目录
一.树的逻辑结构
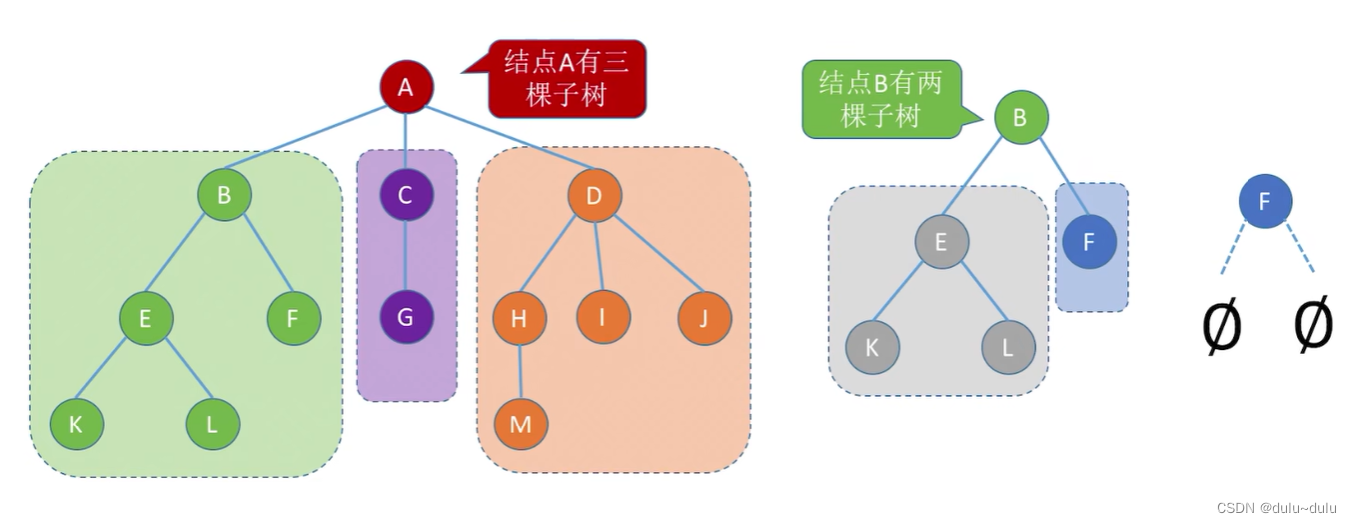
树是n (n0) 个结点的有限集合,n=0时,称为空树,这是一种特殊情况。
在任意一棵非空树中应满足:
1)有且仅有一个特定的称为根的结点。
2)当n>1时,其余结点可分为m (m>0) 个互不相交的有限集合T1,T2.…. Tm,其中每个集合本身又是一棵树,并且称为根结点的子树。
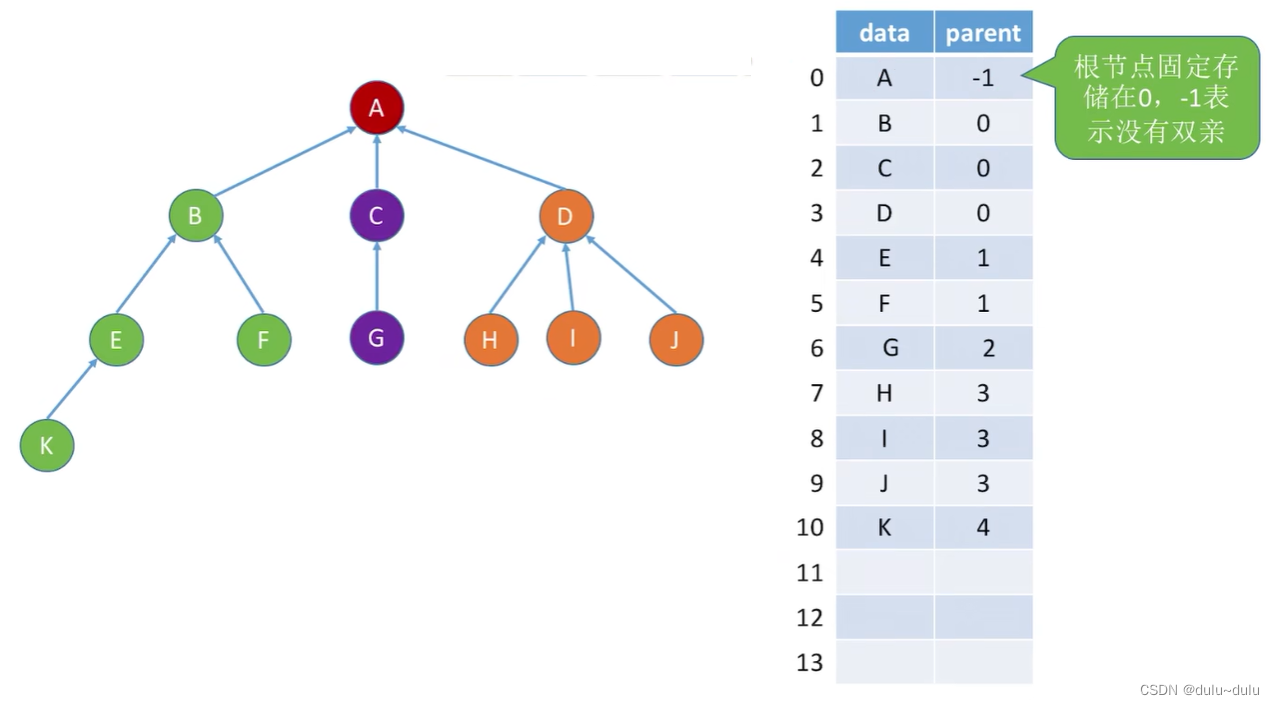
1.双亲表示法(顺序存储)
除了根节点之外,其它节点具有唯一的父节点,所以每个节点除了保存数据外,还会保存指向双亲的“指针”。
如下图所示,-1表示没有双亲,B,C,D的双亲为0号节点。
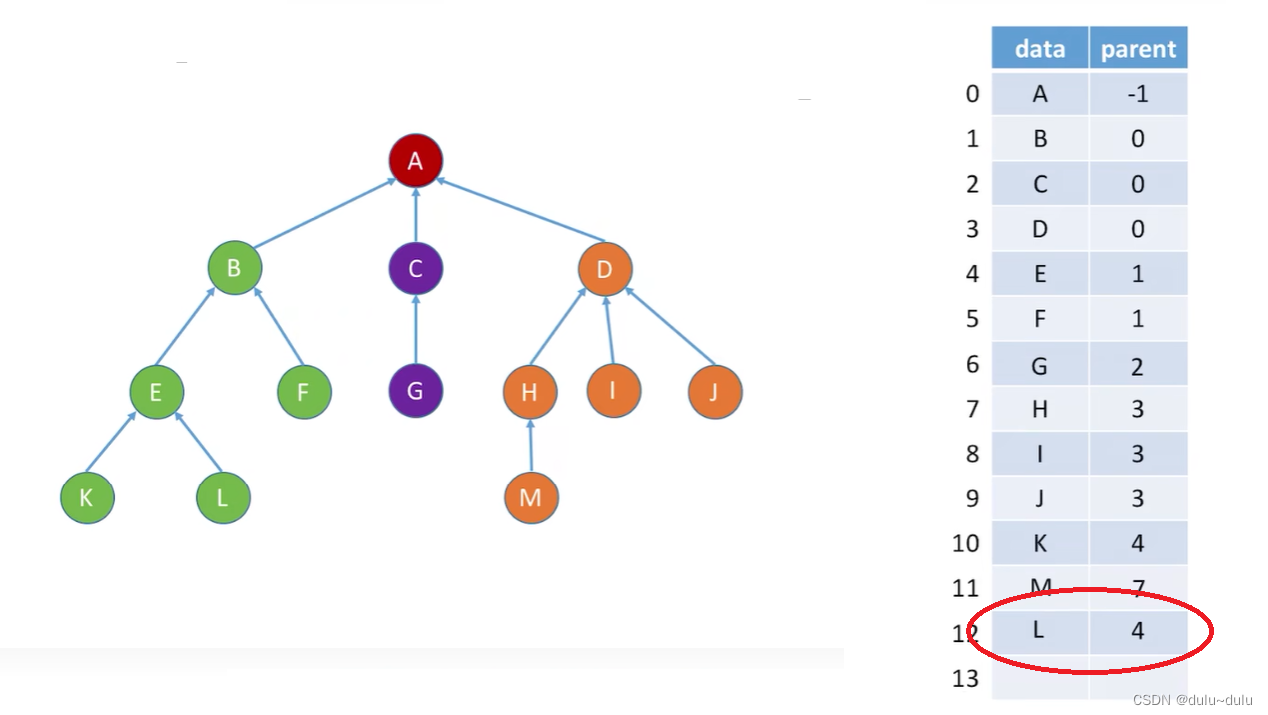
注:新增数据元素,无需按逻辑上的次序存储
#define MAX_TREE_SIZE 100 //树中最多结点数
typedef struct{ //树的结点定义
ElemType data; //数据元素
int parent; //双亲位置域
}pTNode;
