指令跟随:问答的形式,学会人类指令。


基座模型只是单纯的拟合训练数空间分布,无法意识到输入是一个问题,返回一个类似于最相似的结果,如上图test。
指令微调输入的是一问一答的聊天,可以理解输入的是问题。
一条数据的一生

原始数据:如爬虫得来的
标准格式数据:训练模型能接受的输入
XTuner中json形式
增加对话模板:为了让大语言模型能够区分出三种角色,实际上就是增加标注,并且在实际训练的时候还要增加其实标识符。

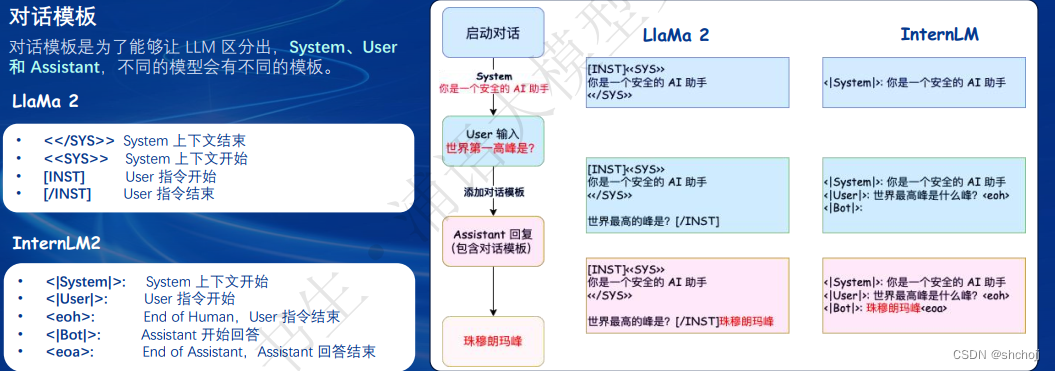


Token方案:LoRA和QLoRA


LoRA:降低显存开销,新增两个Liner(adapter)
QLoRA:在加载模型的时候就已经把基座模型给优化了。
2、XTuner介绍
打包好的微调工具箱
7B,LLM只需要8GB现存

