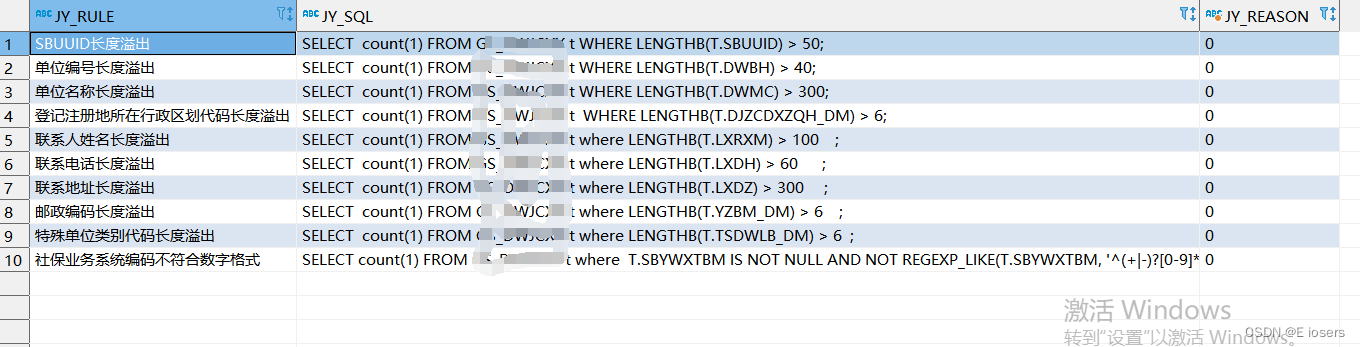
前言
笔者写下此系列文章是希望在复习人工智能相关知识同时为想学此技术的人提供一定帮助。
图源网络,所有者可随时联系笔者删除。
代码不代表全部实现,只是为展示模型的关键结构。
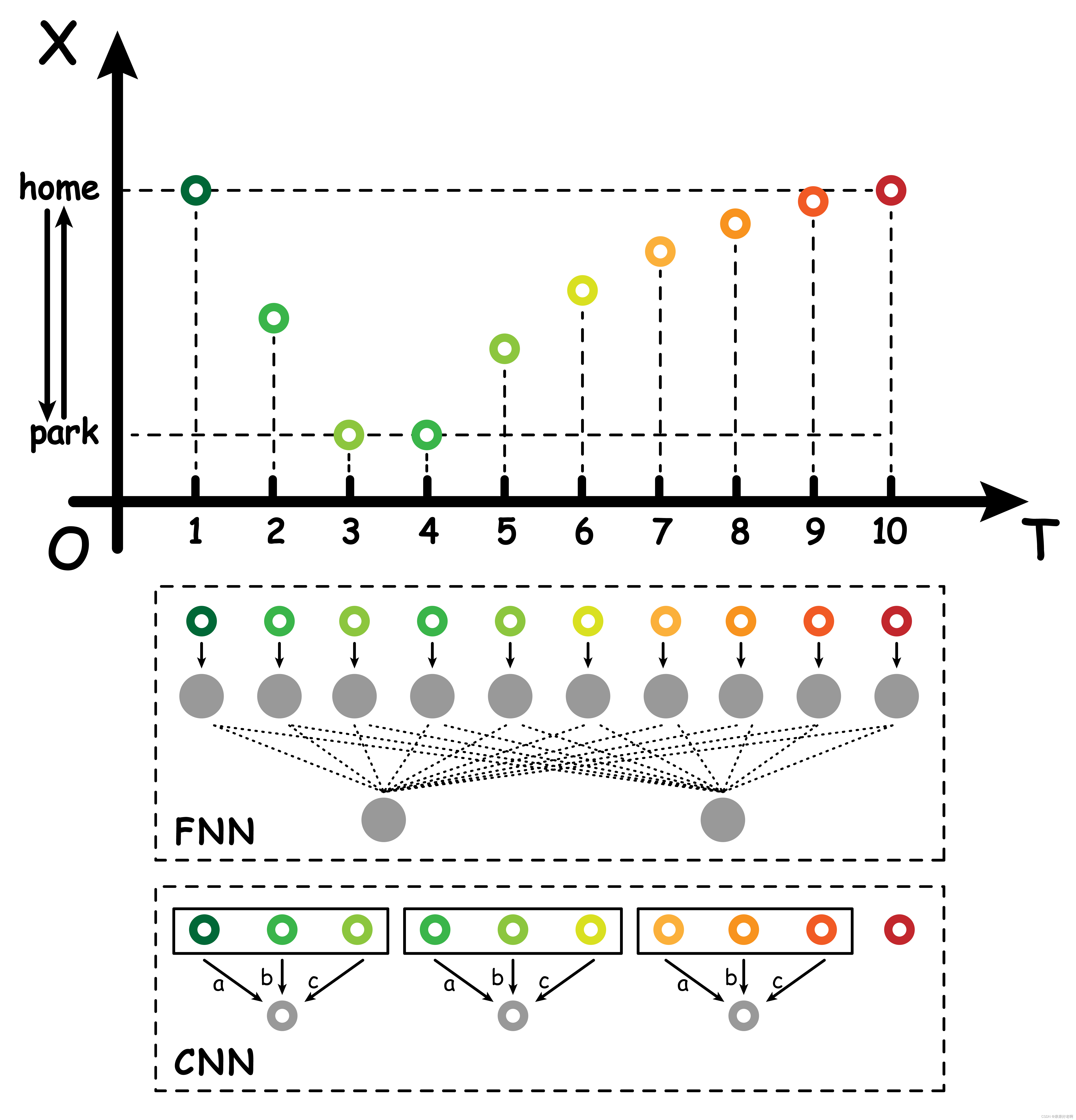
与CNN不同,RNN被设计用来处理序列数据。它通过在网络的隐藏层中引入循环,使网络能够保留前一个状态的信息,并将这些信息用于当前状态的计算。这种设计使RNN特别适合处理语言翻译、自然语言处理、语音识别等需要理解数据序列中时间相关性的任务。
正文
RNN变种之 LSTM 长短期记忆
LSTM,全称为长短期记忆(Long Short-Term Memory)网络
前文讲到RNN在实践中会有梯度消失和梯度爆炸问题,这使得网络难以学习并保持长期的依赖信息,也讲了一个基本的解决模型GRU,LSTM是同样著名的另外一个变种模型。
LSTM网络由Hochreiter和Schmidhuber于1997年首次提出,GRU由Cho等人于2014年提出,被认为是LSTM的一个变体,简化了LSTM的结构,但保持了类似的性能。
GRU将LSTM中的遗忘门和输入门合并成一个单一的更新门,并将单元状态和隐藏状态合并为一个状态,简化了模型结构。减少了参数的数量,减轻了计算负担。
但这不代表GRU一定更好

