1.导出依赖库文件
原生python环境
pip freeze这是最常用的方法,适用于任何基于pip的Python环境,无论是全局环境还是虚拟环境(如venv或virtualenv)。requirements.txt通常用于纯Python项目,不包括C库等非Python依赖。
导出所有已安装依赖:
pip freeze > requirements.txt
将当前环境中所有已安装的库及其版本信息输出到requirements.txt文件中。
精简导出项目依赖:
仅导出项目实际使用的依赖,可以自动检测项目中哪些库被实际引用并生成更精确的依赖列表:
pipreqs ./ --encoding=utf8 --force
安装命令:
pip install -r requirements.txt
conda环境
导出当前conda环境的所有包到一个environment.yml文件中,这个文件包含了conda环境中的所有依赖(包名和版本),包括Python包和非Python库,也可以用来完全恢复整个conda环境。
conda list --export > environment.yml
安装命令:
conda env create -f environment.yml
2.保存和导出PMML文件
PMML(Predictive Model Markup Language):预测模型标记语言,它是通过XML格式来描述生成的机器学习模型。通常训练好的模型需要在生产环境中部署和使用,一般导出为PMML格式,以便在其他平台上部署使用,再使用目标环境解析PMML文件的库来加载模型,并做出预测。
优点:PMML采用标准的XML格式保存模型,支持很多常用的开源模型转换成PMML文件。支持文本编辑器打开查阅,可以实现跨平台部署,易于使用Java调用。
缺点:对数据预处理的支持有限,支持几乎所有的标准数据处理方式,但对于自拓展的还缺乏有效支持。缺乏对深度学习模型的支持。
3.示例
# -*- coding: utf-8 -*-
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import tree
from sklearn import metrics
from sklearn.metrics import classification_report
from sklearn2pmml import sklearn2pmml
from sklearn2pmml.pipeline import PMMLPipeline
class TreeModel:
def __int__(self):
pass
@staticmethod
def load_data():
iris = datasets.load_iris()
iris_features = iris.data
iris_target = iris.target
feature_name = iris.feature_names
train_x, test_x, train_y, test_y = train_test_split(iris_features,
iris_target,
test_size=0.3,
random_state=123)
return train_x, test_x, train_y, test_y, feature_name
def train_test_model(self):
train_x, test_x, train_y, test_y, feature_name = self.load_data()
model = tree.DecisionTreeClassifier(criterion='gini')
model.fit(train_x, train_y)
model.score(train_x, train_y)
y_pre = model.predict(test_x)
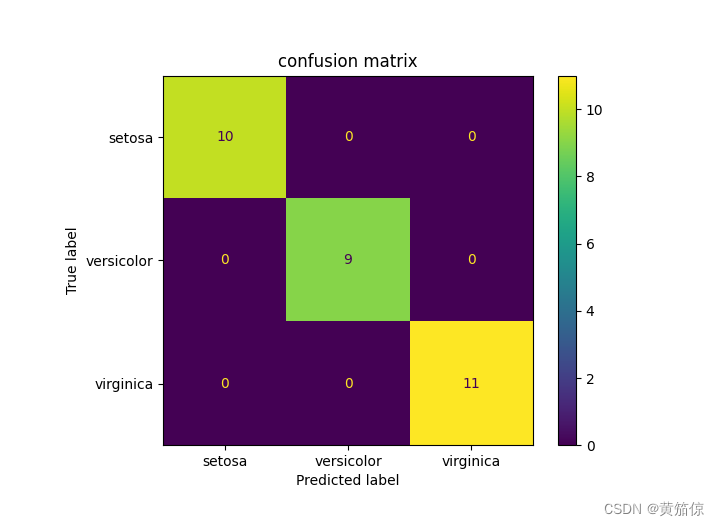
tree_matrix = metrics.confusion_matrix(test_y, y_pre)
print('混淆矩阵:\n', tree_matrix)
print('结果分类报告:\n', classification_report(test_y, y_pre))
# 特征重要性
feature_important = pd.DataFrame([*zip(feature_name, model.feature_importances_)],
columns=['features', 'Gini importance'])
print('特征重要度:\n', feature_important.sort_values(by='Gini importance'))
return model
def exe_func(self):
model = self.train_test_model()
# 创建一个PMMLPipeline对象
pipline2 = PMMLPipeline([
('classifier', model)
])
# 导出模型为PMML格式
sklearn2pmml(pipline2, 'model.pmml')
if __name__ == '__main__':
TreeModel().exe_func()



















![[C++初阶]类和对象(三)](https://img-blog.csdnimg.cn/direct/e28ac8b254e7404cb10f81e9c00cbc15.png)