typedef struct{ //树的类型定义
PTNodenodes[MAX_TREE_SIZE]; //双亲表示
int n; //结点数
}PTree;
•插入新节点:写入新节点的值,并记录其与双亲的关系。
注:新增数据元素,无需按逻辑上的次序存储
•删除节点:
方案一:删除元素后,将其双亲"指针"设为"-1"。
方案二:将尾部的数据移动到删除元素的位置。
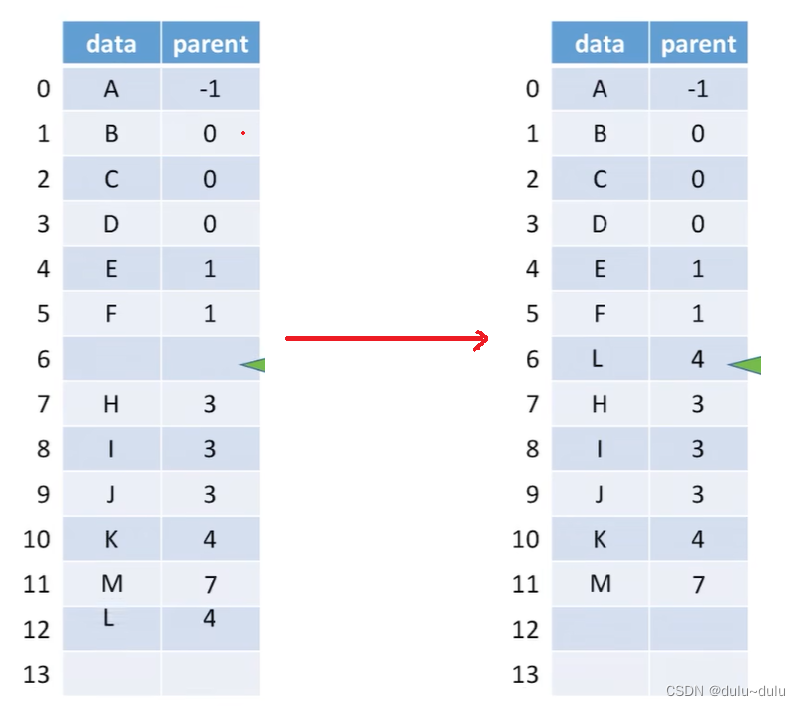
哪个方案更好呢?
若要删除的节点不是叶子节点,那么需要将其子孙节点全部删除,这就需要依次遍历,查找他的孩子节点。若采用第一种方案,则遍历时会出现空数据,会导致遍历速度下降。
在二叉树的顺序存储中,二叉树的节点编号与完全二叉树对应:
i的左孩子---2i
i的右孩子---2i+1
i的父节点---
可以看到,节点的编号不仅反映了存储位置,也隐含了节点之间的逻辑关系。
忘记了可以看看:二叉树
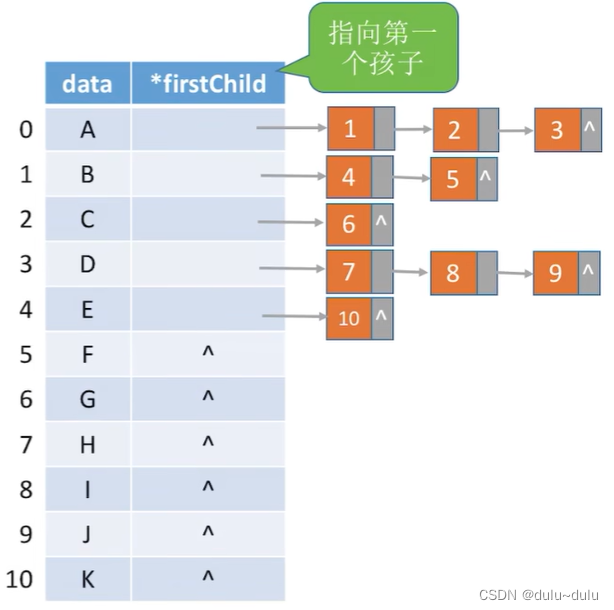
2.孩子表示法(顺序+链式存储)
顺序存储各个节点,每个结点除了保存数据域外,还保存了指向第一个孩子的指针。
