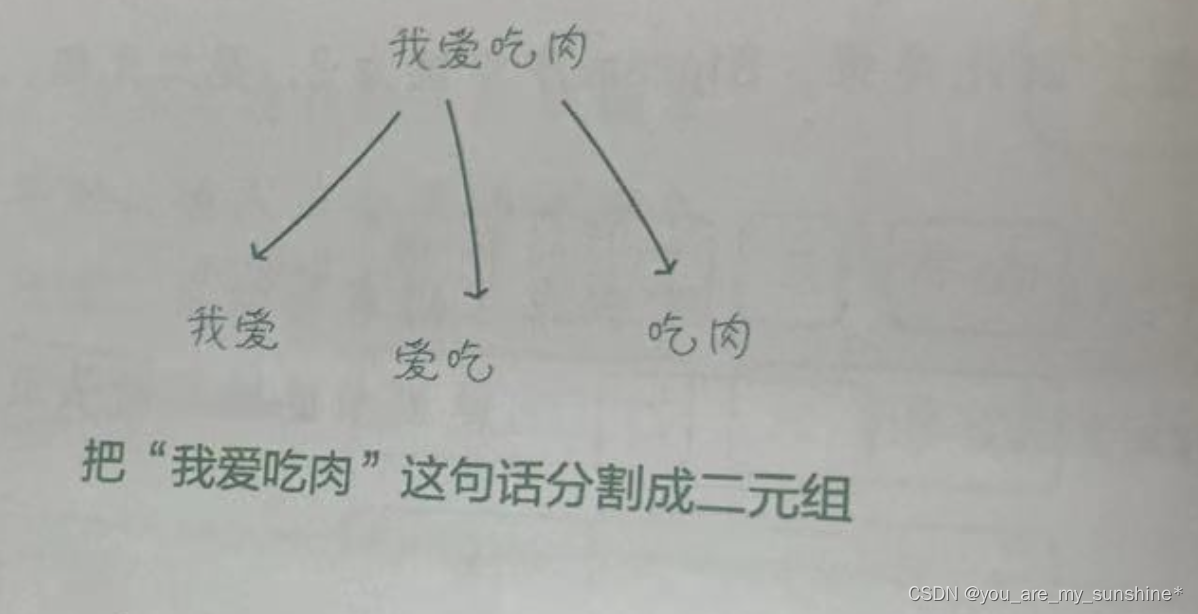
N-gram是一种基于统计的语言模型,它基于一个假设,即一个词的出现仅与它前面的N-1个词有关,而与更远的词无关。
N-gram模型通常用于自然语言处理(NLP)任务,如文本生成、文本分类、机器翻译、拼写检查和语音识别等。在N-gram模型中,文本被分解为一连串连续的词或字节片段,这些片段被称为grams。模型通过统计这些grams在训练语料库中的出现频率来估计下一个词出现的概率。
例如,一个2-gram(Bi-gram)模型考虑的是连续两个词的序列,如“I love”;而3-gram(Tri-gram)模型则是三个词的序列,如“I love you”。N-gram模型的优点是简单且能够有效处理文本数据,但它的一个主要缺点是无法捕捉长距离的依赖关系,因此在处理复杂语言结构时可能效果不佳。在实际应用中,N-gram模型通常与其他更复杂的模型(如神经网络语言模型)结合使用。