相关资料
(1)What are Recurrent Neural Networks? | IBM
(2)浅析循环神经网络(RNN)的反向求导过程 - 知乎 (zhihu.com) 总共有四篇
(3)循环神经网络(RNN)浅析 - 简书 (jianshu.com)
引入
简单燃烧下卡路里
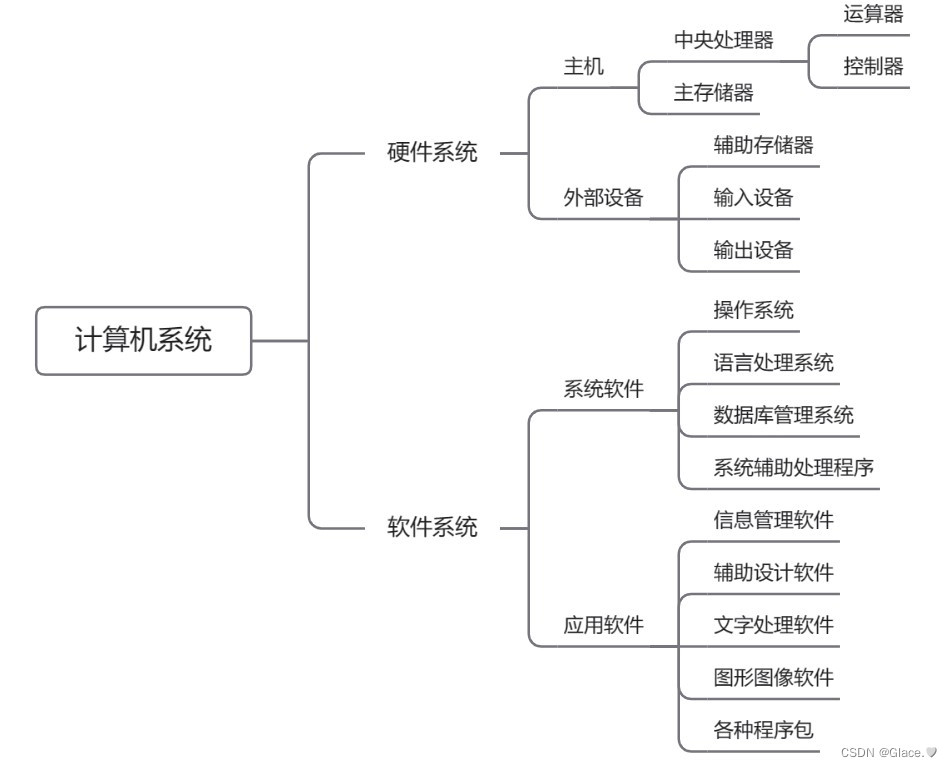
在深度学习中最基础也是最经典的三种分别是前馈神经网络(FNN)、卷积神经网络(CNN)、循环神经网络(RNN)。前馈神经网络最为简单易懂,通过参数传递和矩阵运算将数据从一个维度映射到另外一个维度。而卷积神经网络可以综合某个元素周围的元素进行映射。但是两者都不能够很好地去处理时间序列的问题,而循环神经网络 RNN (Recurrent neural networks) 则可以很好地处理这样的数据。这是因为,相比于前两者来说,RNN 假定输入的数据序列在时间维度上并不是等价的,而是有区分的。
比如现在我们想用神经网络处理行人的运动轨迹,如果我们用卷积神经网络,那么对于不同时间的轨迹数据,卷积权重都是一样的。这样可能会带来一定的问题,比如随着时间推移,一个人会变得越来越疲惫,那么其行动轨迹肯定与一开始的行动轨迹有很大区别。比如我们举下面一个例子:现在有个人在家 (home)和公园 (park)之间跑步进行锻炼,他往公园跑的时候体力比较充沛,所以跑的速度比较快。虽然他在公园休息了一会,跑回家的时候他还是逐渐体力不支速度逐渐变慢下来。
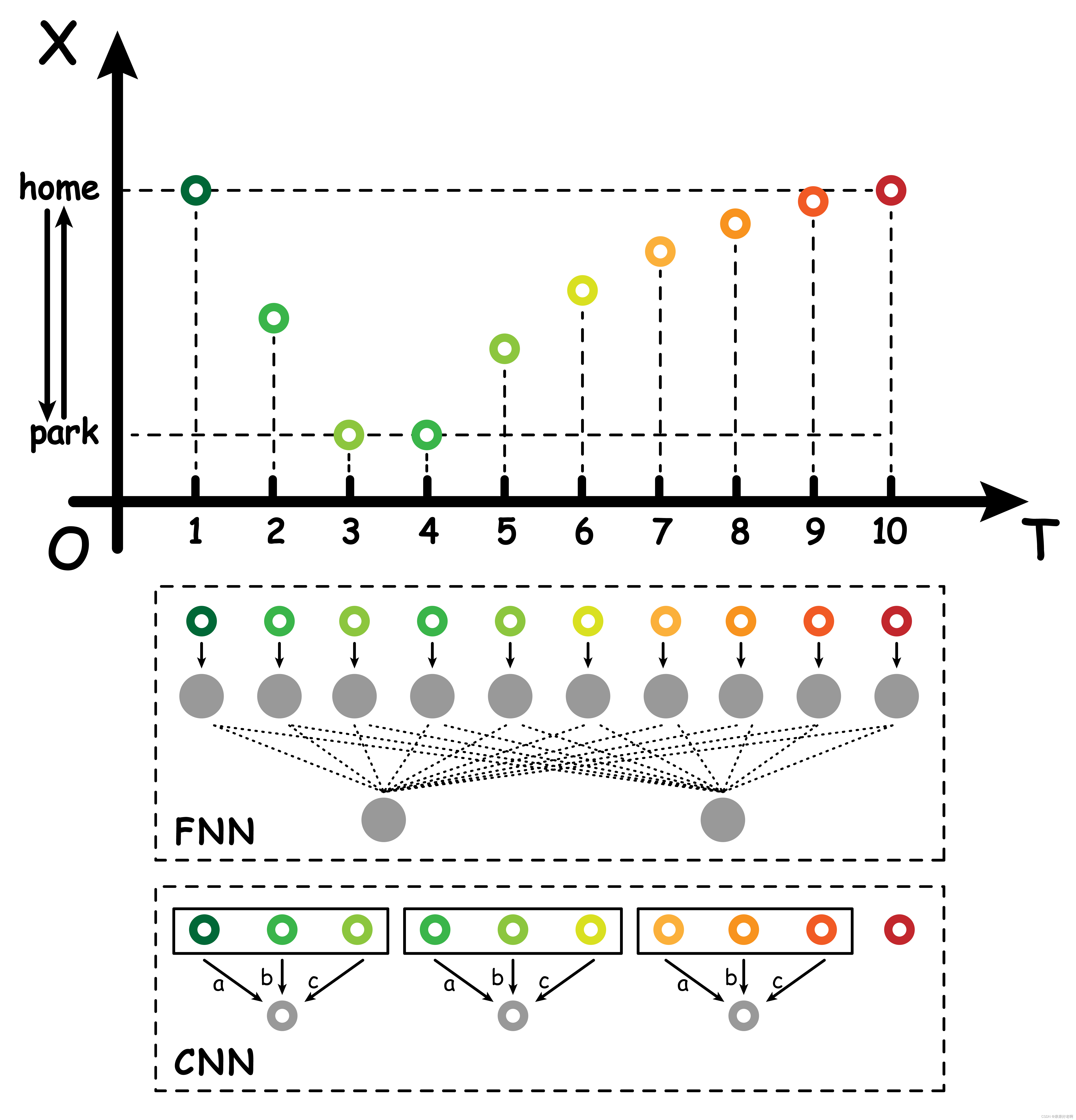
如果我们用 FNN 前馈神经网络去处理,那么我们需要让每个权重自己去学习参数,很容易忽略权重之间的关联性;如果我们用 CNN 卷积神经网络去处理,那么对于这个人精力充沛时候的运动数据和逐渐疲倦时候的运动数据处理的卷积权重参数都是一样的,过于将不同数据关联化(或者说是强行将所有数据等价化)。所以我们需要一种新的神经网络传递方式去处理这类数据。通过观察不难发现,这一系列运动数据之间是有关联的。