与LLaMa-Fatory对比,训练速度更快

out of memory
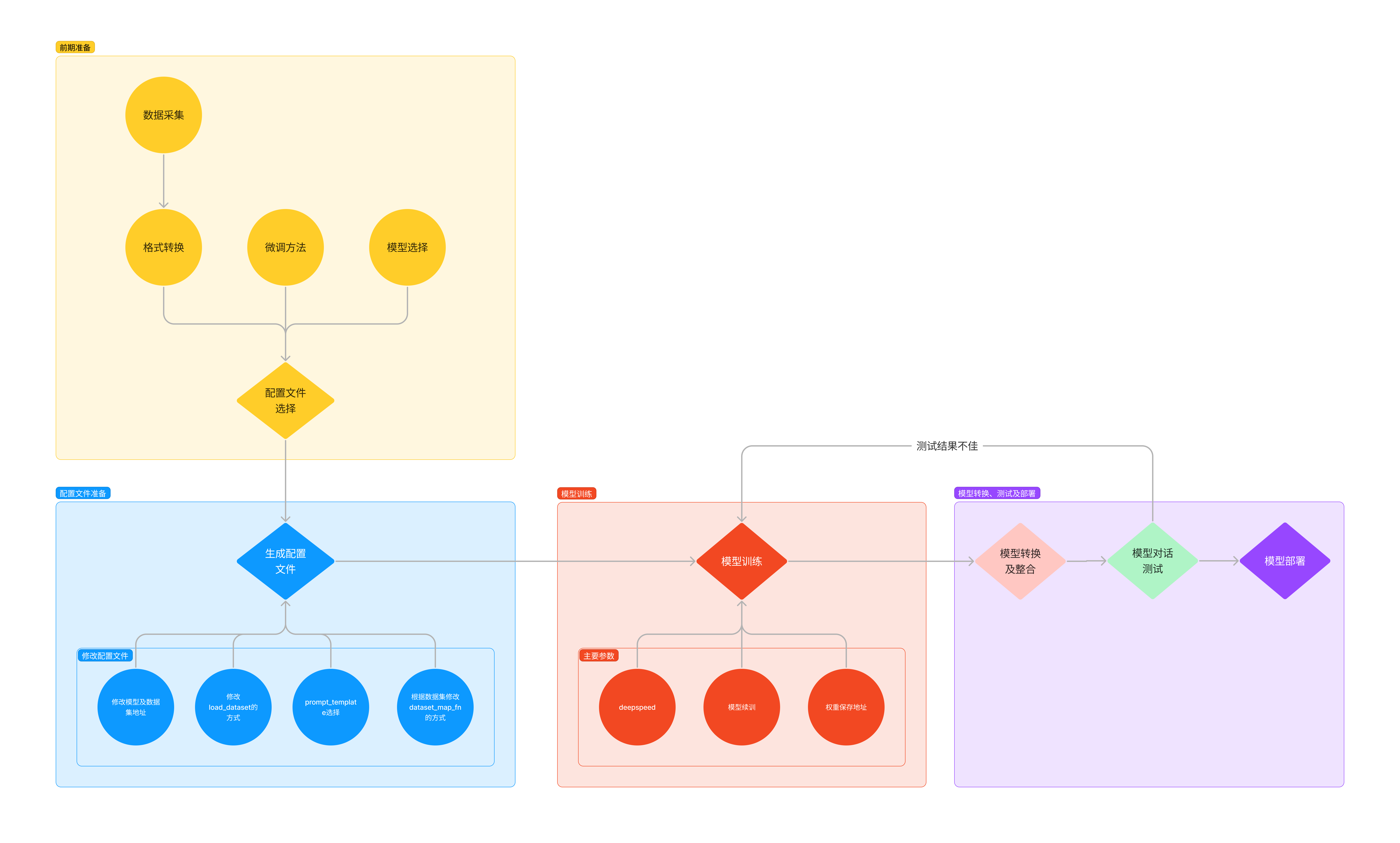
Xtuner快速上手
- 安装
pip install xtuner- 挑选配置模板
xtuner list-cfg -p internlm_20b- 一键训练
xtuner train internlm_20b_qlora_oasst1_512_e3训练的输入,Config 命名规则
| 模型名称 | internlm_20b (无chat代表基座模型,有的话表示经过微调了) |
| 使用算法 | qlora |
| 数据集 | oasst1 |
| 数据长度 | 512 |
| Epoch | e3, epoch3 |
===============================CONFIGS=========================
PATTERN: internlm_20b
-----------------------------------------
internlm_20b_chat_qlora_aplaca_e3
internlm_20b_chat_qlora_aplaca_enzh_e3
internlm_20b_chat_qlora_aplaca_enzh_oasst1_e3
internlm_20b_chat_qlora_aplaca_zh_e3
internlm_20b_chat_qlora_code_aplaca_e3
internlm_20b_chat_qlora_lawyer_e3
internlm_20b_chat_qlora_oasst1_512_e3
internlm_20b_chat_qlora_oasst1_e3
internlm_20b_chat_qlora_open_platypus_e3
internlm_20b_qlora_aplaca_e3
internlm_20b_qlora_aplaca_enzh_e3
internlm_20b_qlora_aplaca_enzh_oasst1_e3
internlm_20b_qlora_aplaca_zh_e3
internlm_20b_qlora_arxiv_gentitle_e3
internlm_20b_qlora_code_alpaca_e3
internlm_20b_qlora_colorist_e5
internlm_20b_qlora_lawyer_e3
internlm_20b_qlora_oasst1_512_e3
internlm_20b_qlora_oasst1_e3
internlm_20b_qlora_open_platypus_e3
internlm_20b_qlora_sql_e3
- 拷贝配置模板
xtuner copy-cfg internlm_20b_qlora_oasst1_512_e3 ./- 修改配置模板
vi internlm_20b_qlora_oasst1_512_e3_copy.py- 启动训练
xtuner train internlm_20b_qlora_oasst1_512_e3_copy.py- 常用超参
| data_path | 数据路径或HuggingFace仓库名 |
| max_length | 单挑数据最大Token数,超过则截断 |
| pack_to_max_length | 是否将多条短数据拼接到max_length,提高GPU利用率 |
| accumulative_counts | 梯度累积,每多少次backwward更新一次参数 |
| evaluation_inputs | 训练过程中,会根据给定问题进行推理,便于观测训练状态 |
| evaluation_freq | Evaluation的测评间隔iter数 |
##########################################################################
# PART 1 Settings #
##########################################################################
# Model
pretrained_model_name_or_path = ' internlm/internlm-20b'
#Data
data_path = 'timdettmers/openassistant-guanaco'
prompt_template = PROMPT_TEMPLATE.openassistant
max_length = 2048
pack_to_max_length = True
# Scheduler & Optimizer
batch_size = 1 # per_device
accumulative_counts = 16
dataloader_num_workers = 0
max_epochs = 3
optim_type = PagedAdamW32bit
lr = 2e-4
betas = (0.9, 0.999)
weight_decay = 0
max_norm = 1 # grad clip
# Evaluate the generation performance during the training
evaluation_freq = 500
evaluation_inputs = ['请给我介绍五个上海的景点','Please tell me five scenic spots in Shanghai']对话接口
double enter to end input >>>Float 16 模型对话
xtuner chat internlm/internlm-chat-20b4bit模型对话:量化
xtuner chat internlm/internlm-chat-20b --bits 4加载Adapter模型对话:微调,保存qlora参数生成adatper文件,指定adapter文件路径
xtuner chat internlm/internlm-chat-20b --adapater $ADAPTER_DIR工具类模型对话:网络检索、使用计算器、解方程(详见huggingface hub xtuner/Llama-2-7b-qlora-moss-003-sft)
数据引擎:(数据格式转换)
- 原始问答对-->格式化问答对(数据集映射函数)



