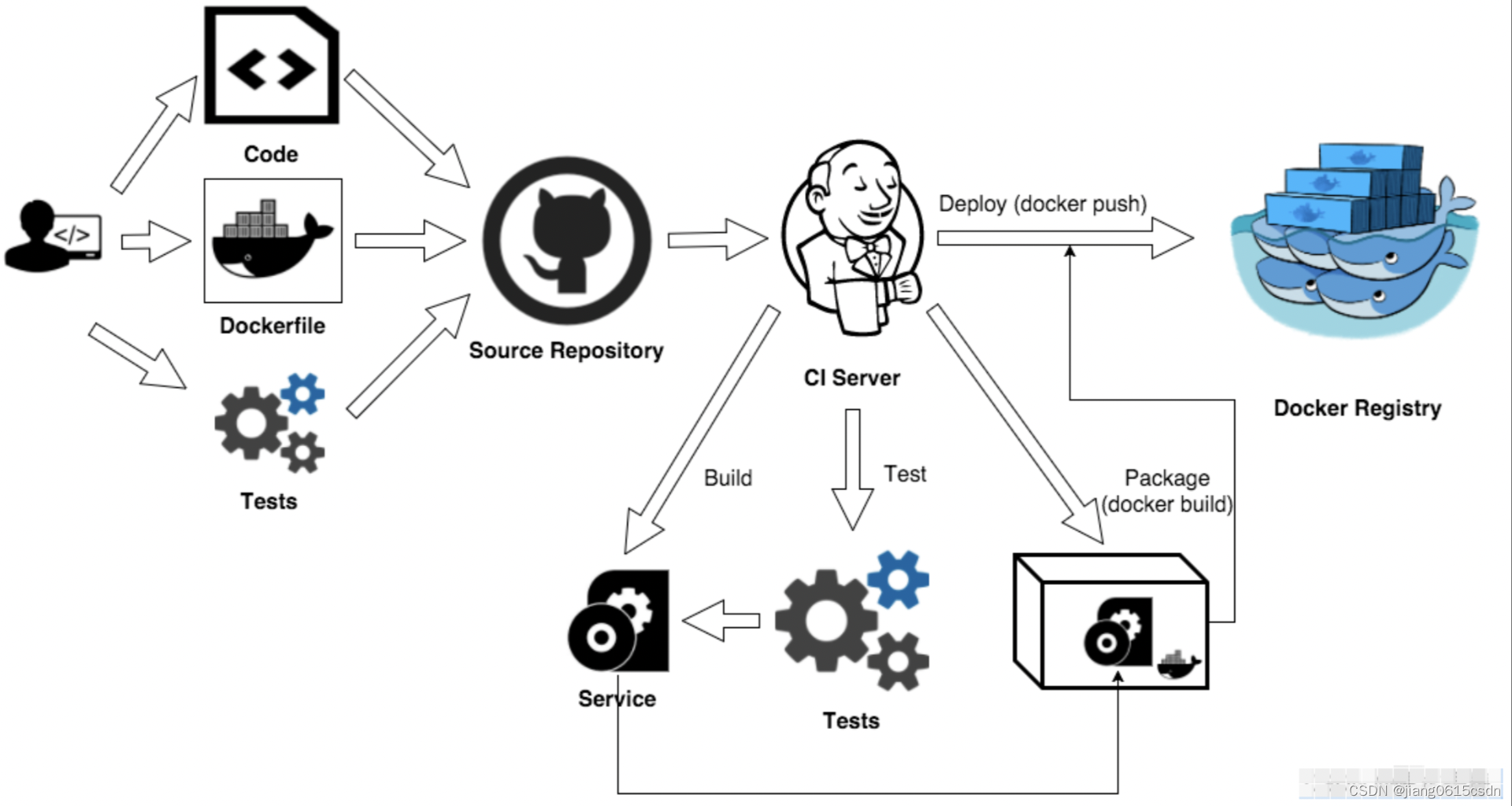
两种微调范式:增量预训练和指令微调

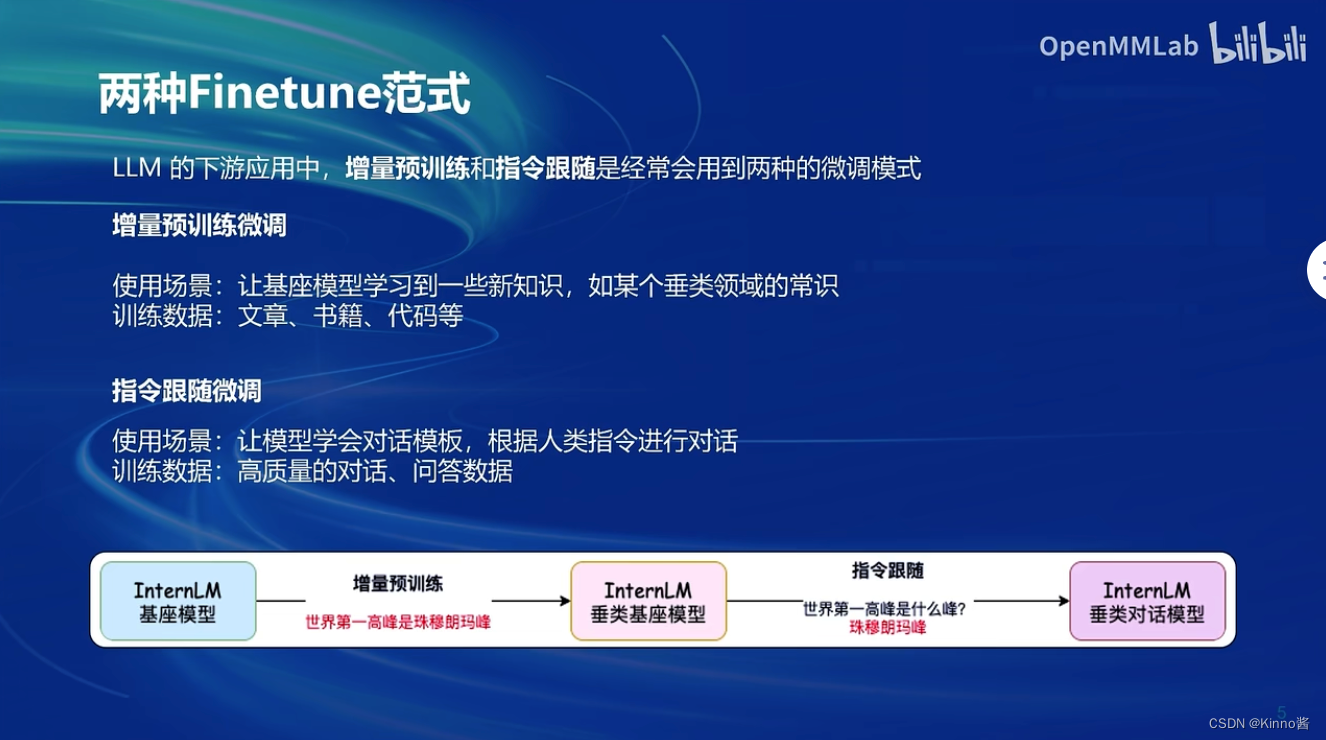
在大语言模型下游应用中,主要有两种微调范式:增量预训练和指令微调。增量预训练旨在让模型学习特定领域的常识,而不需要有监督标注的数据;指令微调则是通过高质量的对话数据训练模型,使其能够根据人类指令进行对话并输出符合人类喜好偏好的内容。增量预训练的使用场景是在已有基础模型上,增加新的领域知识训练数据,如文章、书籍或代码等,无需问答对标注。指令微调则需要高质量的问答对或对话数据,以便模型能根据实际问题回答内容。
如何理解增量预训练和指令微调的区别?