遗忘门(Forget Gate)
遗忘门决定从单元状态中丢弃什么信息。它观察上一个时间步的隐藏状态和当前时间步的输入,输出一个在0到1之间的数值给给每个在单元状态中的数值,1表示完全保留,而0表示完全遗忘。

- ft是遗忘门的输出
- σ是sigmoid激活函数
- Wf是遗忘门的权重
- bf是偏置项
- ht−1是上一个时间步的隐藏状态
- xt是当前时间步的输入
输入门(Input Gate)
输入门决定新输入的信息中哪些值将更新到单元状态中,它包含两个部分:
一个sigmoid层决定哪些值将要更新,一个tanh层创建一个新的候选值向量,可以被加到状态中。


- it是输入门的sigmoid层输出
- C~t是tanh层输出的候选值向量
单元状态(Cell State)
单元状态是LSTM的核心,在网络中贯穿始终,携带着关于已处理数据的所有重要信息。信息在单元状态中可以被修改:通过遗忘门删除一些旧的信息,并通过输入门添加一些新的信息。

- ∗表示逐元素乘法
输出门(Output Gate)
输出门控制着从单元状态到下一个时间步的输入的信息流动,首先,单元状态通过tanh函数(将值压缩到-1到1之间)处理,然后乘以输出门的输出,决定最终的输出是什么。