比如当跑到公园之后才会休息;跑到公园消耗了很多体力之后,回来的跑步速度才会越来越慢 · · · · · · 这说明随着时间的发展,轨迹数据之间是有关联的。而反过来思考之前主要用于处理图像的 CNN,像素之间虽然确实可能存在潜在的关联,但是宏观角度我们并不清楚他们之间的联系,或者换句话说,图片像素之间的联系是空间维度,而并不是时间维度。
时间维度与空间维度
这个问题对于 RNN 来说其实比较重要,我只从辅助理解 RNN 的角度探讨这一问题,并不会全面而详细的论述其本质根源。为了方便理解,此处我们需要一个假定,我们假定下面说的空间指的是三维及以内的空间,而时间单独作为一个维度。
通常我们很容易区分这两个概念,空间维度就是我们存在的三维空间中,有鲜花有泪水也有那个相伴你一生的人;而时间维度就是看着你慢慢变老。但是当我们拓展一下,讨论广义的时间与空间,两者似乎并没有那么的清晰。比如,现在有一个句子:“你这么年轻怎么睡得着的?”,那么这个句子是更偏向于是存在时间维度
还是空间维度?如果我们从存在角度,这个句子如果写在纸上,那么其确实存在于空间维度,但是从理解角度,我们是从“你”字开始,依次往后看“这么”“年轻”“睡得着”,我们需要之前的汉字,才能辅助理解后面的汉字,乃至整个句子。如果语序发生改变句意很可能就完全不同:“这么年轻怎么睡得着你的?”,嗯,这句话就不太对劲了。
可以发现,无论是时间正向流淌的客观事实(别抬杠超过光速时间逆向),还是人为约定的看句子从左往右从上往下看,都具有时间维度的“特性”。个人认为,这种特性与空间维度区别比较大的一点在于,在时间维度每个时间点上,都有一个较为完整的“空间”。比如你在奔跑,每个时间点上都有一个完整的地球空间,而你正处于某个跑步姿势;比如你在阅读文字,每个字都是完整的一个个体,由它许多笔画组成。而三维空间并不存在时间的概念。此外,在时间维度这条线上,不同时间点的三维空间是相互联系的,尤其是正向关联。跑步变慢是因为之前跑太多消耗了太多精力;一个个单独的字组成了完整的有蕴含的一句话。
基本原理
先从最简单的入手