增量预训练时,模型只接收简单的问题数据(如“珠穆朗玛峰是世界第一高峰”),无法识别提问意图;而指令微调阶段,模型通过问答对数据能理解问题,并能回答相关问题(如“什么是肺癌”)。
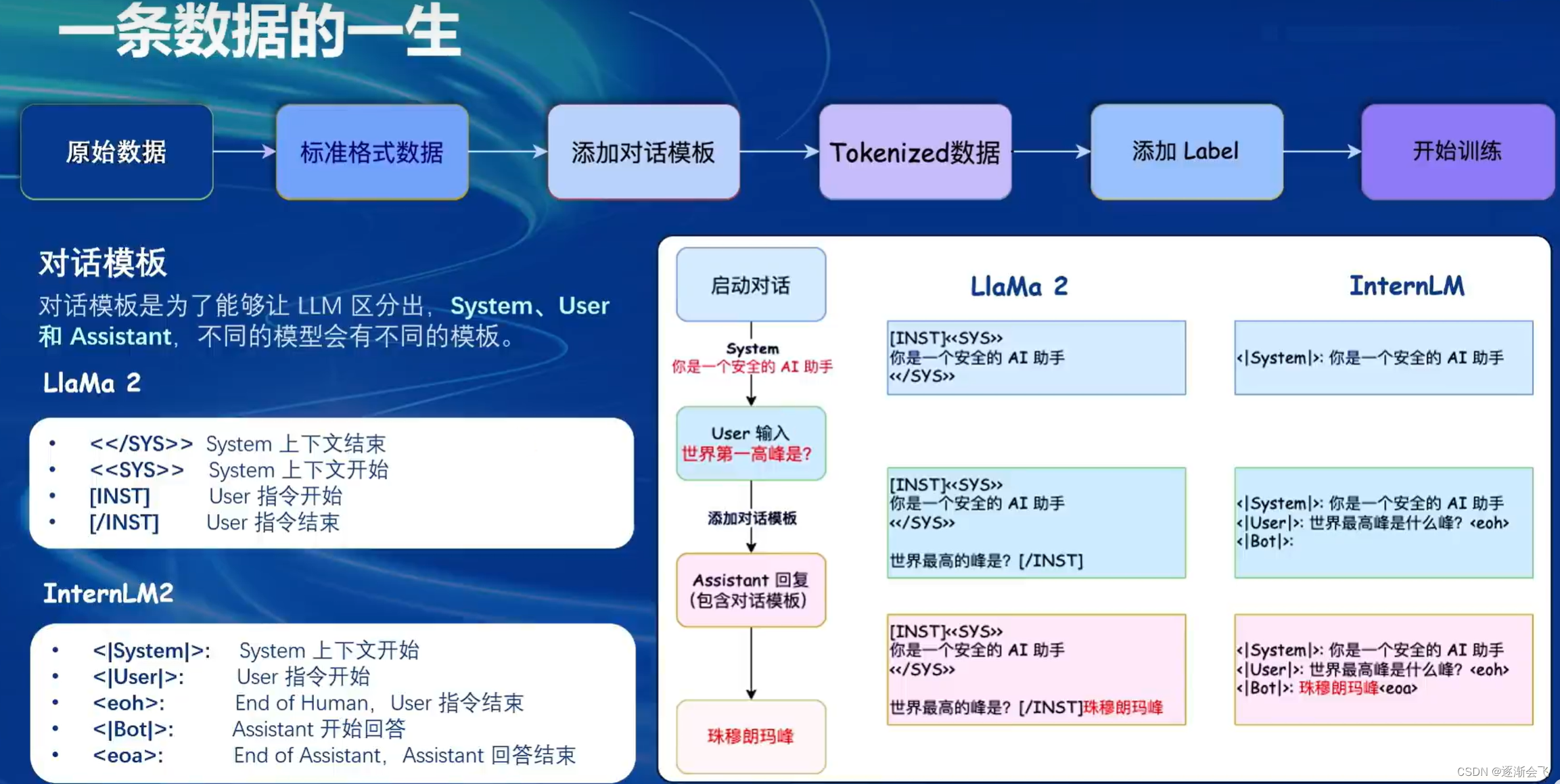
微调方案:
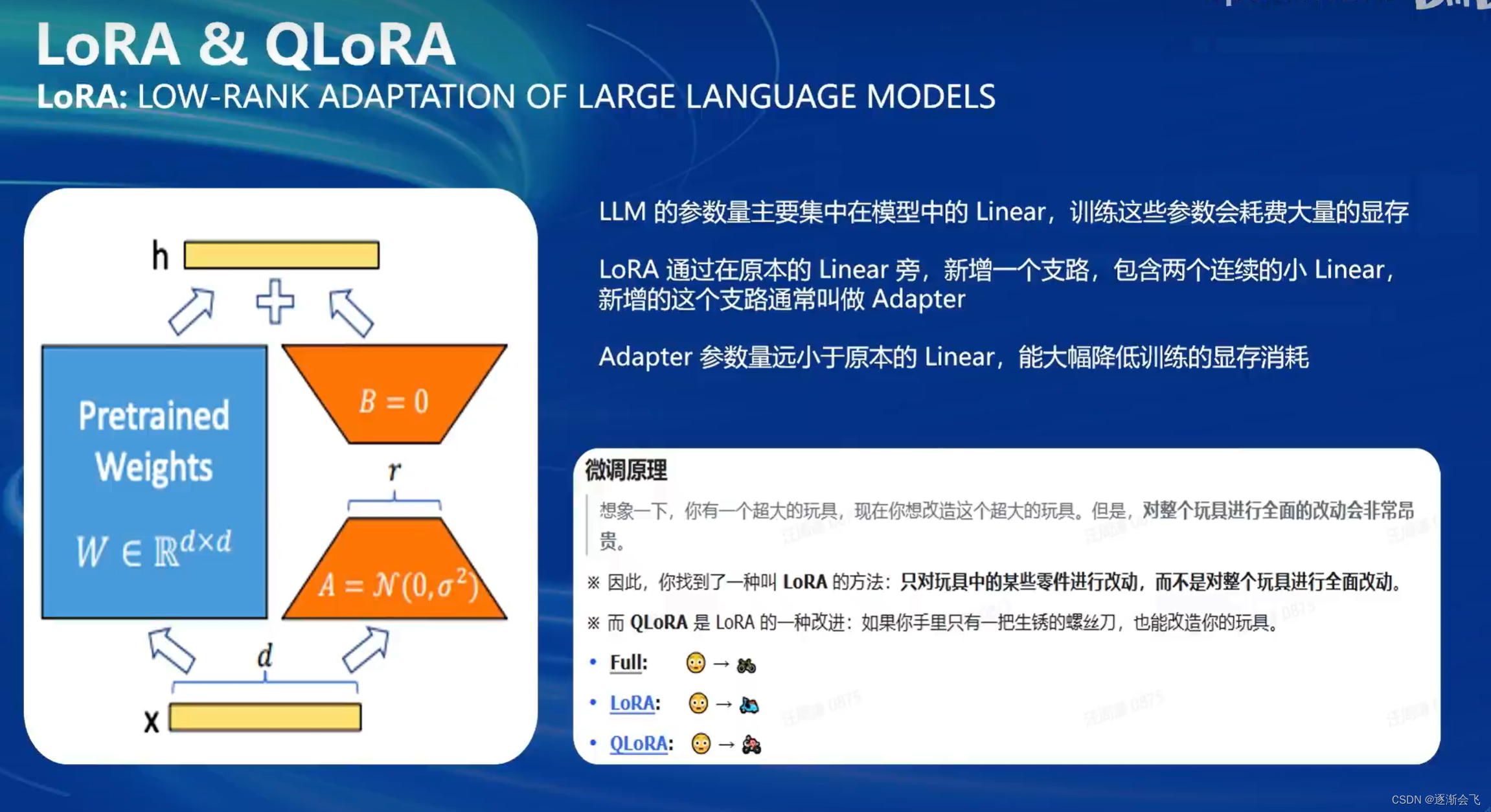
LORA微调利用一种名为“lora”的方法,在优化模型时仅对部分关键参数进行改动,避免对整个模型的所有部位进行大规模改动,从而大大减少了显存占用和计算成本。
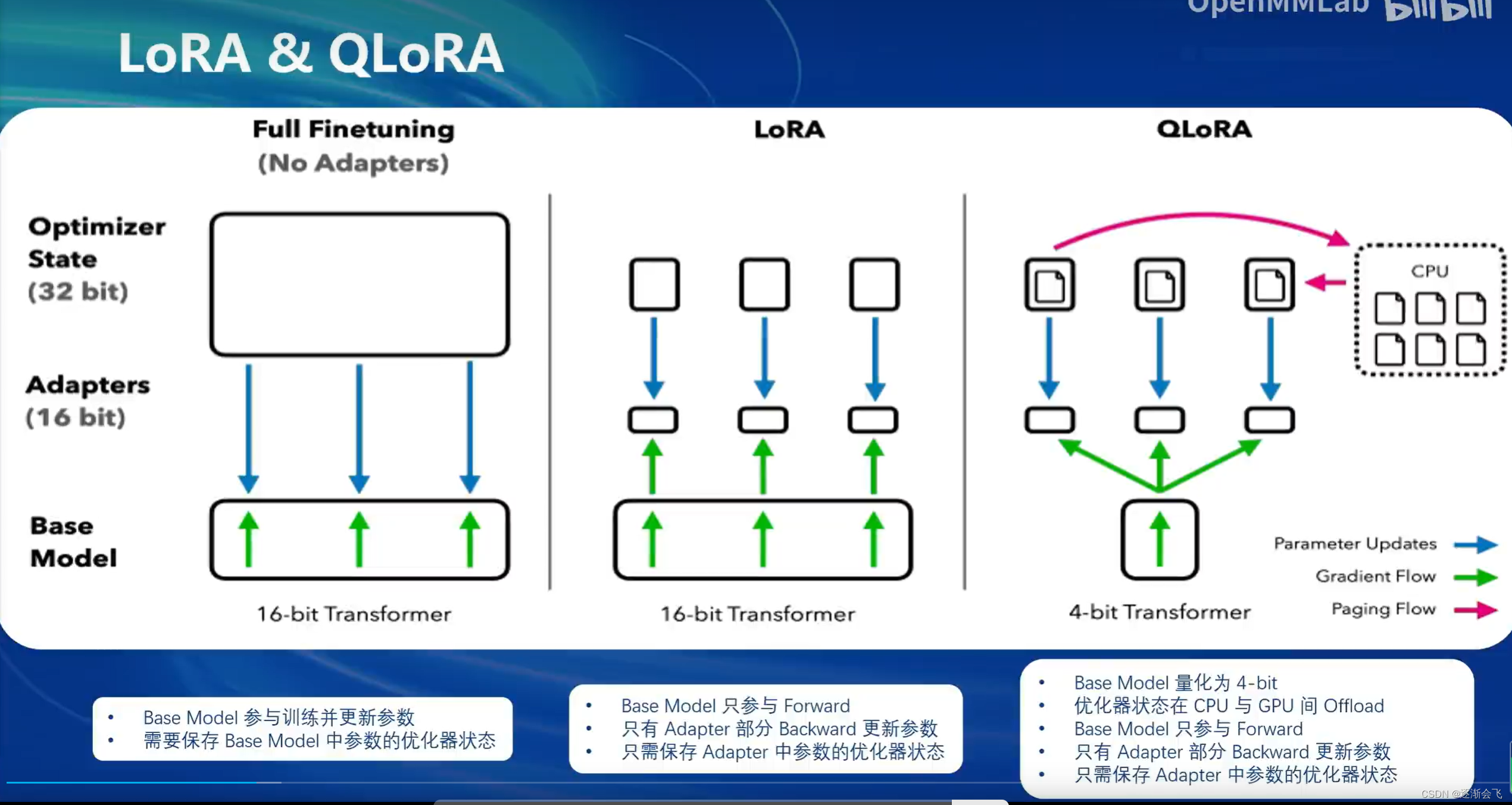