struct CTNode {
int child; // 孩子结点在数组中的位置
struct CTNode *next; // 下一个孩子
};
typedef struct {
ElemType data;
struct CTNode *firstChild; // 第一个孩子
} CTBox;
typedef struct {
CTBox nodes[MAX_TREE_SIZE];
int n,r; // 结点数和根的位置
} CTree;
3.孩子兄弟表示法(链式存储)
typedef struct csNode{
ElemType data; //数据域
struct CSNode *firstchild,*nextsibling;
//firstchild指向第一个孩子,nextsibling指向第一个孩子的右兄弟
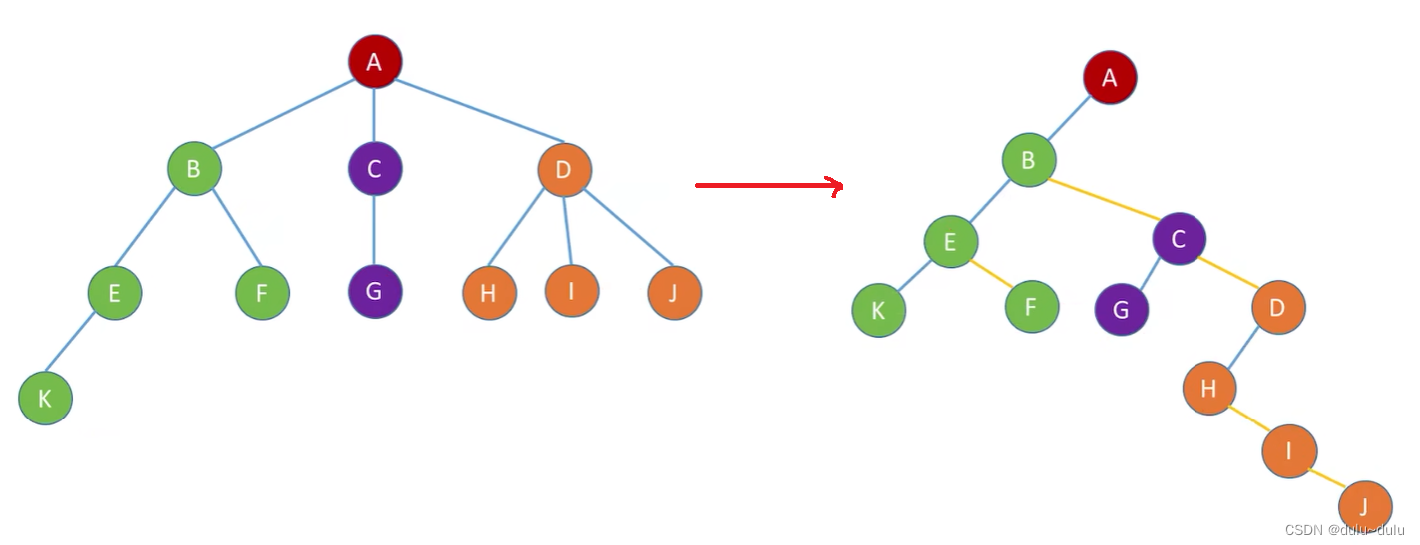
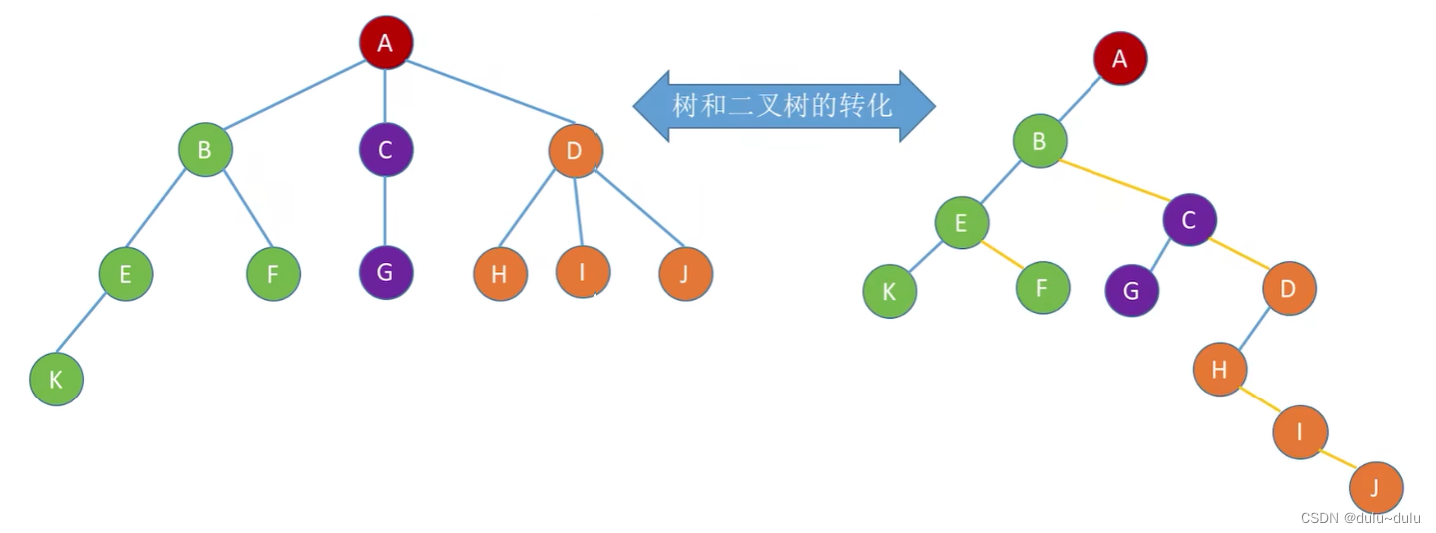
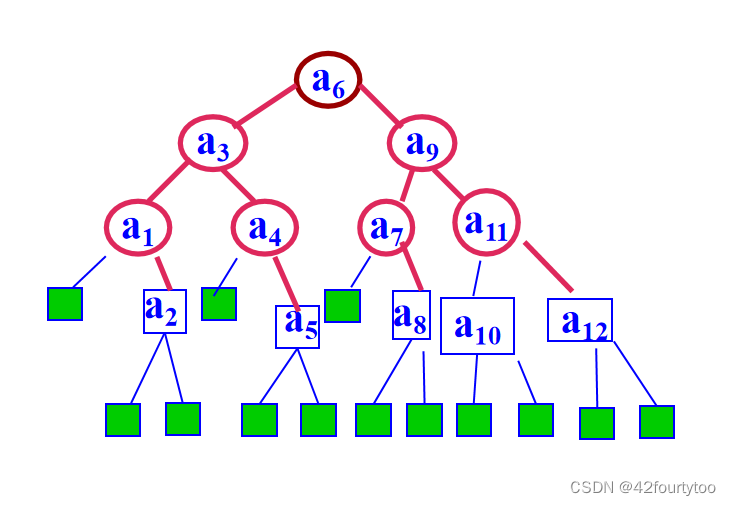
}CSNode,*CSTree; 如下图所示:
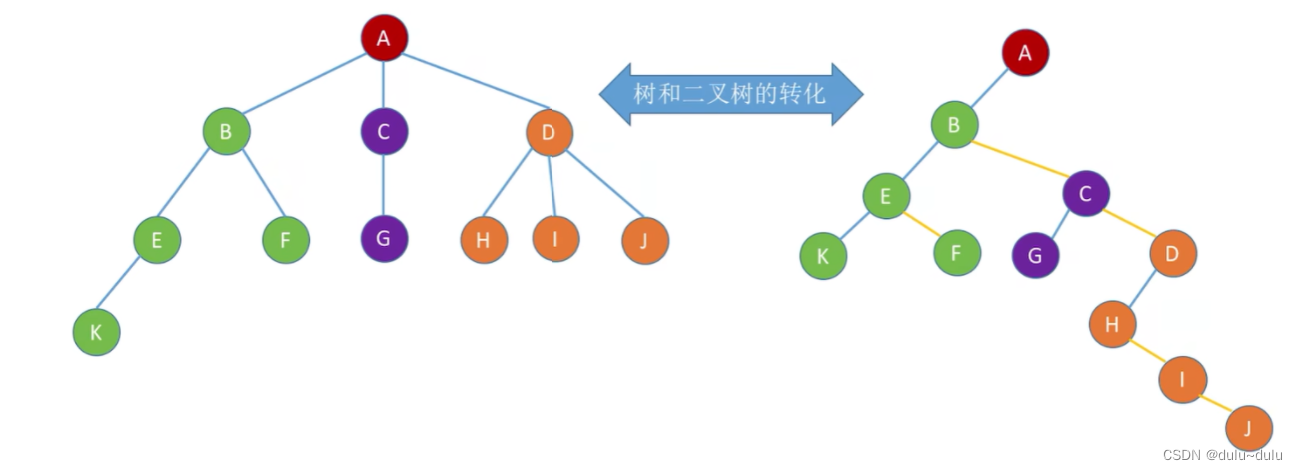
A的第一个孩子是B,A的左指针指向B,B的右兄弟为C,所以B的右指针指向C,C的右兄弟是D,所以C的右指针指向D,其他依此类推。
这就实现了树到二叉树的转化。
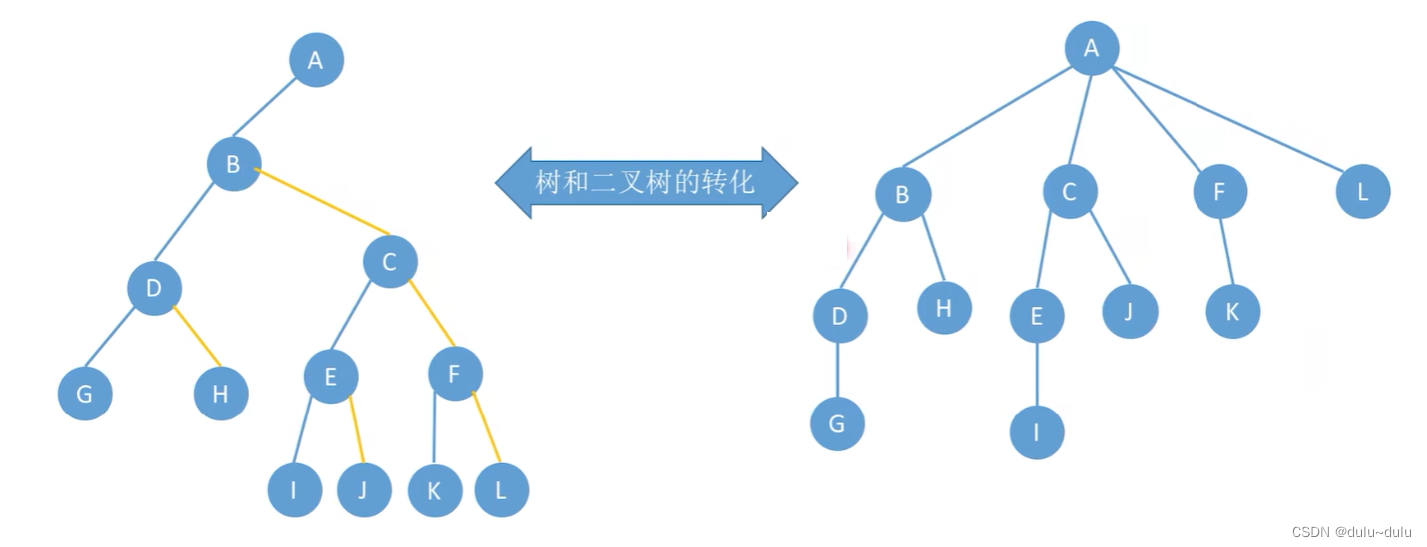
二叉树到树转换的逻辑与上面反过来就行:
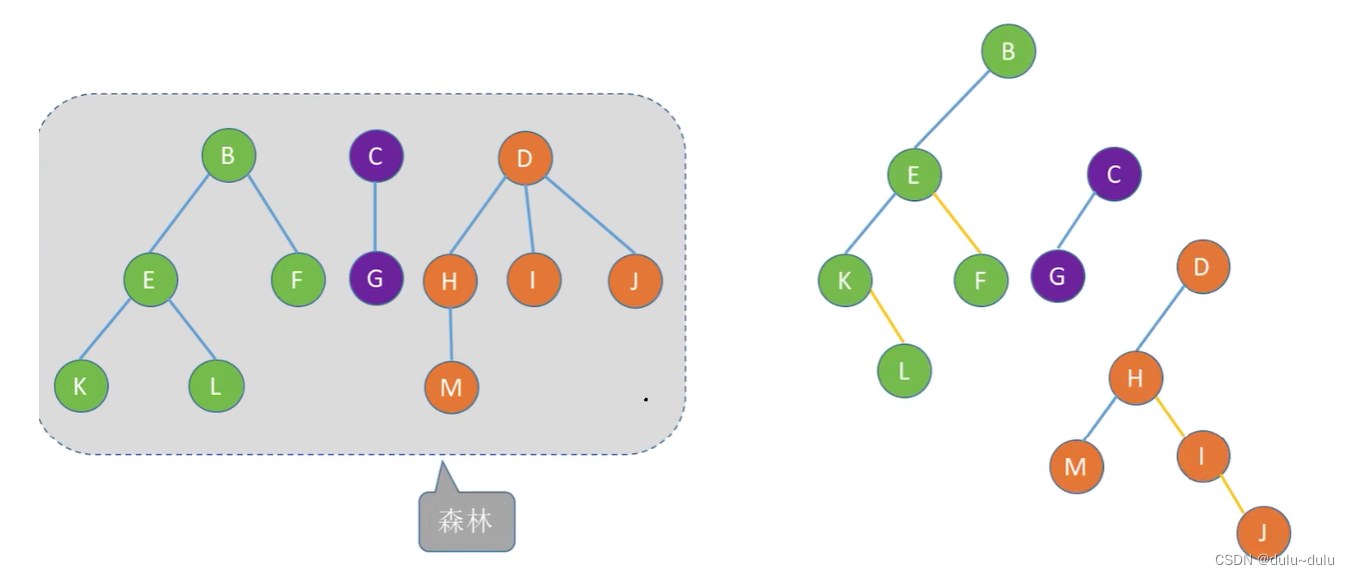
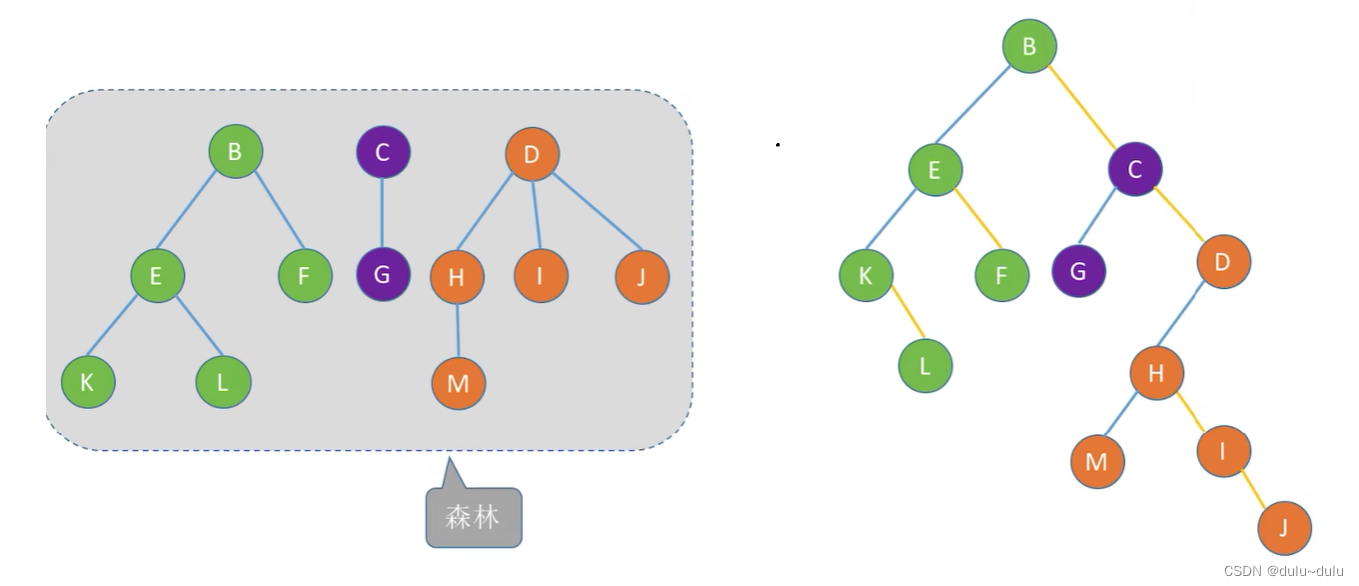
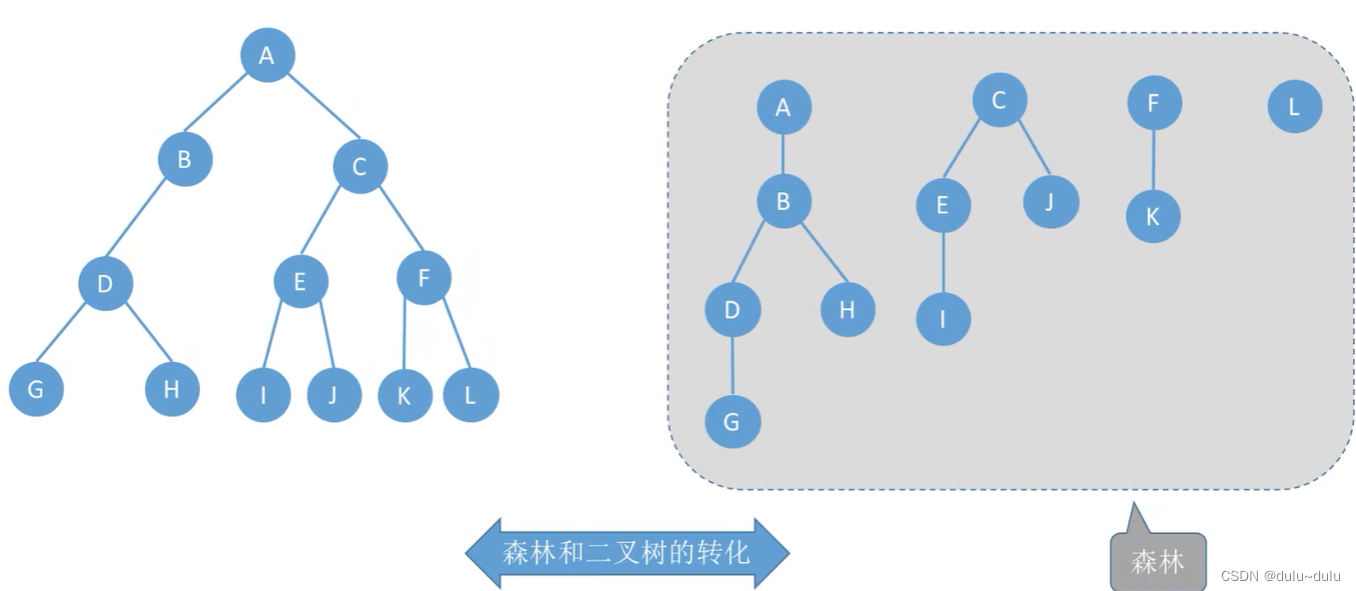
补充:森林和二叉树的相互转换
1.首先将森林里的每一棵树转换为二叉树:
2.将根节点看作兄弟结点,通过右指针指向:
二叉树转换为森林的逻辑反过来即可:
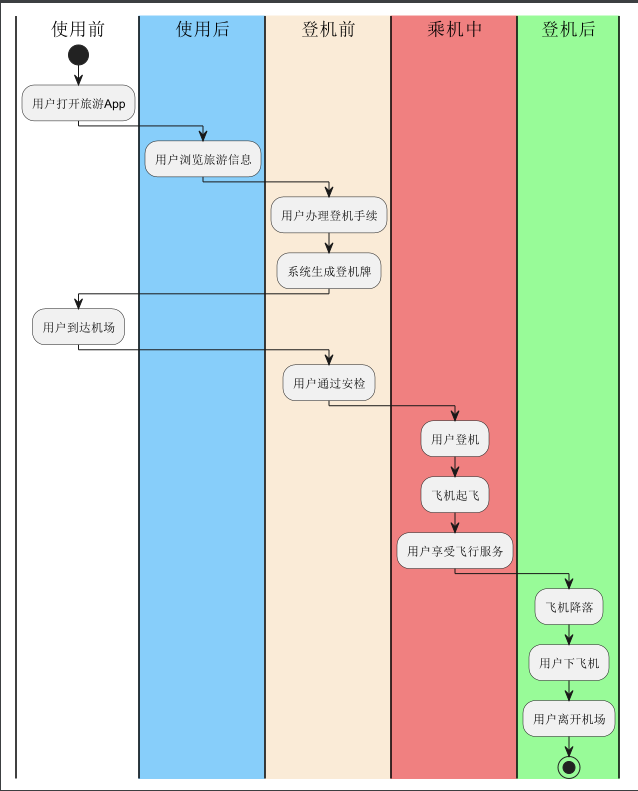
二.树的遍历
1.先根遍历
树的先根遍历与二叉树的先根遍历原理相同。
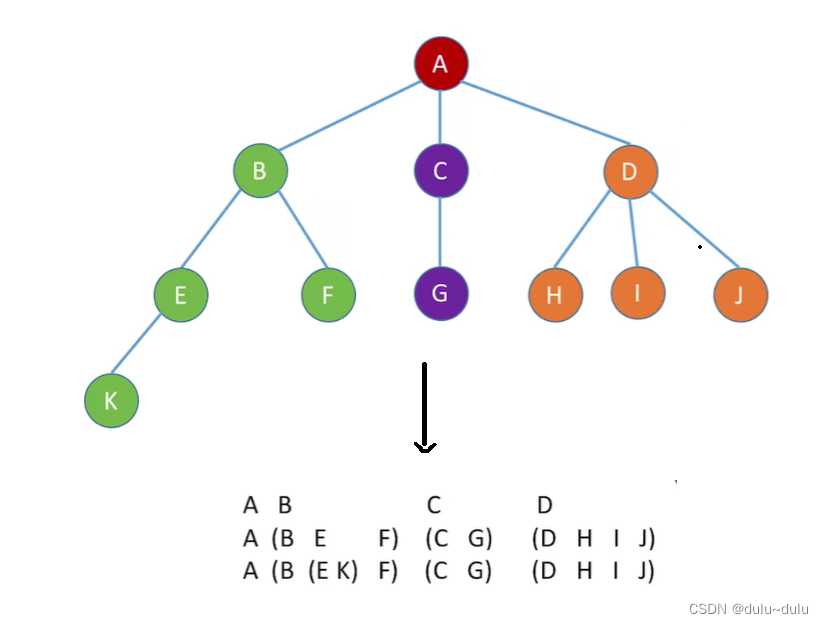
