目录
上一个算法:浅谈数据挖掘(1)-BOW算法-CSDN博客
下一个算法:关联分析算法-Apriori算法-CSDN博客
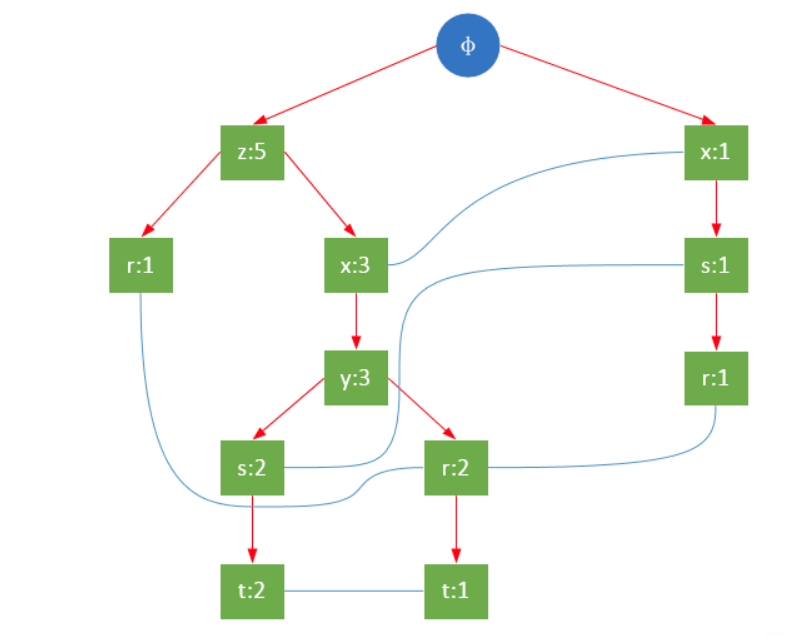
举个栗子:
一个人是否能够的到一个offer可能取决于:年龄,专业,表达能力,人际交往能力(如下所示)

据此,绘制决策树:
紫色结点划分依据,构成划分的属性集
提出目标
找到这么一组属性集,尽量使得划分到的样本属于同一类,换而言之,找到的"划分"使类越"纯粹"越好.
这就遇到了决策树的问题?
1如何找到划分?
2如何衡量样本的纯粹程度?
选择纯度最高的属性->最能区分/辨别 class 的 feature
引入概念
信息熵(Information Entropy):用于衡量一个系统的信息含量的量化指标
我们把X的信息熵记为H(x).
这里我们先不给出H(x)的公式,我们先清楚H(x)的应该具有的性质:
(1)单调性:发生概率越高的事件,其携带的信息量越少(越容易发生的事件发生了,这是很正常的事情,所以他能提供的信息很少)
(2)非负性:H(x)是对x的一种度量,要求非负是很正常的一件事情
(3)累加性:多个随机事件同时发生,总不确定性度量等于各事件不确定性的度量之和
即:
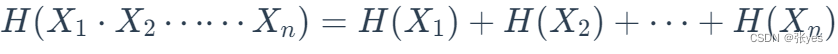
而香农证明了,满足上述性质的随机变量的函数具有以下特征:
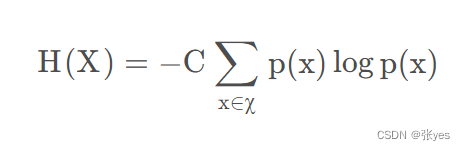
取C=1,即可得到样本信息熵:

对于样本集为:
![]()
这一共把D分为了n类,每一类对应的概率分别为:
![]()
这里样本集D的信息熵为:
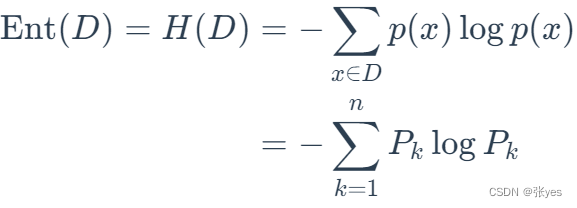
如果 Ent(D)的值越小,则其信息量越小,即样本即D越"纯"
这里是不是对决策树的问题解决有点眉目了?根据某种划分,最小化Ent(D),这里的划分就是我们所需要的属性集!