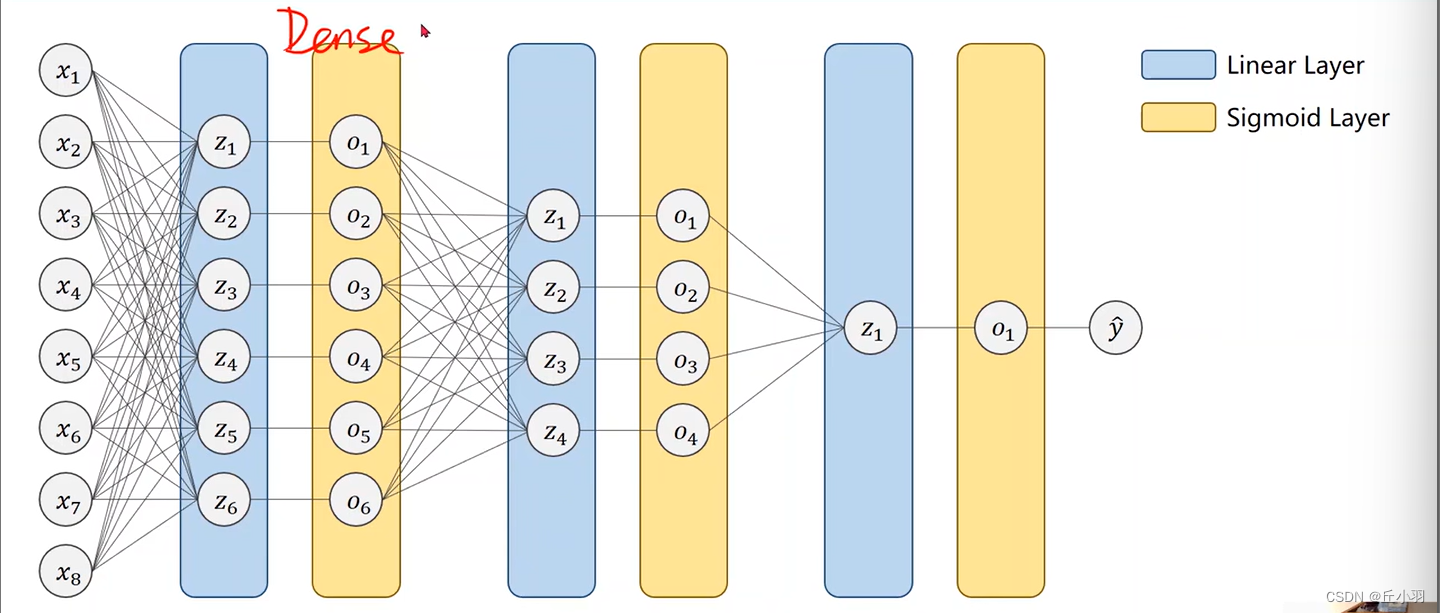
前面提到过,时间序列的正向关联十分重要,也就是上一个时间点对下一个时间点有较大的影响。我们还是以之前的跑步的例子为例。对于 FNN 来说,输入数据是经过一个权重 u 1 u_{1} u1 到隐藏的神经 (灰色)元,再从隐藏的神经元经过另外一个权重 v 1 v_{1} v1 得到输出结果,如下图 (a)。写成公式如下:
o u t p u t = v 1 ⋅ ( u 1 ⋅ t 1 ) output = v_{1}·(u_{1}·t_{1}) output=v1⋅(u1⋅t1)
其中 t 1 t_{1} t1 代表的是该时刻输入的数据。

如果我们希望 t 2 t_2 t2 时刻的输入受到 t 1 t_{1} t1 时刻输入的影响,我们可以将 t 1 t_1 t1 输入的隐藏变量乘以 w 1 w_{1} w1 再输入进 t 2 t_{2} t2 得到的隐藏变量,这样输入就拥有两个时刻输入数据的贡献,如上图 (b)。写成公式如下:
o u t p u t = v 1 ⋅ ( u 2 ⋅ t 2 + w 1 ⋅ ( u 1 ⋅ t 1 ) ) output=v_{1}·(u_{2}·t_{2}+w_{1}·(u_{1}·t_{1})) output=v1⋅(u2⋅t2+w1⋅(u1⋅t1))
有人可能会疑惑,为什么要将两个时刻的隐藏神经元数值相加,而不是直接将输入数据相加?
其实这里的隐藏神经元更像是经过了一种映射或者变换,原数据可能会有一些数量级不匹配等问题,而变成隐藏神经元之后会更加适合相加。
以此类推,我们会得到如图 ©图 (d)的参数传递方式。这样我们就将十个时刻人的跑步数据全部综合起来得到了这个输出结果,这个输出结果包含了完整的跑步位置信息。这就是 RNN 最简单的一种实现方式,其思想就是上文提到时间维度上的正向影响。
高维信息的拓展
上面的例子中,输入数据时各个时刻人跑步的一维位置信息。很明显,这里做了极大地简化。真实的数据可能包括经纬度、速度加速度等等特征,这使得我们输入的数据变成了高维张量。我们对此处理的方式与 FNN 相类似,即将一个单一的元素(如下图 (a))转换成一个张量(如下图 (b))。