将其对应的二叉树画出来,可以观察到,树的先根遍历序列与这棵树相应二叉树的先序序列相同。
2.后根遍历

转换为对应二叉树后,树的后根遍历序列与这棵树相应二叉树的中序序列相同。
3.层次遍历
与二叉树的层次遍历相同:
① 若树非空,则根节点入队
② 若队列非空,队头元素出队并访问,同时将该元素的孩子依次入队
③ 重复②直到队列为空
注:树的层次遍历可以称为广度优先遍历;相对地,先根遍历和后根遍历可以称为深度优先遍历。
三.森林的遍历
1.森林的先序遍历
若森林为非空,则按如下规则进行遍历:
1.访问森林中第一棵树的根结点。
2.先序遍历第一棵树中根结点的子树森林。
3.先序遍历除去第一棵树之后剩余的树构成的森林。
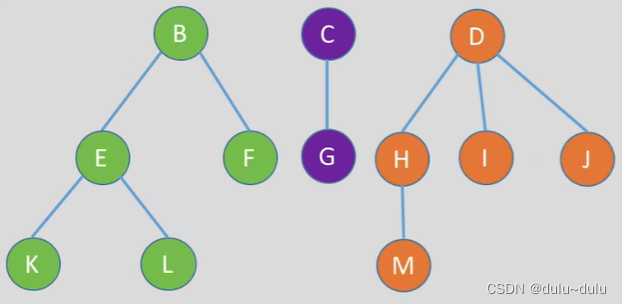
如下图所示,① 先访问B,在访问第一棵树中根节点的子树森林,即以E,F为根节点的森林。② 递归到第一步,访问子树森林中第一棵树的根节点,即E,再先序遍历E的两棵子树森林K,L。③ 先序遍历除去第一棵树之后剩余的树构成的森林,即F。
其等同于依次对各个树进行先根遍历,最后结果如下:
或者可以将森林先转换为二叉树,森林的先序遍历序列和二叉树的先序遍历序列也是相同的。