顺着这个思路,我们再来定义一个量:
信息增益(Information Gain):
假定离散属性有V个可能取值
![]()
如果用特征a去划分数据集D,会产生V个分支结点,其中第v个结点包含了数据集中所有在特征a上取值为av的样本总数即为Dv,若考虑到不同分支节点包含样本数量不同v,对Ent(Dv)有很大的影响(有理由认为v越大,Ent(Dv)越大).所以我们需要对其进行加权计算:
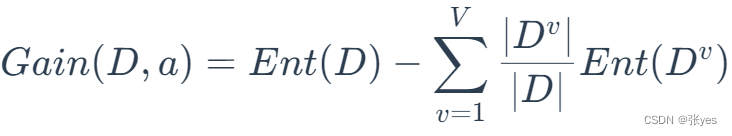
这样我们就以以划分a划分D时所得到的信息增益.我们要最小化Ent(Dv),当然等价于最大化信息增益.并且最大的信息增益所对应的划分a即为我们所需要的属性集.
ID3算法实现
ID3算法的思路就如上所示:
ID3算法的核心是根据信息增益来选择进行划分的特征,然后递归地构建决策树
算法步骤:
从根节点开始,计算所有可能的特征的信息增益,选择信息增益最大的特征作为节点的划分特征;
由该特征的不同取值建立子节点;
再对子节点递归1-2步,构建决策树;
直到没有特征可以选择或类别完全相同为止,得到最终的决策树。
代码实现
# -*- coding: utf-8 -*-
# 导入所需库
import numpy as np
import pandas as pd
# 定义计算信息熵的函数
def entropy(data):
labels = data.iloc[:, -1].value_counts()
prob = labels / len(data)
entropy = np.sum(-prob * np.log2(prob))
return entropy
# 定义计算信息增益的函数
def info_gain(data, feature):
entropy_total = entropy(data)
values = data[feature].value_counts().index
entropy_feature = 0
for value in values:
data_sub = data[data[feature] == value]
prob = len(data_sub) / len(data)
entropy_feature += prob * entropy(data_sub)
info_gain = entropy_total - entropy_feature
return info_gain
# 定义构建决策树的函数
def build_tree(data):
# 如果数据集中所有实例属于同一类,则返回该类
if len(set(data.iloc[:, -1])) == 1:
return data.iloc[:, -1].iloc[0]
# 如果数据集中没有特征,则返回实例数最多的类
if len(data.columns) == 1:
return data.iloc[:, -1].value_counts().idxmax()
# 计算所有特征的信息增益
info_gains = {}
for feature in data.columns[:-1]:
info_gains[feature] = info_gain(data, feature)
# 选择信息增益最大的特征作为节点的划分特征
best_feature = max(info_gains, key=info_gains.get)
tree = {best_feature: {}}
# 由划分特征的不同取值建立子节点
for value in data[best_feature].value_counts().index:
subtree = data[data[best_feature] == value].drop(columns=[best_feature])
tree[best_feature][value] = build_tree(subtree)
return tree
# 测试代码
if __name__ == '__main__':
data = pd.DataFrame({'Outlook': ['Sunny', 'Sunny', 'Overcast', 'Rainy', 'Rainy', 'Rainy', 'Overcast',
'Sunny', 'Sunny', 'Rainy', 'Sunny', 'Overcast', 'Overcast', 'Rainy'],
'Temperature': ['Hot', 'Hot', 'Hot', 'Mild', 'Cool', 'Cool', 'Cool',
'Mild', 'Cool', 'Mild', 'Mild', 'Mild', 'Hot', 'Mild'],
'Humidity': ['High', 'High', 'High', 'High', 'Normal', 'Normal', 'Normal',
'High', 'Normal', 'Normal', 'Normal', 'High', 'Normal', 'High'],
'Windy': ['No', 'Yes', 'No', 'No', 'No', 'Yes', 'Yes',
'No', 'No', 'No', 'Yes', 'Yes', 'No', 'Yes'],
'PlayTennis': ['No', 'No', 'Yes', 'Yes', 'Yes', 'No', 'Yes',
'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No']})
decision_tree = build_tree(data)
print("决策树:", decision_tree)参考资料:
机器学习算法之决策树(decision tree)-CSDN博客为什么香农要将信息熵公式要定义成 -Σp·log₂(p) 或 -∫p·log₂(p)dp? - 知乎信息熵及其相关概念-CSDN博客