- 格式化问答对-->可训练语料(对话模板映射函数)


蓝色代表有训练Loss部分
多数据样本拼接(pack Dataset)(增强并行性,充分利用GPU资源,max_length)


训练自己定义的JSON数据集(Alpaca配置文件)
- 拷贝配置模板
xtuner copy-cfg internlm_20b_qlora_e3 ./- 修改配置模板
vi internlm_20b_qlora_aplaca_e3_copy.py
- 启动训练
xtuner train internlm_20b_qlora_aplaca_e3_copy.pyfrom xtuner.dataset import process_hf_dataset
from datasets import load_dataset
from xtuner.dataset.map_fns import alpace_map_fn, template_map_fn_factory
from xtuner.utils import PROMPT_TEMPLATE
...
##############################################################
# PART 1 Setting #
##############################################################
data_path = 'path/to/your/json/data'
...
##############################################################
# STEP 3 Dataset & Dataloader #
##############################################################
train_dataset = dict(
type = process_hf_dataset,
dataset=dict(type=load_dataset, path='json', data_files=dict(train=data_path)),
tokenizer=tokenizer,
max_length = max_length,
dataset_map_fn = alpace_map_fn,
template_map_fn = dict(type=template_map_fn_factory, template = prompt_template),
remove_unused_columns=True,
shuffle_before_pack=True,
pack_to_max_length=pack_to_max_length)
...3、8GB显存玩转LLM
Flash Attention:将attention计算并行话,避免计算过程中attention score NxN的显存占用(训练过程N都比较大)
DeepSpeed ZeRO:通过将训练过程中的参数、梯度、优化器状态切片保持,能够在多GPU训练时显著节省显存,而且训练时还是FP16权重,相对于pytorch的AMP训练,在单GPU上也能大幅度节省显存。


xtuner train internlm_20b_qlora_oasst1_512_e3 --deepspeed deepspeed_zero3
显存明显下降了
4、InternLM2 1.8B模型
- InternLM2-1.8B:底座模型
- InternLM2-Chat-1.8B-SFT:在InternLM2-1.8B模型基础上,监督微调(SFT)后得到的对话模型
- InternLM2-Chat-1.8B:在线RLHF在InternLM2-Chat-1.8B-SFT上进一步对齐,有更好的指令跟随、聊天体验和函数调用,推荐下游用用程序使用,模型大小为3.78GB
在FP16精度上InternLM2-Chat-1.8B仅需要4GB显存,笔记本上的显卡也可以顺畅云效,8GB的显卡可以进行1.8B模型的微调。
适合初学者入门了解大模型全链路。
5、多模态微调(图像理解)
- 给LLM装上电子眼:单模太纯文本的大语言模型,多模态LLM原理简介
- 快速上手:InternLM2_Chat_1.8B+LLaVA

文本单模态:将文本转换成文本向量,然后将文本向量进行预测。
文本+图像多模态 :在输出的时候增加了图像的输入和处理,文本向量+图像向量同时作为输入,预测输出。
文本+图像多模态微调过程,实际上就是image projector训练的过程。

- 什么型号的电子眼:LLaVA方案简介
数据对:识别图像
-- 输入:文本问题+图片数据
--输出:文本回答

Image Projector训练测试类似于LoRA微调方案,都是在已有的LLM基础上,用新数据训练一个新的小文件,只不过LLM套上LoRA之后有了新的角色(眼睛)

Pretrain:大量的图像+标题(问题/描述/标签),有监督,但数据质量不高,让单模态LLM快速了解图像普遍特征。增量预训练
Finetune:图像+复杂对话文本,有监督数据,高质量的数据,结合pretrain LLM,指令跟随,了解到模型想要问什么。指令微调。

Pretrain:数据格式就是一张图片一个描述 。

Finetune:不仅有问题,还有很多条问答对,高质量的数据进行指令跟随。
6、Agent







![[InternLM训练营第二期笔记]4. <span style='color:red;'>XTuner</span> <span style='color:red;'>微调</span> <span style='color:red;'>LLM</span>:1.8<span style='color:red;'>B</span>、<span style='color:red;'>多</span><span style='color:red;'>模</span><span style='color:red;'>态</span>、<span style='color:red;'>Agent</span>](https://img-blog.csdnimg.cn/direct/57e34f733ca44480a76ca2d2a28ad5d8.png)