2.森林的中序遍历
1.中序遍历森林中第一棵树的根结点的子树森林。
2.访问第一棵树的根结点。
3.中序遍历除去第一棵树之后剩余的树构成的森林。
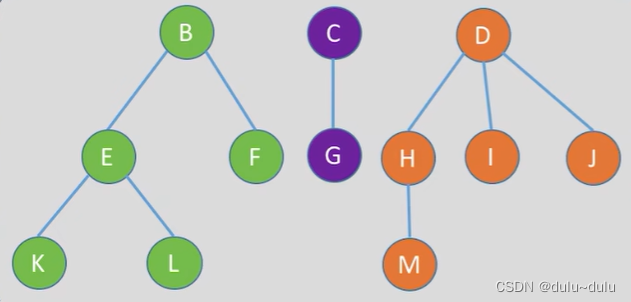
对森林的中序遍历,效果等同于依次对各个树进行后根遍历,结果如下:
或者可以把他转化为对应的二叉树,森林的中序遍历,效果等同于对应二叉树的中序遍历。
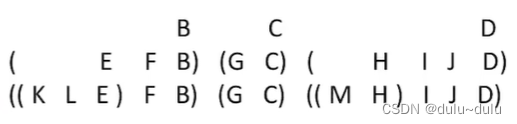
总结:
森林的先序遍历效果等同于森林中各个树的先根遍历,也等同于对二叉树的先序遍历
森林的中序遍历效果等同于森林中各个树的后根遍历,也等同于对二叉树的中序遍历

四.哈夫曼树
1.带权路径长度
•结点的权:有某种现实含义的数值(如:表示结点的重要性等),下图所示,每一个结点都有对应的权值。
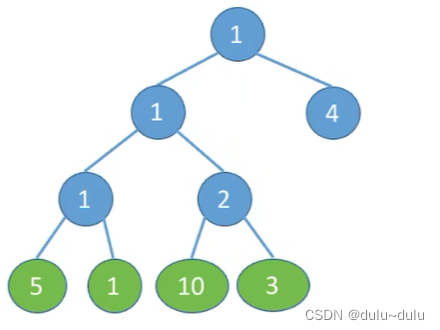
•结点的带权路径长度:从树的根到该结点的路径长度(经过的边数)与该结点上权值的乘积。
例如,权值为3的结点:从根结点到权值为3的结点的路径长度为3,所以其带权路径长度为3*3=9.