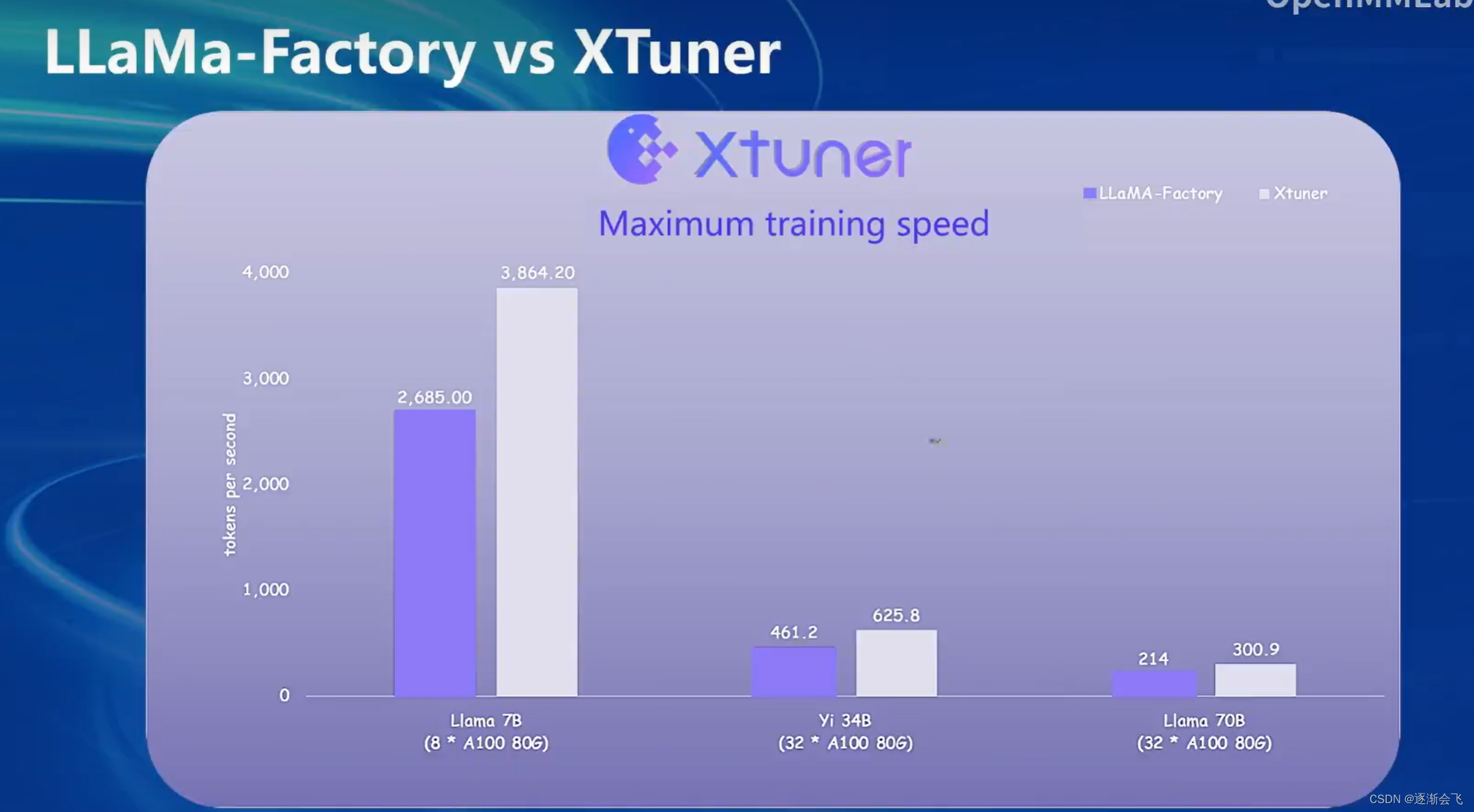
步骤:
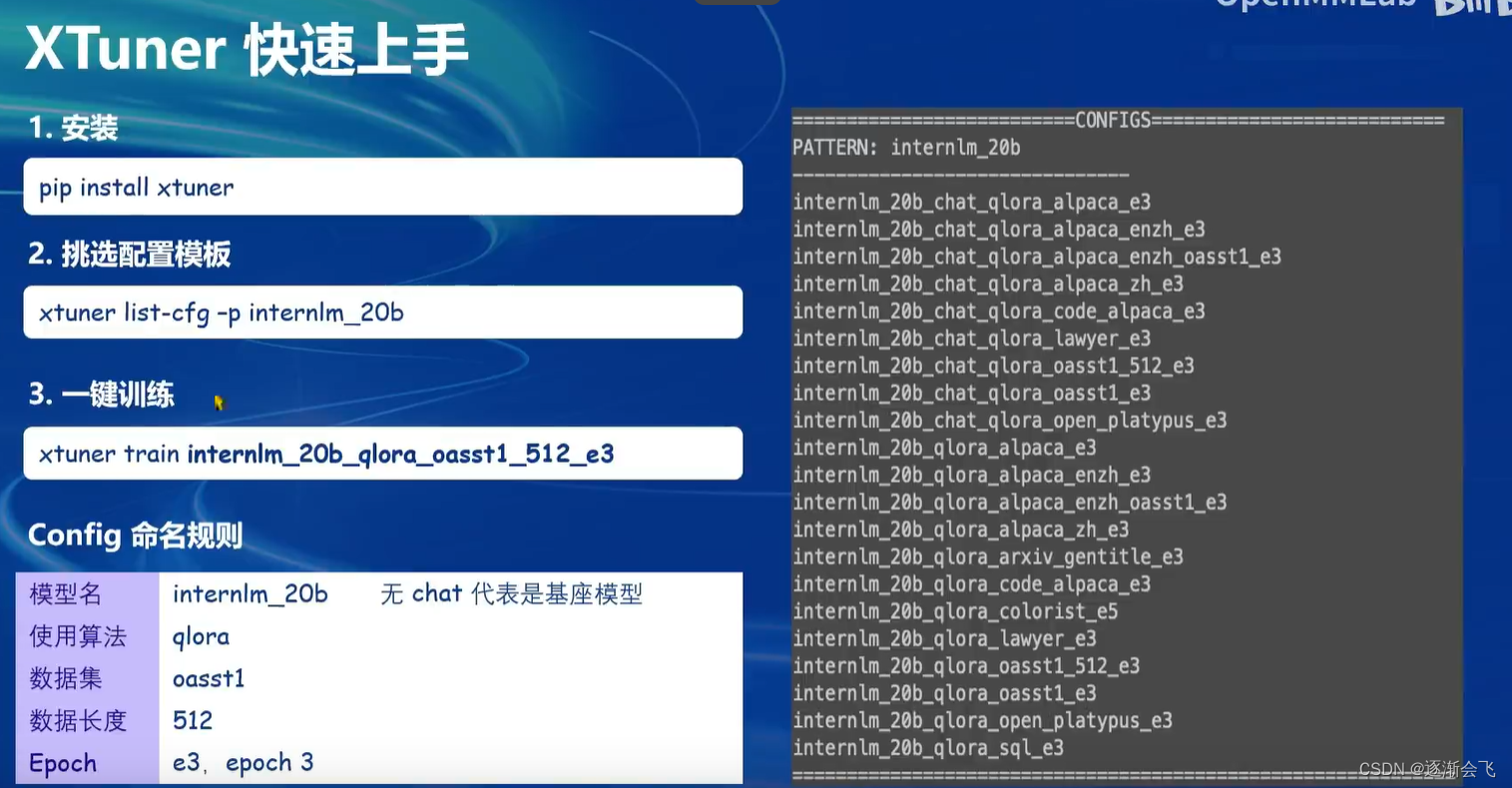


XTuner还支持工具类模型的对话,更多详见HuggingFace Hub(xtuner/Llama-2-7b-qlora-moss-003-sft)

InternLM2-1.8B 提供了三个版本的开源模型,大家可以按需选择。
·
- InternLM2-1.8B:具有高质量和高适应灵活性的基础模型,为下游深度适应提供了 良好的起点。
- InternLM2-Chat-1.8B-SFT:在 InternLM2-1.8B 上进行监督微调(SFT)后得到的 对话模型。