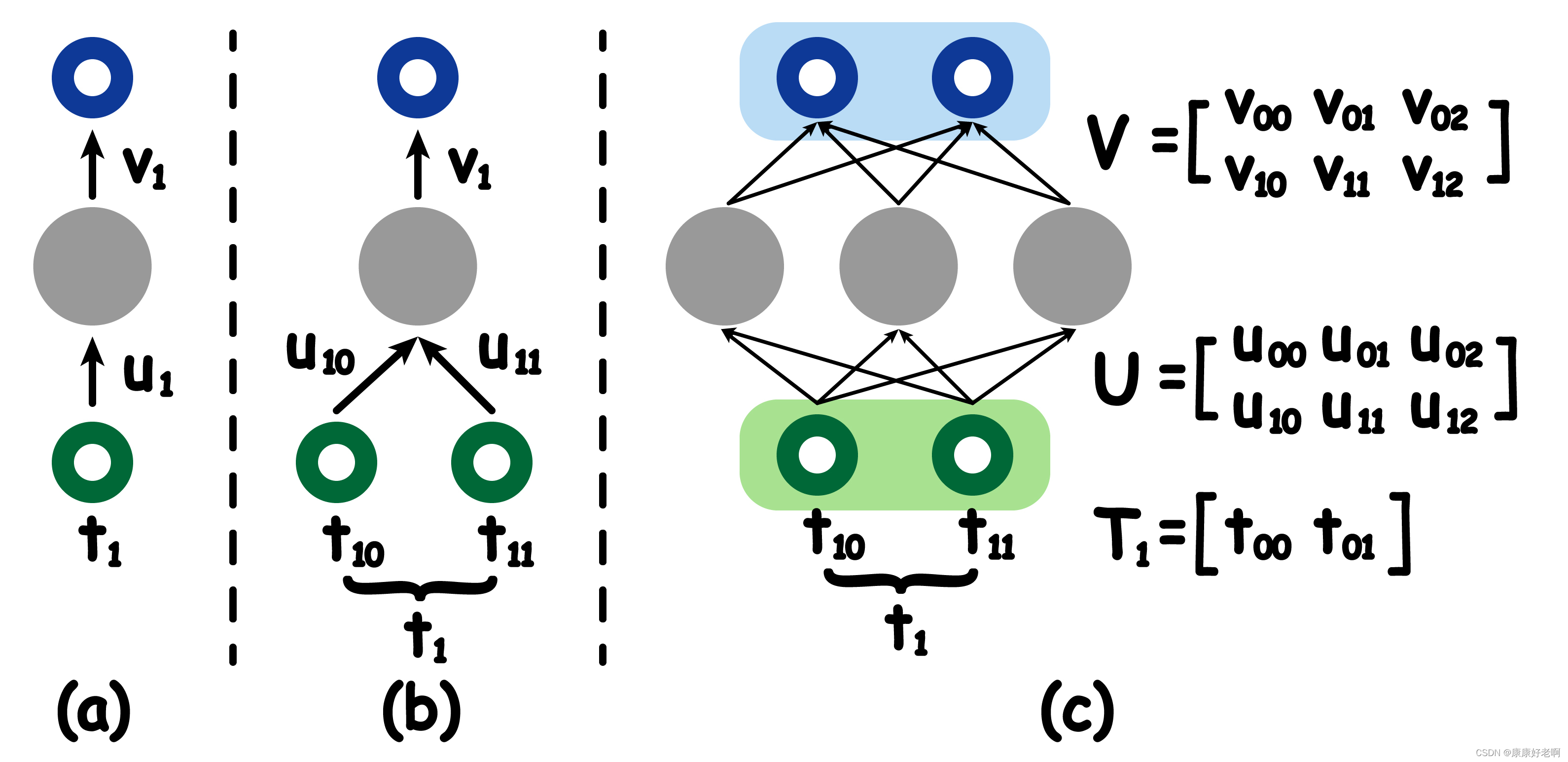
进一步拓展,中间的隐藏元素和输出维度都有可能会改变,这样就转化成了图 ©的形式。不难发现,这与 FNN (MLP)简直一模一样;然后就可以将这个替换原 RNN 中的图 (a)了,如下图:

学到这应该思考一下
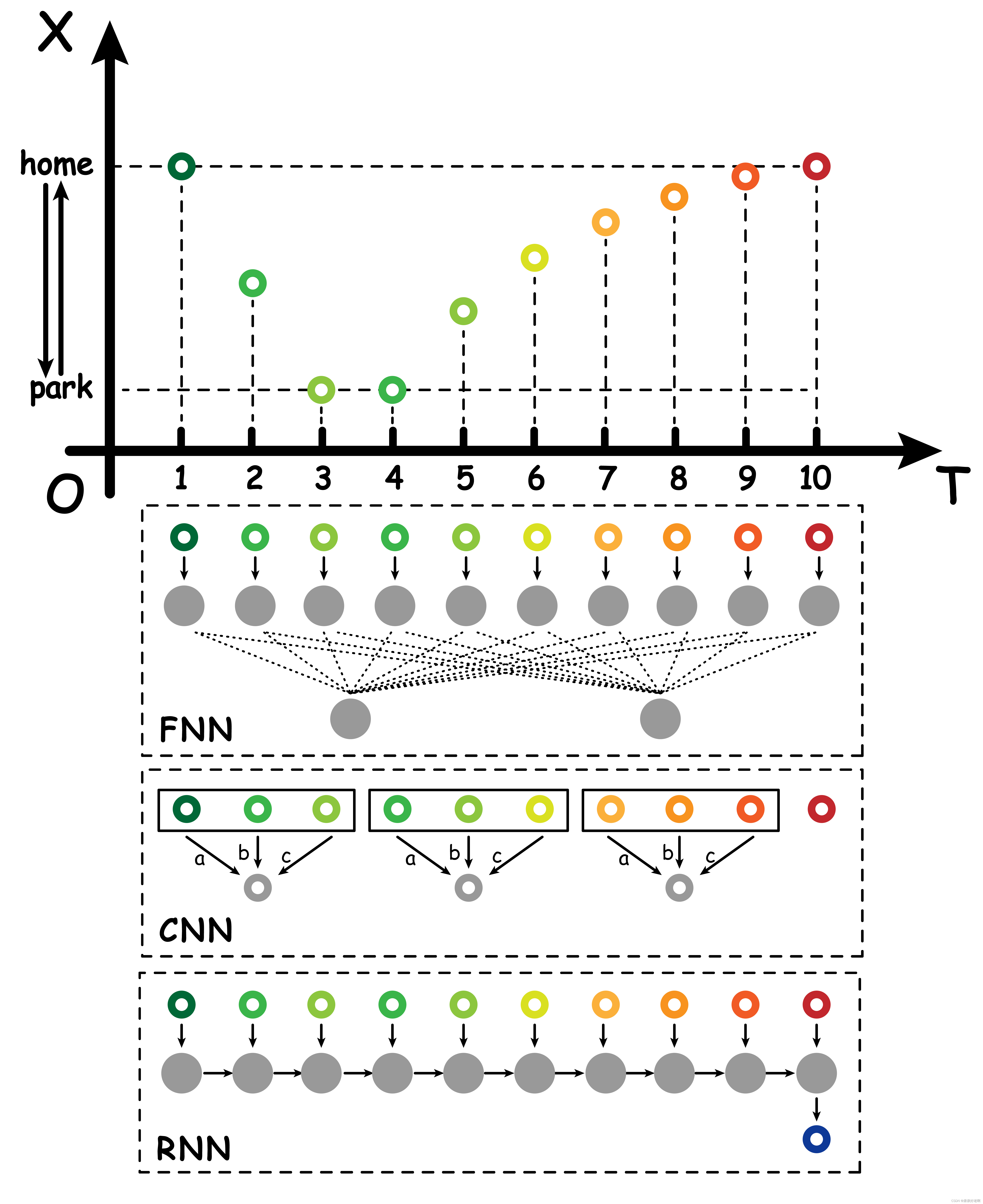
还记得上文这个图嘛,此时我们已经对 RNN 有了一定的基础的了解,可以进一步思考为什么 RNN 更加适合处理时间序列。上文提到,FNN 不容易学习输入数据之间的关联性,而 RNN 通过隐藏神经元 (层)的传递将各个时间序列的数据都传递在了一起;CNN 会导致所有数据经过处理的参数都共享,失去了不同数据的独立性(过于关联、等价),而 RNN 虽然也共享参数,但是每个输入数据按照时间远近有不同的深度,比如 t 1 t_{1} t1 时刻要经过 9 个 W W W ,而 t 5 t_{5} t5 时刻只需要经过 5 个,通过深度对不同的时间点进行差异化。所以可以说,RNN 在某种意义上是 FNN 和 CNN 的中和。
这里个人觉得有必要补充一下为什么这些参数能够共享:
仍然以跑步为例。在现实情况中,之前的跑步距离等信息是会一直影响到最后的。刚开始如果跑步速度过快,很容易就过早疲惫,10 分钟可能就慢慢走回家,然后因为特别累直接倒在床上睡着了,然后导致白天睡多了晚上睡不着,晚上睡不着于是刷手机,然后刷手机刷 emo 了。可以发现,刚开始跑步速度过快其实是对 emo 有间接影响的,而刷手机是直接影响。无论是间接影响还是直接影响,都是在同一事件链下,必然有相似之处,所以可以共享参数,符合实际逻辑的同时,又可以减小参数量
不同的输入输出与中间层
上文介绍的 RNN 输入是 10 个时间点的数据,输出是 1 组。但是事实上,输入输出的维度是可以改变的。比如这 10 个时间点的跑步数据发生了缺失情况,则可以如下改变:
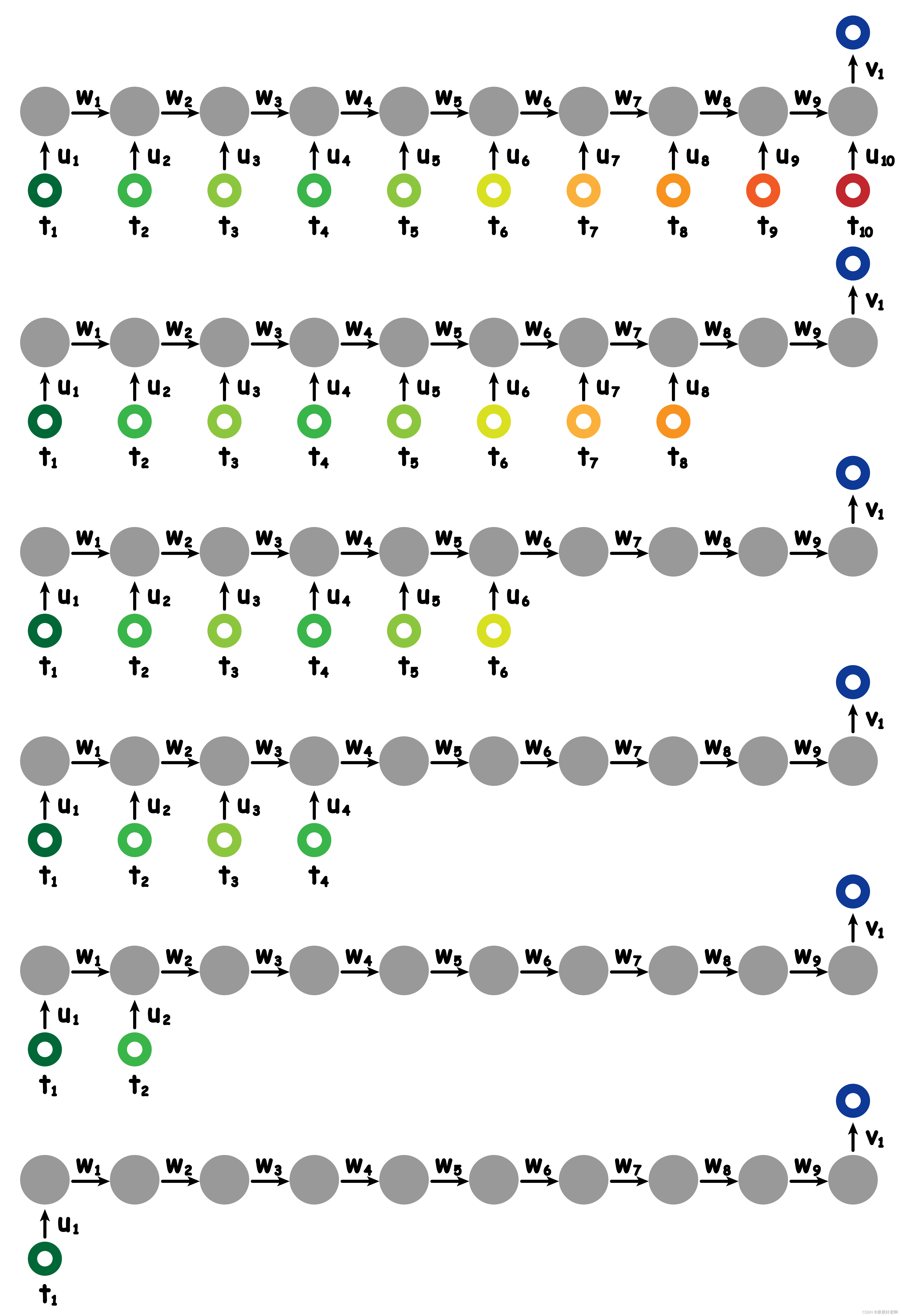
然后我们将中间多余的隐藏元删去,就可以得到不同输入的 RNN 了:
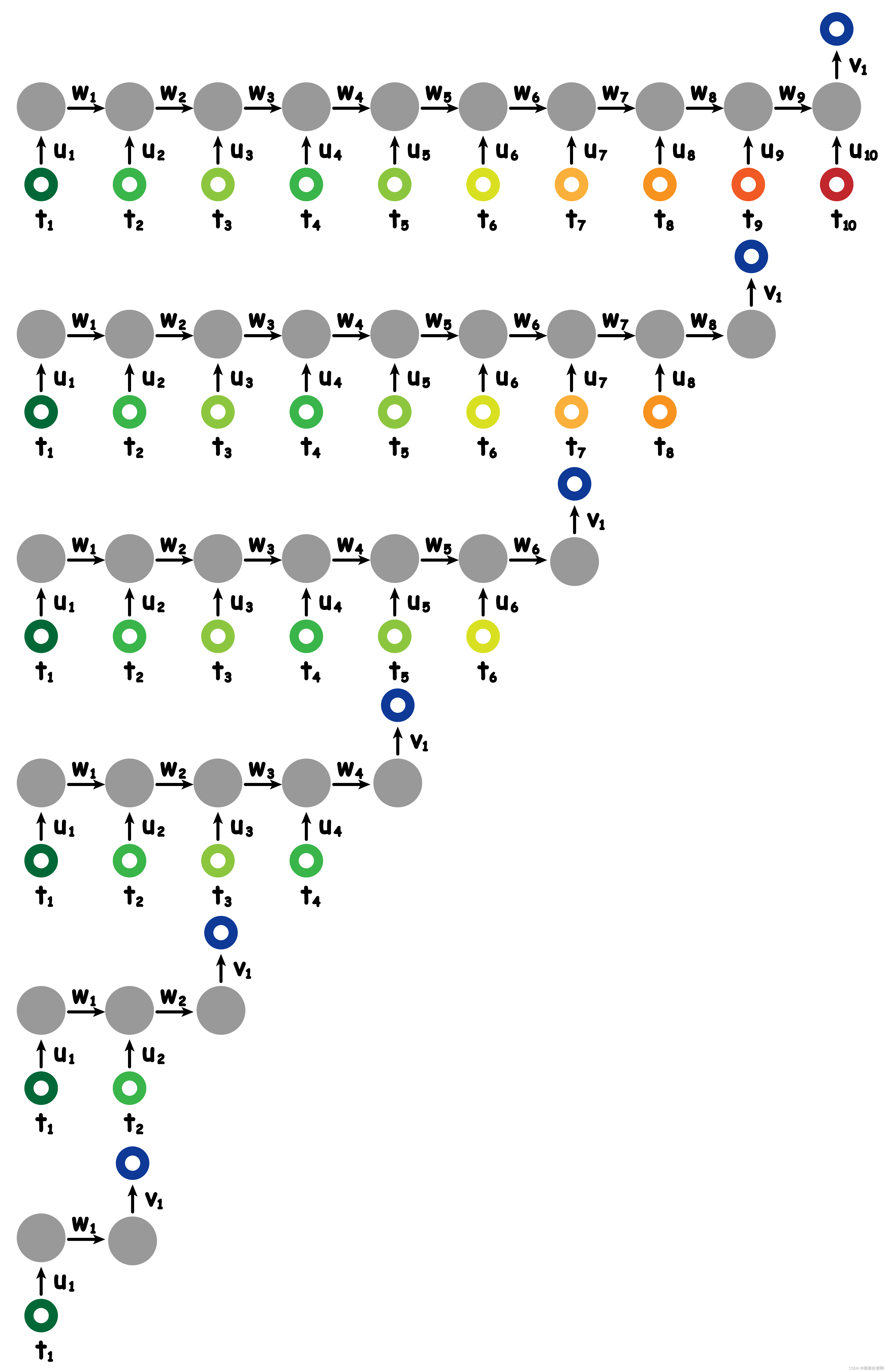
我们也可以进一步改变输出维度:
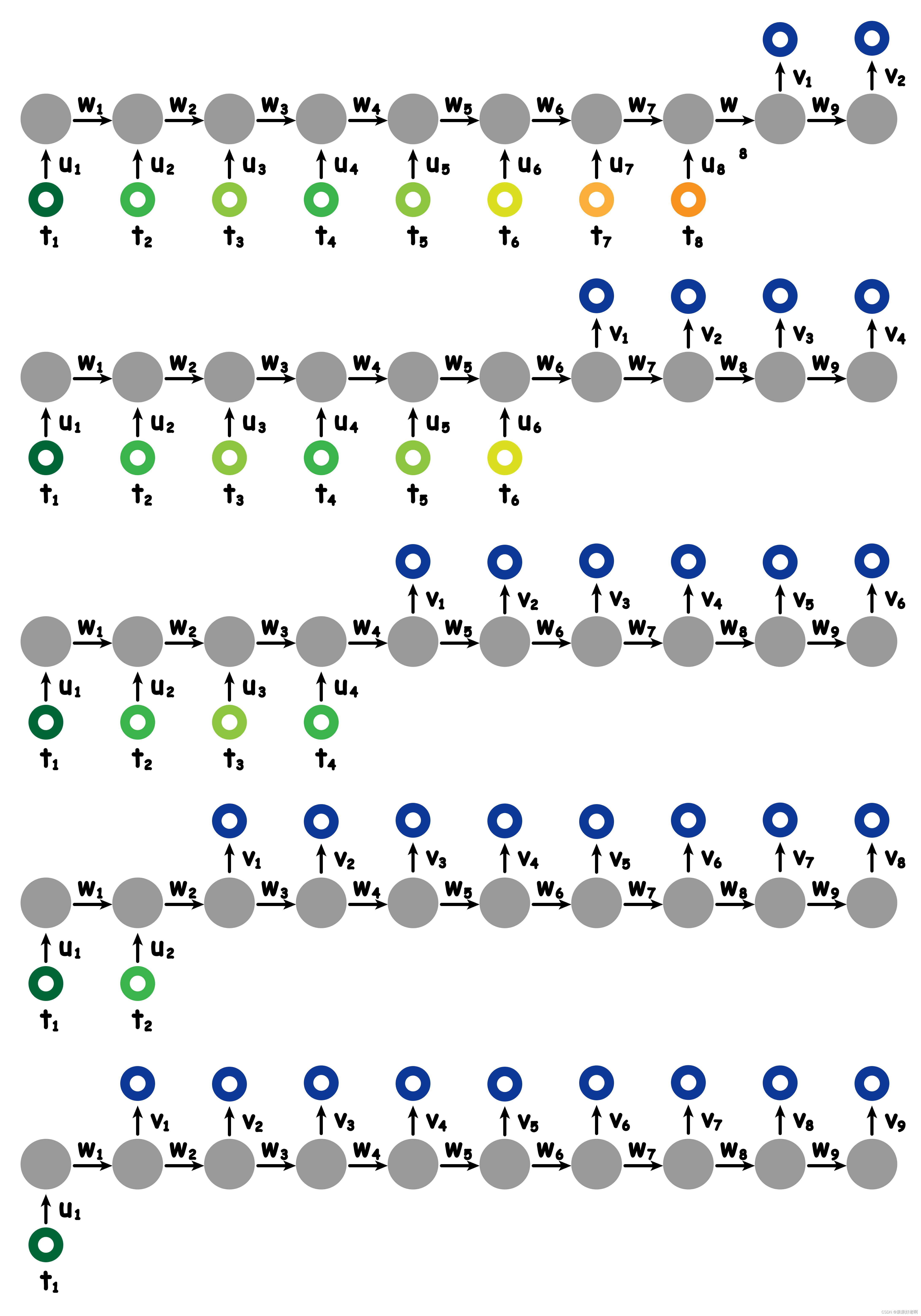
也可以如下改变:
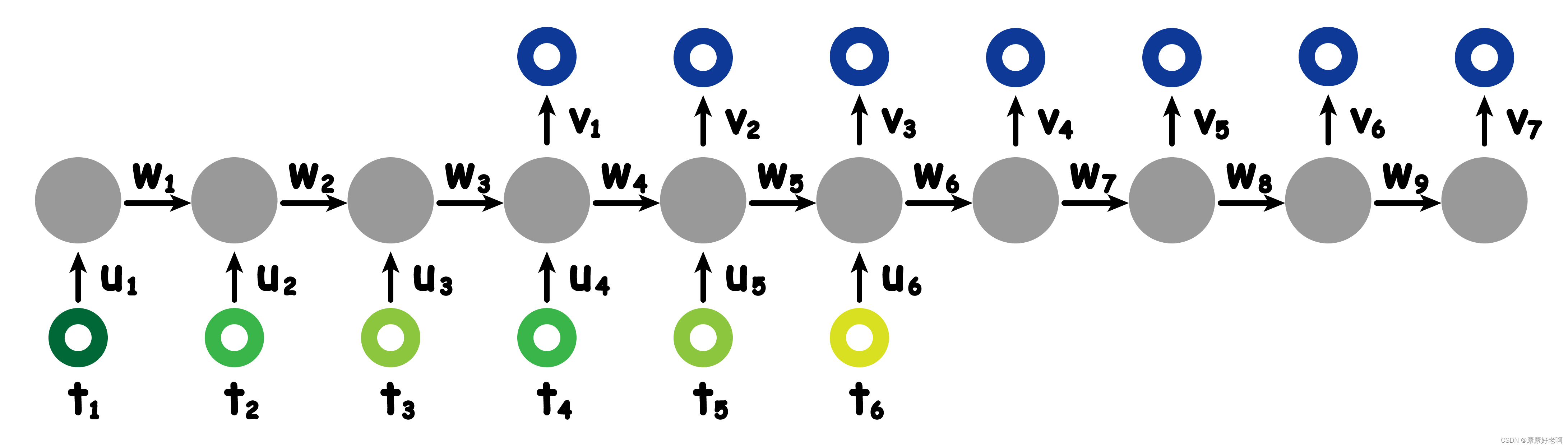
有各种各样的排列组合方式。
类比于 FNN (MLP)和 CNN,RNN 也可以拥有更多的隐藏层。

反向传播 BPTT
这里有必要介绍一下 RNN 的反向传播 Backpropagation Through Time (BPTT),其与传统的 FNN 反向传播略有不同,并且了解 BPTT 的简单原理和结果对了解 RNN 的弱点以及 LSTM 提出的初衷有比较大的帮助。
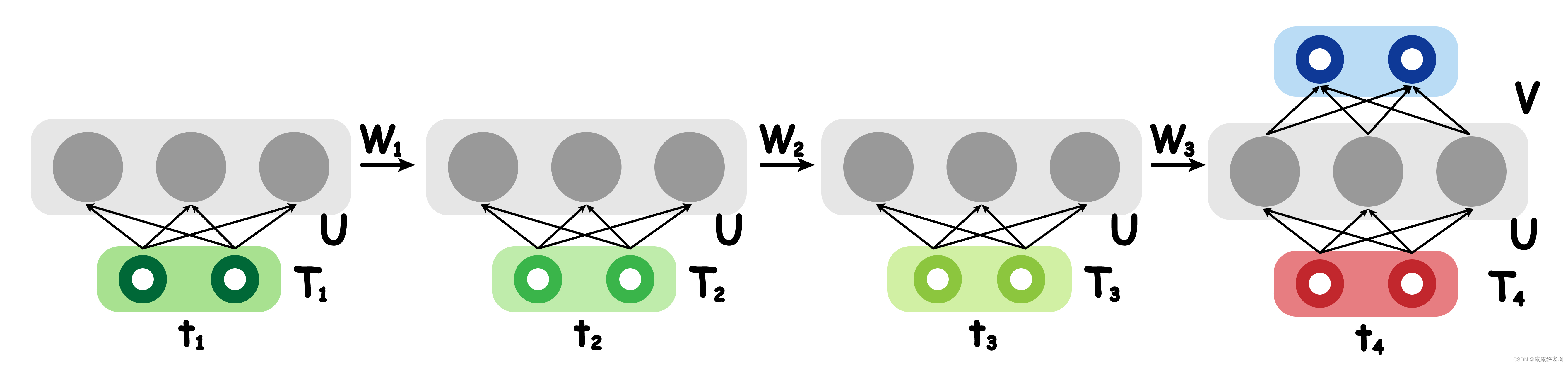
这里不过多阐述其是如何推导的,因为过于理论,篇幅较长,先说结论,求完偏导后的公式结果如下 (以 4 层 RNN 为例):
∂ L ∂ V = ∂ L ∂ y ∂ y ∂ V ∂ L ∂ U = ∂ L ∂ y ∂ y ∂ T 4 ∂ T 4 ∂ U + ∂ L ∂ y ∂ y ∂ T 4 ∂ T 4 ∂ T 3 ∂ T 3 ∂ U + ∂ L ∂ y ∂ y ∂ T 4 ∂ T 4 ∂ T 3 ∂ T 3 ∂ T 2 ∂ T 2 ∂ U + ∂ L ∂ y ∂ y ∂ T 4 ∂ T 4 ∂ T 3 ∂ T 3 ∂ T 2 ∂ T 2 ∂ T 1 ∂ T 1 ∂ U ∂ L ∂ W = ∂ L ∂ y ∂ y ∂ T 4 ∂ T 4 ∂ W + ∂ L ∂ y ∂ y ∂ T 4 ∂ T 4 ∂ T 3 ∂ T 3 ∂ W + ∂ L ∂ y ∂ y ∂ T 4 ∂ T 4 ∂ T 3 ∂ T 3 ∂ T 2 ∂ T 2 ∂ W + ∂ L ∂ y ∂ y ∂ T 4 ∂ T 4 ∂ T 3 ∂ T 3 ∂ T 2 ∂ T 2 ∂ T 1 ∂ T 1 ∂ W \begin{aligned} \frac{\partial L}{\partial V}&=\frac{\partial L}{\partial y}\frac{\partial y}{\partial V} \\ \frac{\partial L}{\partial U}&=\frac{\partial L}{\partial y}\frac{\partial y}{\partial T_{4}}\frac{\partial T_{4}}{\partial U}+\frac{\partial L}{\partial y}\frac{\partial y}{\partial T_{4}}\frac{\partial T_{4}}{\partial T_{3}}\frac{\partial T_{3}}{\partial U}+\frac{\partial L}{\partial y}\frac{\partial y}{\partial T_{4}}\frac{\partial T_{4}}{\partial T_{3}}\frac{\partial T_{3}}{\partial T_{2}}\frac{\partial T_{2}}{\partial U}+\frac{\partial L}{\partial y}\frac{\partial y}{\partial T_{4}}\frac{\partial T_{4}}{\partial T_{3}}\frac{\partial T_{3}}{\partial T_{2}}\frac{\partial T_{2}}{\partial T_{1}}\frac{\partial T_{1}}{\partial U} \\ \frac{\partial L}{\partial W}&=\frac{\partial L}{\partial y}\frac{\partial y}{\partial