•树的带权路径长度:树中所有叶结点的带权路径长度之和(WPL,Weighted Path Length)

注:树的路径长度是指根到每个结点的路径长的总和,根到每个结点的路径长度的最大值应是树的高度-1,注意与这里做区别。
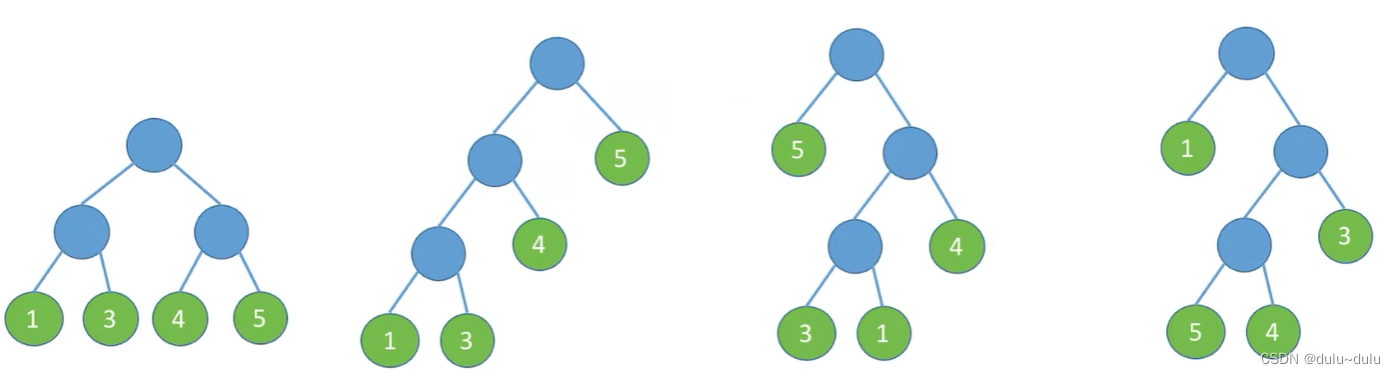
例如:
第一个图中,叶子结点有4个,根到各个结点的路径长度是2,所以这棵树的带权路径长度:
2*1+2*3+2*4+2*5=26
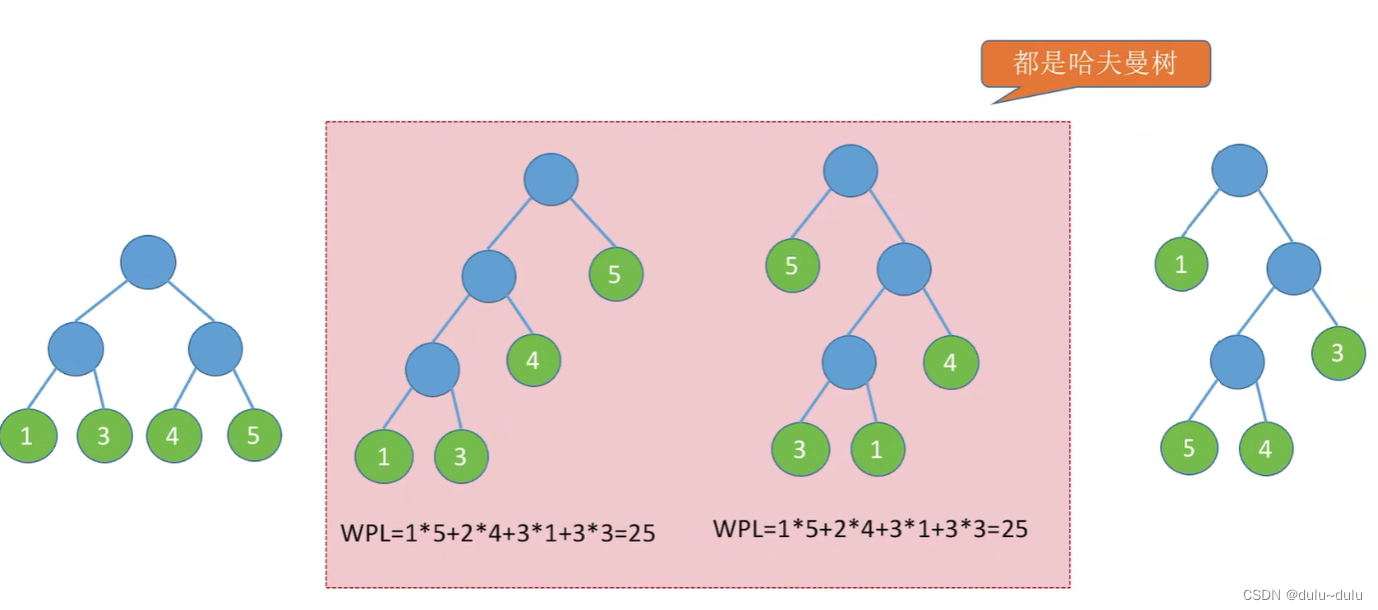
第二个图中,叶子结点有4个,根到1,3,4,5的路径长度为3,3,2,1,所以带权路径长度:1*5+2*4+3*1+3*3=25
第三个图同理,带权路径长度为:1*5+2*4+3*1+3*3=25
第四个图的带权路径长度为:1*1+2*3+3*5+3*4=34
•哈夫曼树:在含有n个带权叶结点的二叉树中,其中带权路径长度(WPL)最小的二叉树称为哈夫曼树,也称最优二叉树。上面计算的中间两棵树都是哈夫曼树。
2.构造哈夫曼树
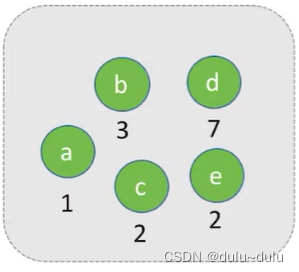
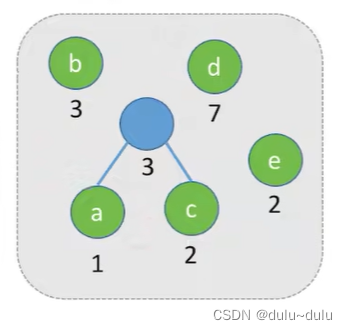
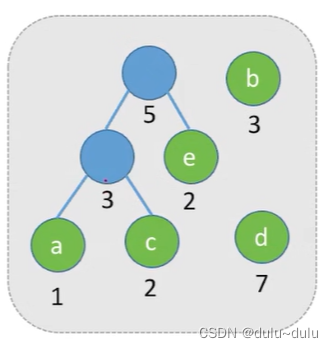
(1) 将这n个结点分别作为n棵仅含一个结点的二叉树,构成森林F。
(2) 构造一个新结点,从F中选取两棵根结点权值最小的树作为新结点的左、右子树,并且将新结点的权值置为左、右子树上根结点的权值之和。
(3) 从F中删除刚才选出的两棵树,同时将新得到的树加入F中。(当然也可以选择e和b)
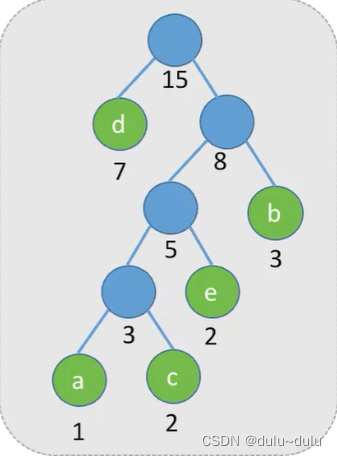
(4) 重复步骤2)和3),直至F中只剩下一棵树为止。
这棵树的带权路径长度
=1*7+2*3+3*2+4*1+4*2=31
从上面可以观察到:
• 每个初始结点最终都成为叶结点,且权值越小的结点到根结点的路径长度越大。
•n个结点,两两结合为一棵树,总共需要合并n-1次,每一次合并都会增加一个结点,所以哈夫曼树的结点总数为n+n-1=2n-1个。
•哈夫曼树中不存在度为1的结点。
•哈夫曼树并不唯一,但WPL必然相同且为最优。
3.哈夫曼编码
对于固定长度编码,每个字符需要用相等长度的二进制位表示,例如:

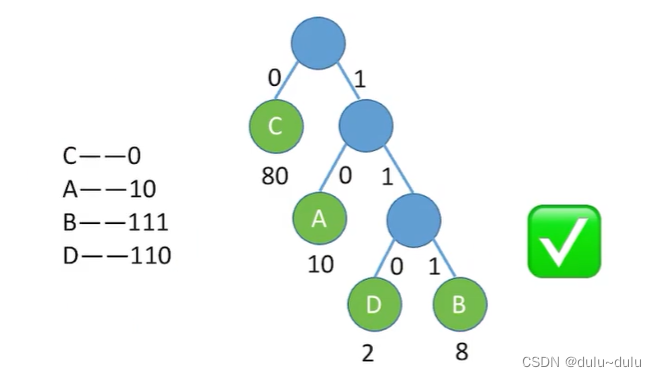
若用权值表示各个字母的使用次数,假设A的使用次数:10,B:8,C:80,D:2,那么其带权路径长度可以这样表示:从根节点出发,向左的路径是二进制0,向右的路径是二进制1(也可以反过来)
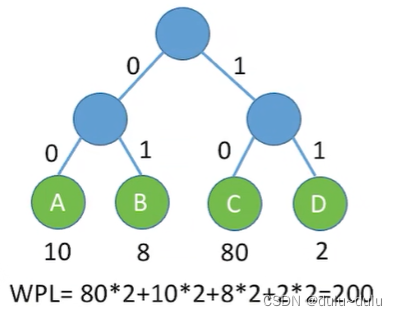
上面这棵树的带权路径长度为200,用A,B,C,D构造哈夫曼树,能使带权路径长度达到最小:
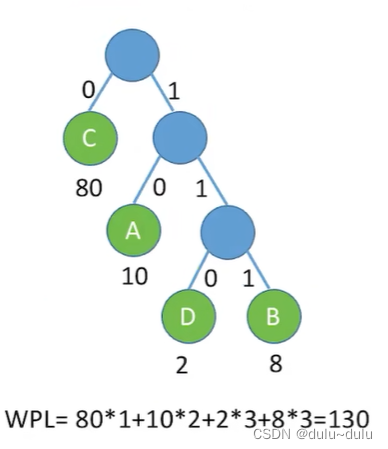
上面这棵树对应的A,B,C,D的编码如下:C使用了最多次,所以C的编码最简单,以这样的逻辑进行编码,那么发送的编码长度就能最小化。
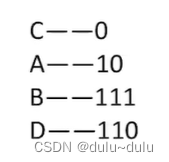
这种编码方式就是可变长度编码,即允许对不同字符用不等长的二进制位表示。
A的使用次数也很高,为什么不能直接将其编码为1呢?也就是A不作为叶子节点
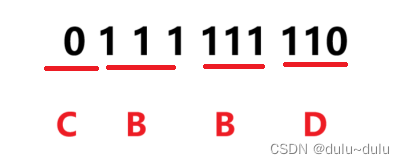
采用这样的编码方式,若要发送CAAABD这样的字符,则发送的二进制编码为:
0 1 1 1 111 110
接收者接收到这一串二进制编码时,可能翻译为:
导致解码错误,产生歧义。
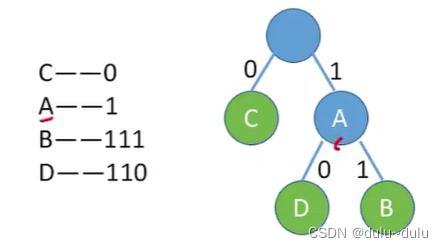
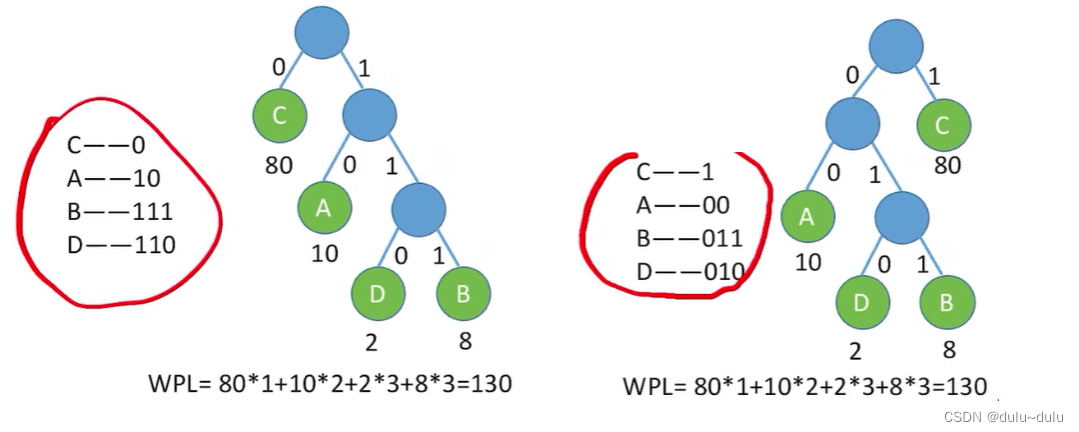
所以A,B,C,D字符只能作为叶子节点,不能当作分支节点。
上面这样的编码也可称为前缀编码,也就是没有一个编码是另一个编码的前缀。采用这种前缀码,解码时才不会产生歧义。
上图,由于A的编码是1,与B,D有相同的前缀,所以会产生解码歧义。
注:之前讲过,对于给定的叶子节点,哈夫曼树是不唯一的,所以哈夫曼编码也是不唯一的。
由于哈夫曼编码能使发送的数据长度达到最小,所以哈夫曼编码也用于数据的压缩。
上图中哈夫曼编码的长度为130,加权平均长度为计算得到的WPL与各编码的权值之和的比值:130/80+10+2+8=13/10

























![[C++初阶]类和对象(三)](https://img-blog.csdnimg.cn/direct/e28ac8b254e7404cb10f81e9c00cbc15.png)