- InternLM2-Chat-1.8B:通过在线 RLHF 在 InternLM2-Chat-1.8B-SFT 之上进
一步对齐。InternLM2-Chat-1.8B表现出更好的指令跟随、聊天体验和函数调用,推荐下游应用程序使用。(模型大小仅为3.78GB)
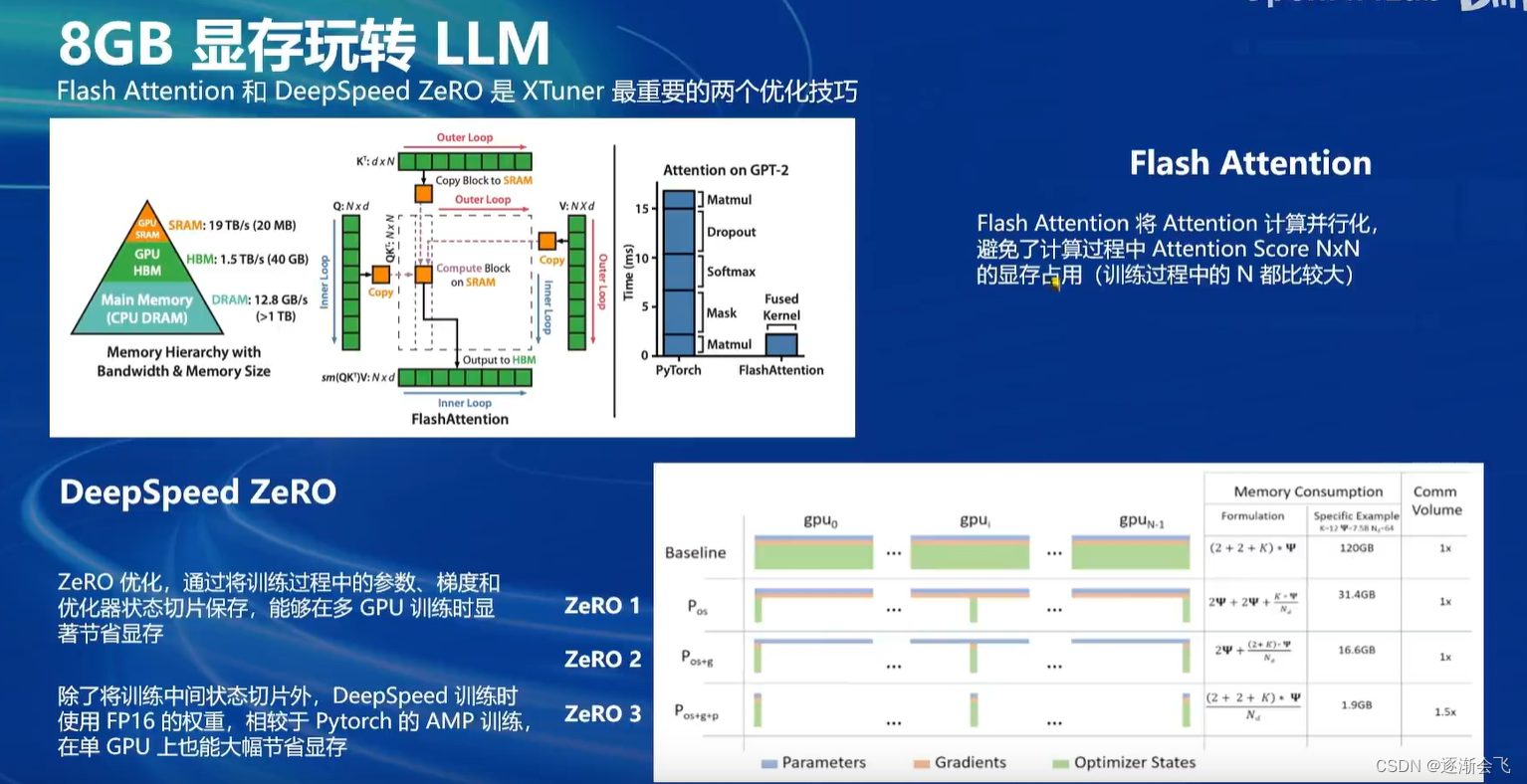
在 FP16 精度模式下,InternLM2-1.8B仅需4GB显存的笔记本显卡即可顺畅运行。
拥有8GB显存的消费级显卡,即可轻松进行1.8B模型的微调工作。如此低的硬件门槛,非常适合初学者使用,以深入了解和掌握大模型的全链路。
多模态大语言模型是如何将文本模型扩展至图像领域的?