T_{4}}\frac{\partial T_{4}}{\partial W}+\frac{\partial L}{\partial y}\frac{\partial y}{\partial T_{4}}\frac{\partial T_{4}}{\partial T_{3}}\frac{\partial T_{3}}{\partial W}+\frac{\partial L}{\partial y}\frac{\partial y}{\partial T_{4}}\frac{\partial T_{4}}{\partial T_{3}}\frac{\partial T_{3}}{\partial T_{2}}\frac{\partial T_{2}}{\partial W}+\frac{\partial L}{\partial y}\frac{\partial y}{\partial T_{4}}\frac{\partial T_{4}}{\partial T_{3}}\frac{\partial T_{3}}{\partial T_{2}}\frac{\partial T_{2}}{\partial T_{1}}\frac{\partial T_{1}}{\partial W} \end{aligned} ∂V∂L∂U∂L∂W∂L=∂y∂L∂V∂y=∂y∂L∂T4∂y∂U∂T4+∂y∂L∂T4∂y∂T3∂T4∂U∂T3+∂y∂L∂T4∂y∂T3∂T4∂T2∂T3∂U∂T2+∂y∂L∂T4∂y∂T3∂T4∂T2∂T3∂T1∂T2∂U∂T1=∂y∂L∂T4∂y∂W∂T4+∂y∂L∂T4∂y∂T3∂T4∂W∂T3+∂y∂L∂T4∂y∂T3∂T4∂T2∂T3∂W∂T2+∂y∂L∂T4∂y∂T3∂T4∂T2∂T3∂T1∂T2∂W∂T1
其实不难从中找到规律, U , W U,W U,W 其实就是多次使用链式法则累乘再相加。这样可能会带来一些问题,也是所有链式法则可能带来的问题,就是梯度消失以及梯度爆炸。