- ot是输出门的输出
LSTM的参数量据说大致是GRU的四倍
同样给出Pytorch和Tensorflow框架的调用代码
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_layer_size, output_size):
super(LSTMModel, self).__init__()
self.hidden_layer_size = hidden_layer_size
self.lstm = nn.LSTM(input_size, hidden_layer_size)
self.linear = nn.Linear(hidden_layer_size, output_size)
self.hidden_cell = (torch.zeros(1,1,self.hidden_layer_size),
torch.zeros(1,1,self.hidden_layer_size))
def forward(self, input_seq):
lstm_out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq) ,1, -1), self.hidden_cell)
predictions = self.linear(lstm_out.view(len(input_seq), -1))
return predictions[-1]
input_size是输入序列的特征维度,hidden_layer_size指的是LSTM单元中隐藏层的大小,output_size是模型输出的大小,self.hidden_cell是一个包含初始隐藏状态和单元状态的元组。
model = Sequential([
LSTM(hidden_layer_size, input_shape=(None, input_size),return_sequences=False),
Dense(output_size)
])
双向循环神经网络
双向循环神经网络(Bi-directional Recurrent Neural Network, Bi-RNN)通过在序列数据上同时进行正向和反向传递来增强模型对序列信息的捕获能力。这种网络特别适合于需要考虑上下文信息的任务,如自然语言处理(NLP)中的文本分类、语音识别等。
在标准的RNN中,信息的传递是单向的,即从序列的开始到结束。这种方式虽然能够捕捉到时间序列的动态特性,但在某些情况下,仅依赖过去的信息是不够的。例如,在文本处理任务中,句子的意义往往需要根据上下文来确定,这就要求模型不仅要考虑之前的词语,也要考虑之后的词语。
Bi-RNN通过引入一个额外的反向层来解决这个问题,该层从序列的末尾开始处理数据,向前传递信息。最终,每个时刻的输出会结合正向层和反向层在该时刻的隐藏状态,通过某种方式(如拼接或求和)来综合这两个方向的信息。

Bi-LSTM
Bi-LSTM结构在每个时间步使用两个独立的LSTM单元,一个处理正向序列,另一个处理反向序列。正向LSTM单元按照时间顺序处理输入序列,捕获过去的信息,而反向LSTM单元则从序列的末尾开始反向处理,捕获未来的信息。最后,这两个方向上的信息在每个时间步被合并(例如,通过拼接或加权平均),以产生最终输出。
class BiLSTMModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, num_layers):
super(BiLSTMModel, self).__init__()
self.hidden_dim = hidden_dim
self.num_layers = num_layers
self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers=num_layers,
bidirectional=True, batch_first=True)
self.fc = nn.Linear(hidden_dim * 2, output_dim) # 乘以2因为是双向
def forward(self, x):
h0 = torch.zeros(self.num_layers * 2, x.size(0), self.hidden_dim).to(x.device) # 双向*层数
c0 = torch.zeros(self.num_layers * 2, x.size(0), self.hidden_dim).to(x.device)
out, _ = self.lstm(x, (h0, c0))
out = self.fc(out[:, -1, :])
return outmodel = tf.keras.Sequential([
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(20, return_sequences=True),
input_shape=(None, 10)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(20)),
tf.keras.layers.Dense(1)
])Bi-GRU
同Bi-LSTM类似,Bi-GRU通过在每个时间点结合正向和反向GRU单元的信息。
class BiGRUModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, num_layers):
super(BiGRUModel, self).__init__()
self.hidden_dim = hidden_dim
self.num_layers = num_layers
self.gru = nn.GRU(input_dim, hidden_dim, num_layers=num_layers,
bidirectional=True, batch_first=True)
self.fc = nn.Linear(hidden_dim * 2, output_dim) # 乘以2因为是双向
def forward(self, x):
h0 = torch.zeros(self.num_layers * 2, x.size(0), self.hidden_dim).to(x.device) # 双向*层数
out, _ = self.gru(x, h0)
out = self.fc(out[:, -1, :])
return outmodel = tf.keras.Sequential([
tf.keras.layers.Bidirectional(tf.keras.layers.GRU(20, return_sequences=True),
input_shape=(None, 10)),
tf.keras.layers.Bidirectional(tf.keras.layers.GRU(20)),
tf.keras.layers.Dense(1)
])
本文到此结束,有兴趣的读者可以下去研究下TF代码少了额外定义的forward方法是为什么
笔者现在考虑要不要结束此系列的文章,开始写写实战的内容,虽然还有很多还没谈到就是了,,,(指此系列文章还有很多深度学习相关知识还没谈,如优化函数选择,嵌入等等)