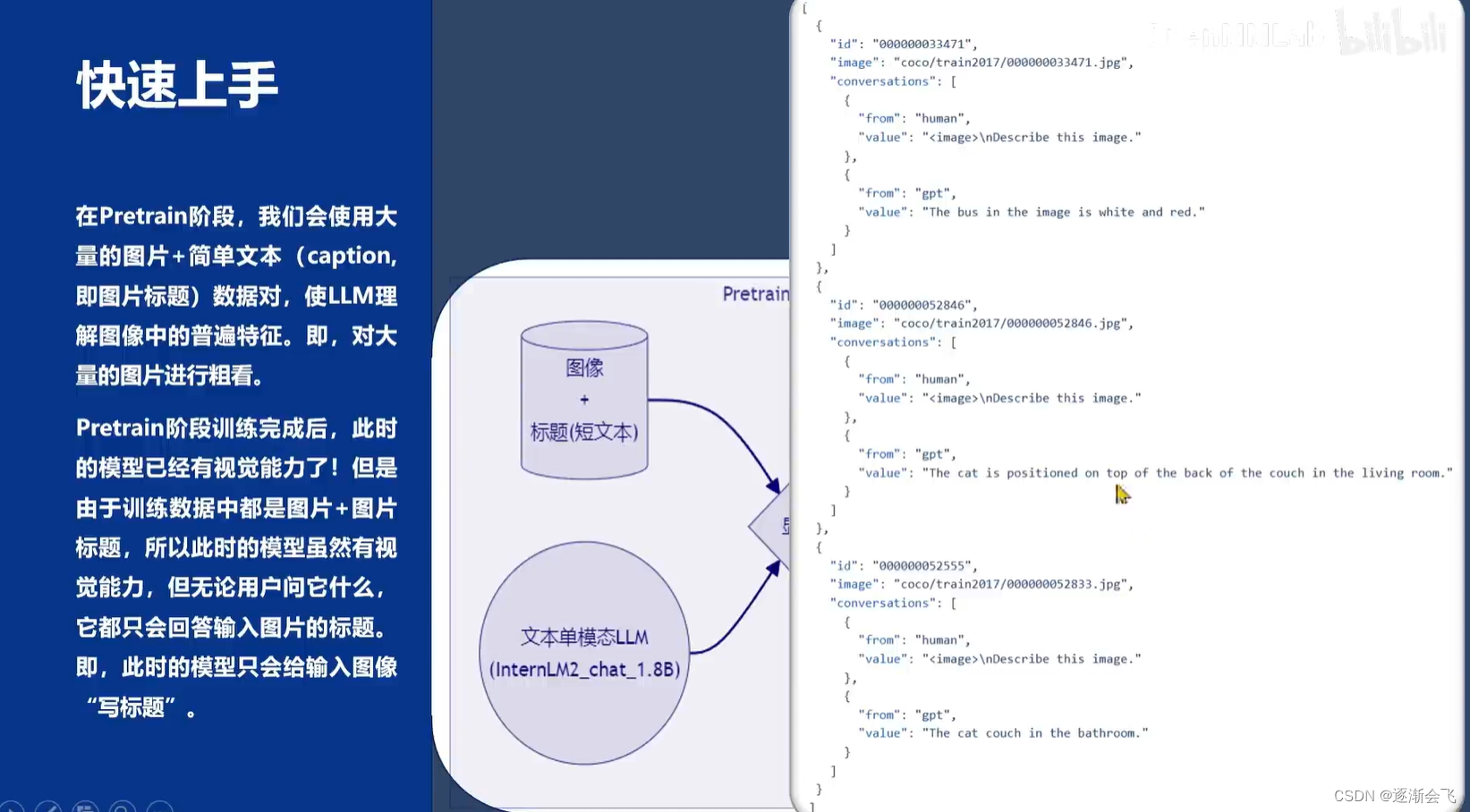
多模态大语言模型通过将单模态文本大语言模型(如LLM)与图像处理模块结合,实现了对图像的处理和理解。训练阶段,利用文本问答数据和图像向量作为输入,输出文本回答,从而训练出一个能够处理图像的模型(image projector)。在测试阶段,将已训练好的image projector与单模态文本模型组合,实现了多模态的视觉功能。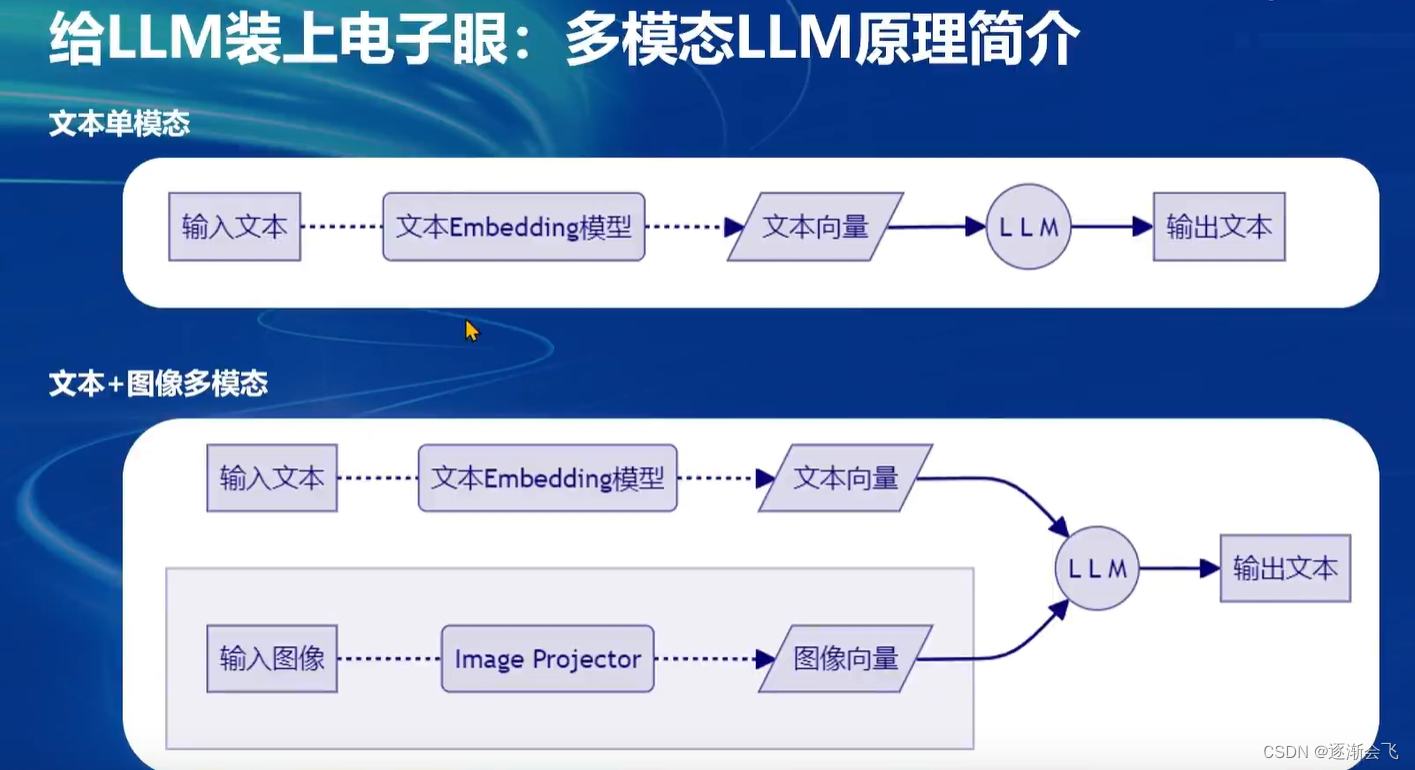
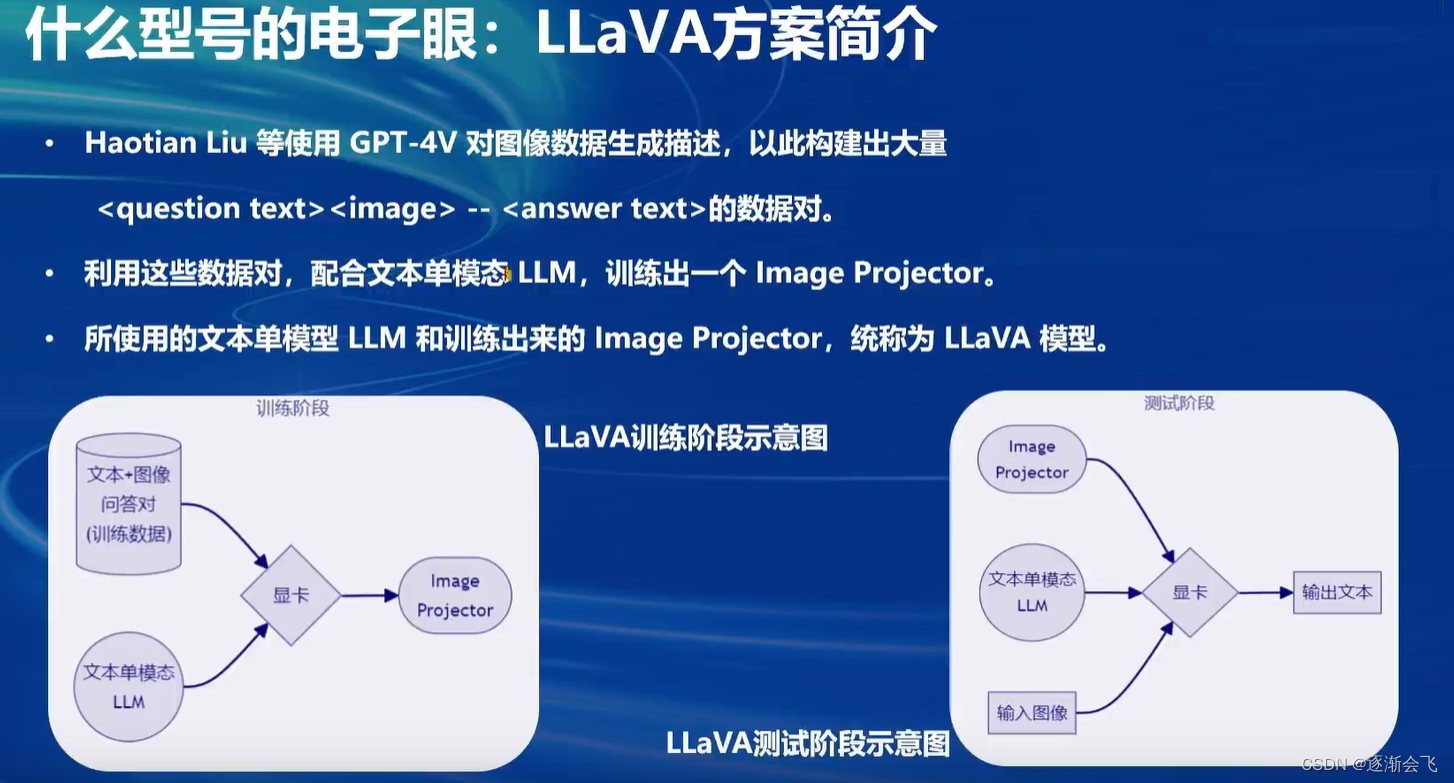
单模态单元模型如何加载到显卡并进行图像问题预测?图像项目(image project)训练是如何赋予大语言模型视觉能力的?