- 梯度消失: 就是梯度过小导致梯度接近于 0 使得参数不再更新。在 RNN 中,数据经过每个神经元后会通过 tanh 激活函数,使得绝大部分数据的值小于 1。而随着 RNN 网络加深,许多小于 1 的值累乘会得到一个十分接近于 0 的数,这就是梯度消失的原因。
- 梯度爆炸: 就是梯度过大导致梯度过高变成 NaN。这个同理梯度消失,当许多大于 1 的梯度相乘时,会导致梯度过大而没法正常进行反向传播。

从直观表现上,梯度消失和梯度爆炸都是由于输入的时序过于长,根据链式法则会使得梯度急剧增大或者减小。而这也是 RNN 比较大的缺点之一,由此提出了 LSTM 、GRU 进行改进。关于这两者的介绍,将放到后续博客中进行讲解

![带你<span style='color:red;'>学会</span><span style='color:red;'>深度</span><span style='color:red;'>学习</span><span style='color:red;'>之</span><span style='color:red;'>循环</span><span style='color:red;'>神经</span><span style='color:red;'>网络</span>[<span style='color:red;'>RNN</span>] - 3](https://img-blog.csdnimg.cn/direct/5abde1e01e2a41e48bf0fc965b266e5a.png)






















![[NeurIPS-23] GOHA: Generalizable One-shot 3D Neural Head Avatar](https://img-blog.csdnimg.cn/direct/e9d5e5fcdf804c0c8392f27a8324759d.png)
![[C++基础学习]----02-C++运算符详解](https://img-blog.csdnimg.cn/direct/ea11c69207614ba8b8c24f8816c741a0.png)