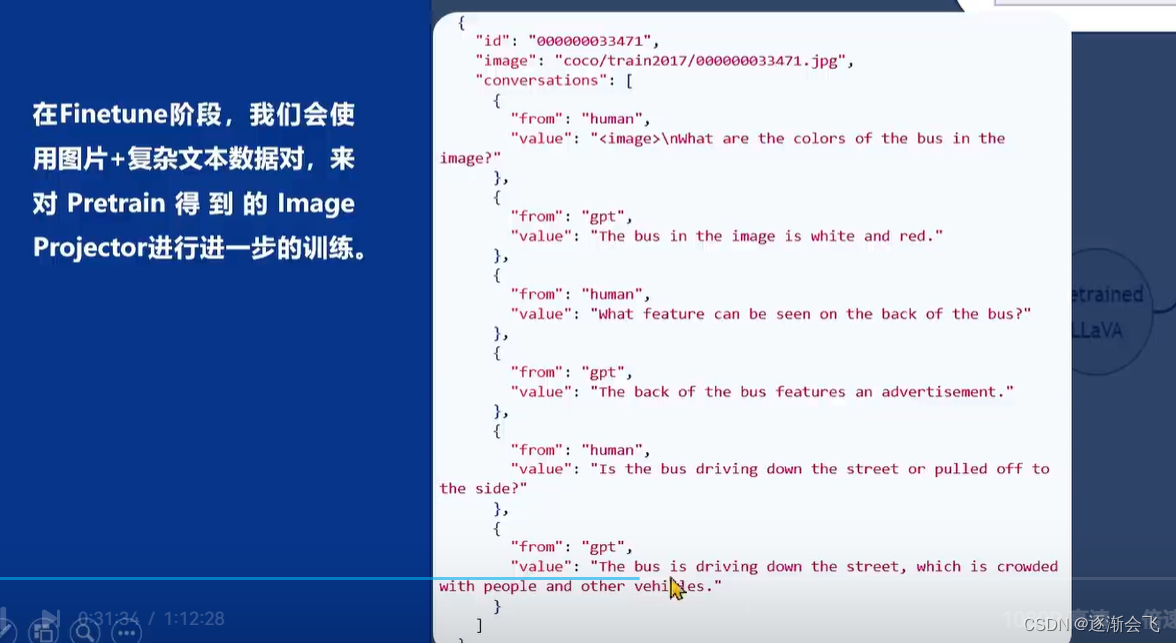
在单模态单元模型加载到显卡后,输入图像及用户问题,模型会输出预测文本。这类似于之前提到的lora微调方案,两者都是在已有的大语言模型基础上,用新数据训练出一个新的小型模型。图像项目训练分为两个阶段:pretrain阶段和Finetune阶段。pretrain阶段大量使用图像及其标题数据(不一定都是问题,可能是描述或标签)让单模态文本模型快速了解图像普遍特征。而Finetune阶段则是在显卡中使用高质量图像加复杂对话文本的数据对模型进行进一步训练,类似于指令微调,最终得到具有视觉识别能力的模型。
作业:
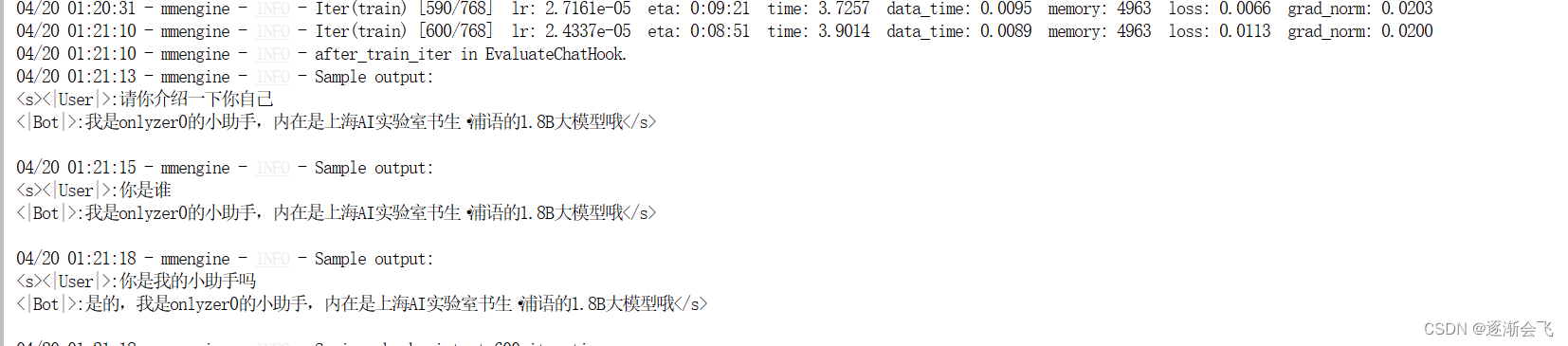
训练自己的小助手认知
数据格式,角色+问答

微调开始过程

后面逐渐成功了:
web页面:

导出
conda list -e > requirements.txt
部署:
参考:https://github.com/InternLM/Tutorial/tree/camp2/tools/openxlab-deploy
需要先进入仓库,才能标记大文件
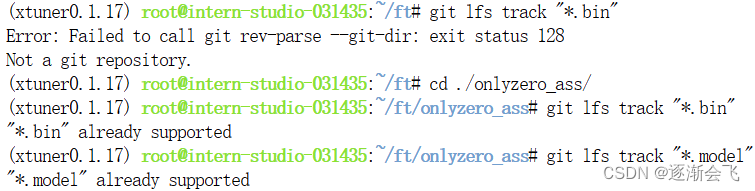
用户名应该写密钥管理的
否则无法上传
已经上传
部署成功
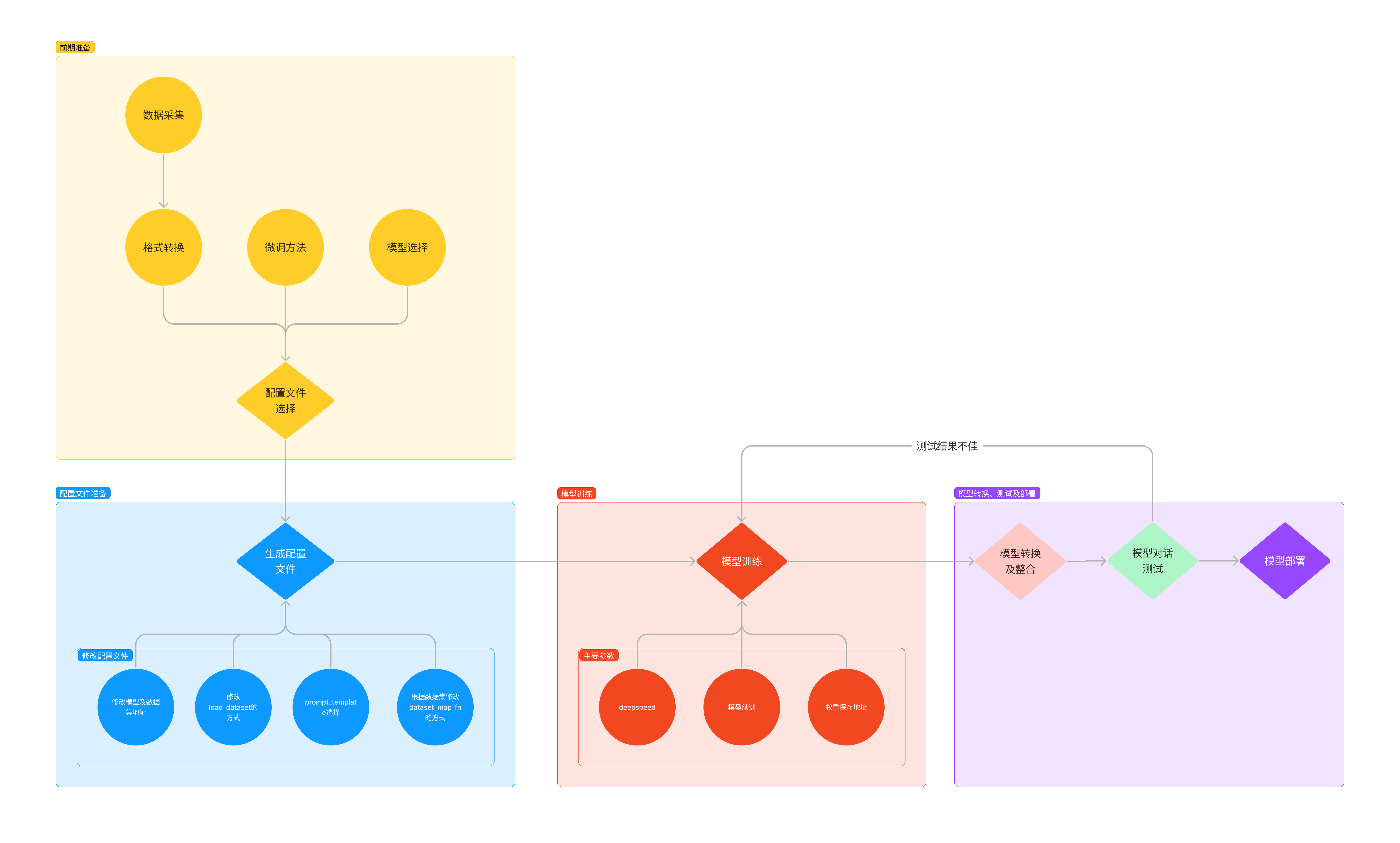
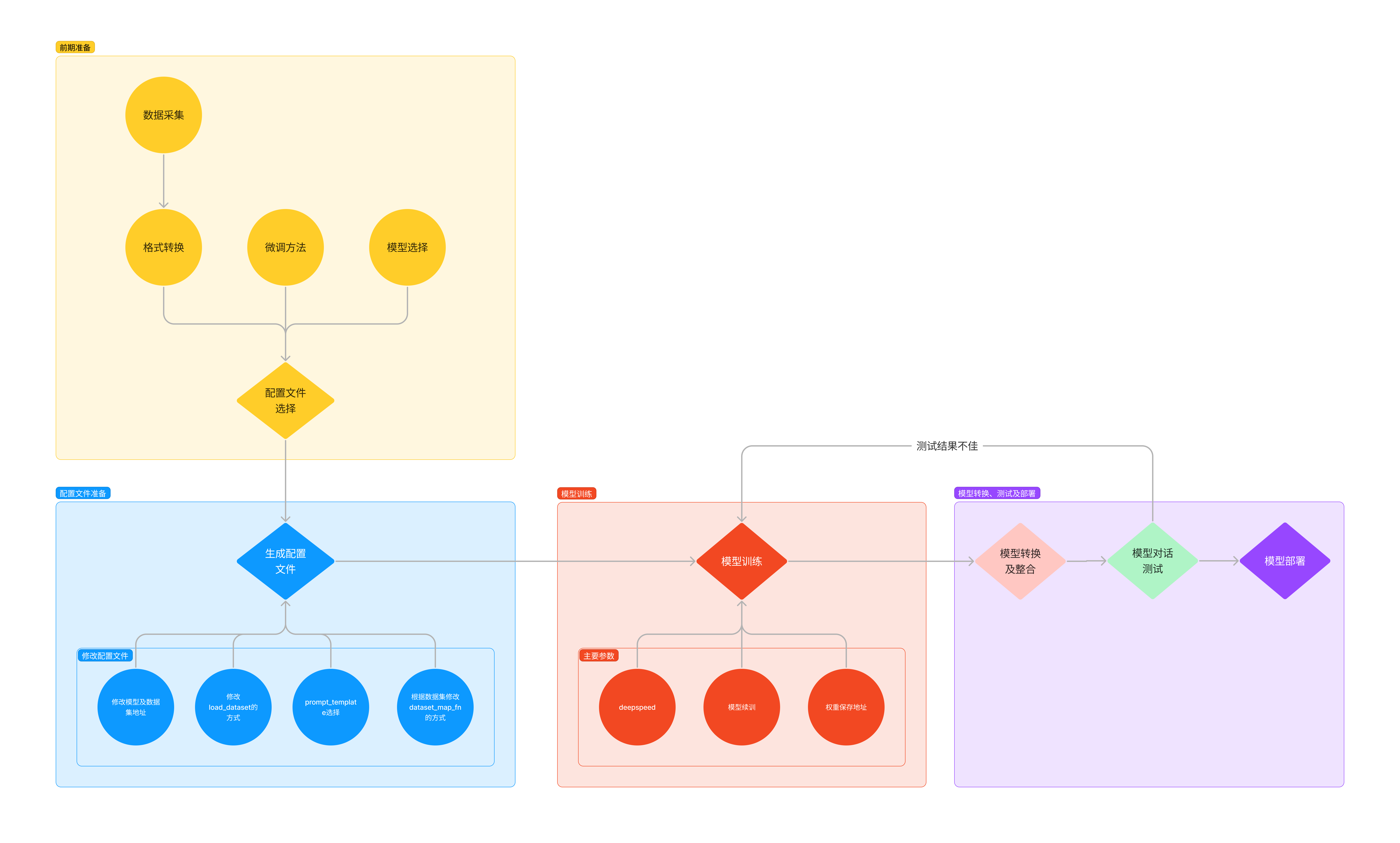
总体大致步骤:
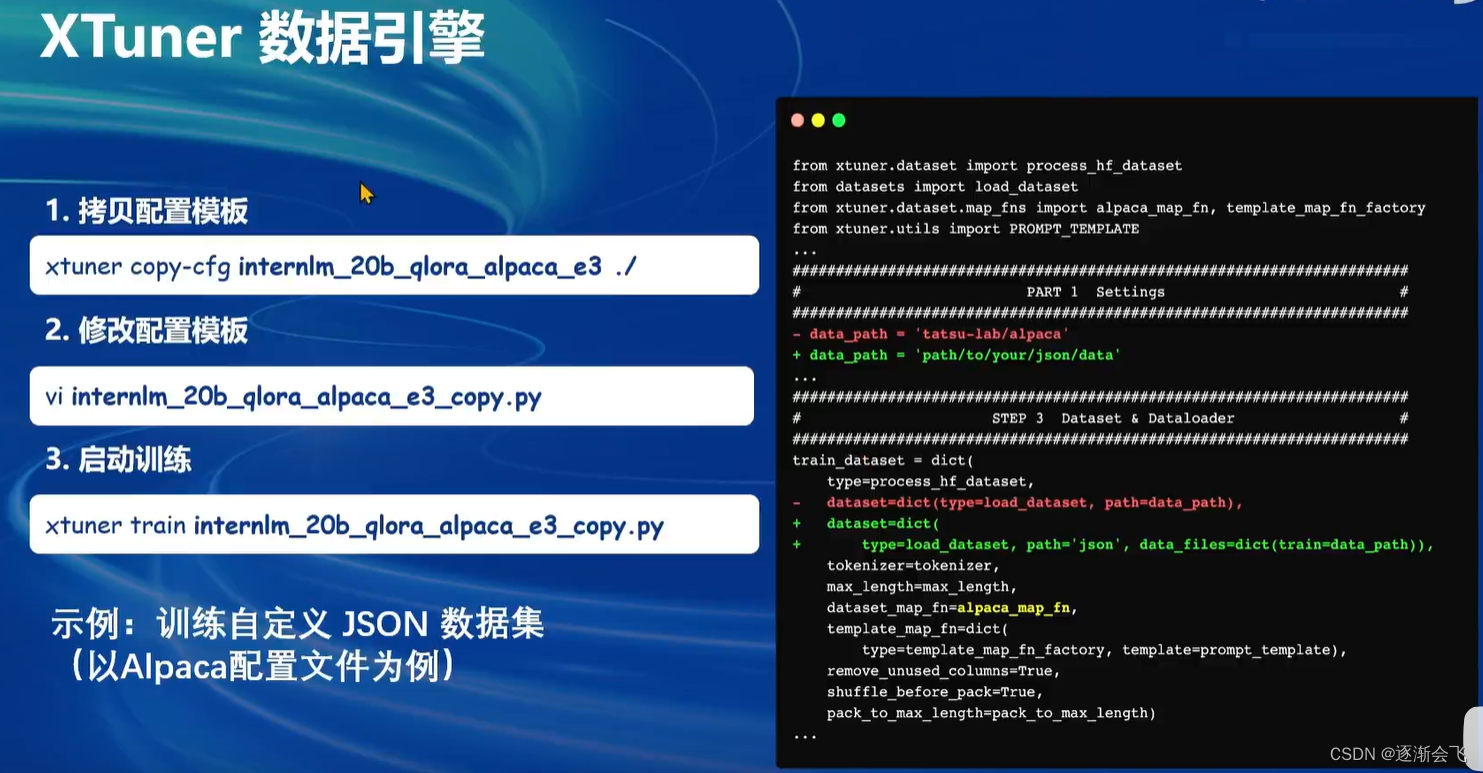
- 我们首先是在 GitHub 上克隆了 XTuner 的源码,并把相关的配套库也通过 pip 的方式进行了安装。
- 然后我们根据自己想要做的事情,利用脚本准备好了一份关于调教模型认识自己身份弟位的数据集。
- 再然后我们根据自己的显存及任务情况确定了使用 InternLM2-chat-1.8B 这个模型,并且将其复制到我们的文件夹里。
- 我们在 XTuner 已有的配置文件中,根据微调方法、数据集和模型挑选出最合适的配置文件并复制到我们新建的文件夹中。
- 使用xTuner微调后,将微调结果合并至原模型
多模态agent
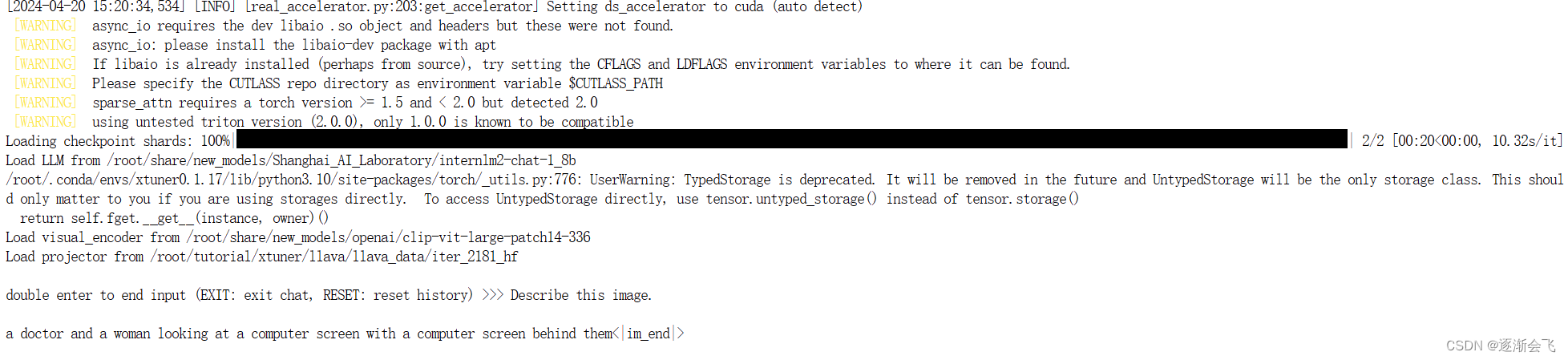
Finetune前
即:加载 1.8B 和 Pretrain阶段产物(iter_2181) 到显存。
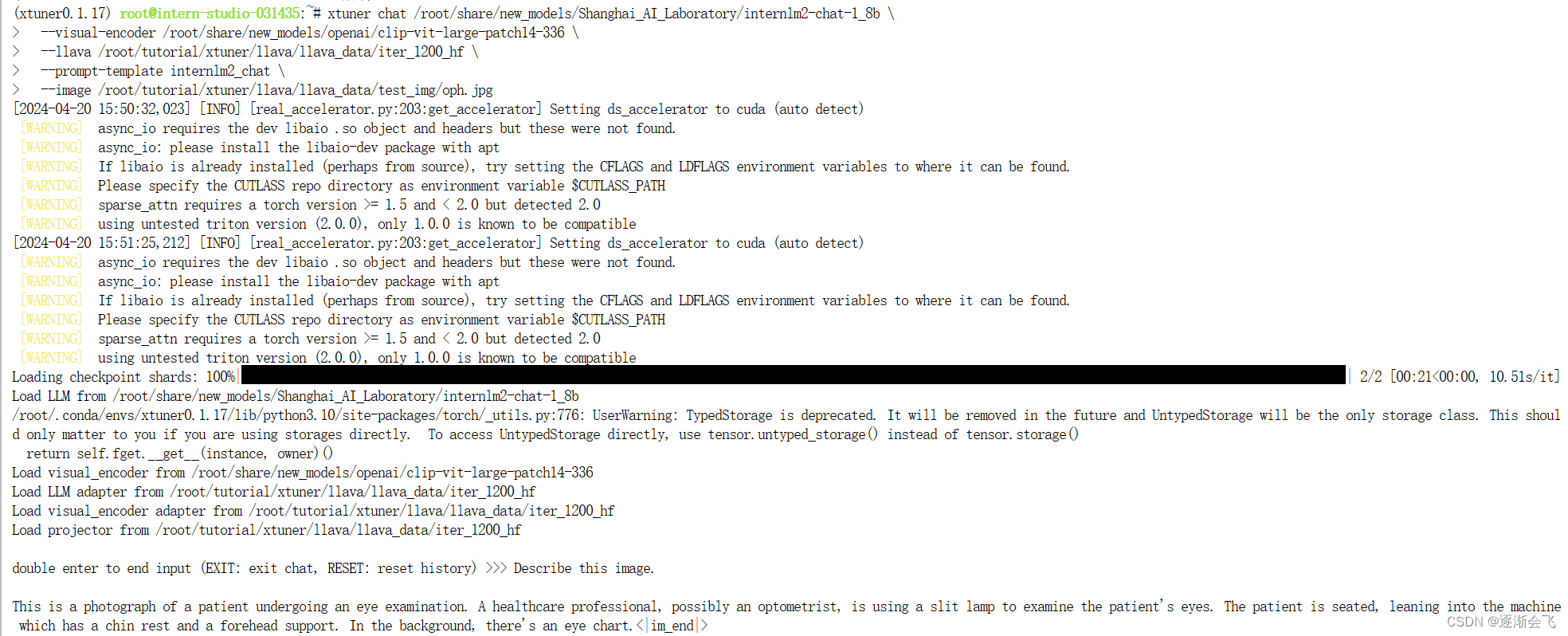
Finetune后
即:加载 1.8B 和 Fintune阶段产物 到显存。


![[InternLM训练营第二期笔记]4. <span style='color:red;'>XTuner</span> <span style='color:red;'>微调</span> <span style='color:red;'>LLM</span>:1.8<span style='color:red;'>B</span>、<span style='color:red;'>多</span><span style='color:red;'>模</span><span style='color:red;'>态</span>、<span style='color:red;'>Agent</span>](https://img-blog.csdnimg.cn/direct/57e34f733ca44480a76ca2d2a28ad5d8.png)