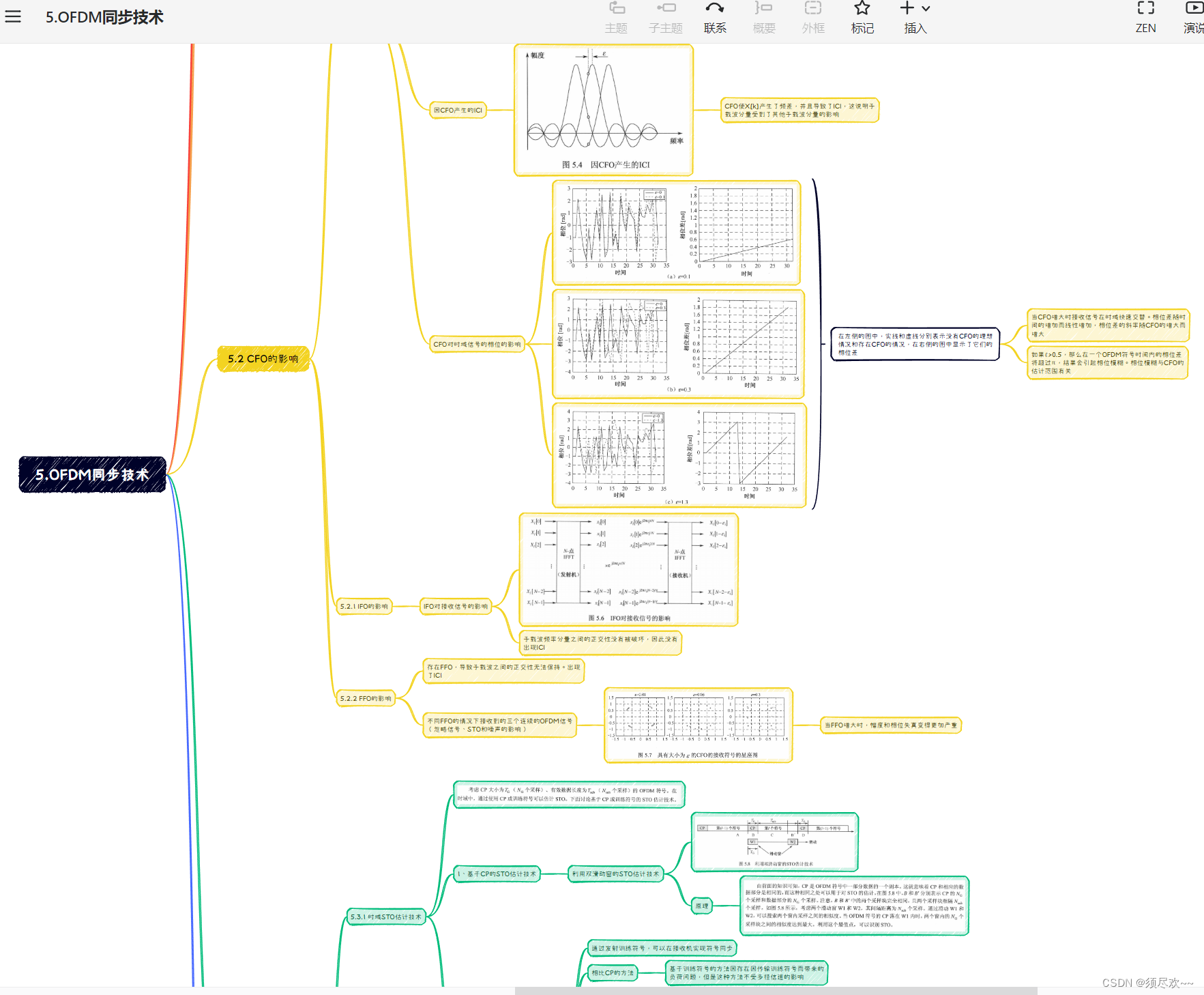
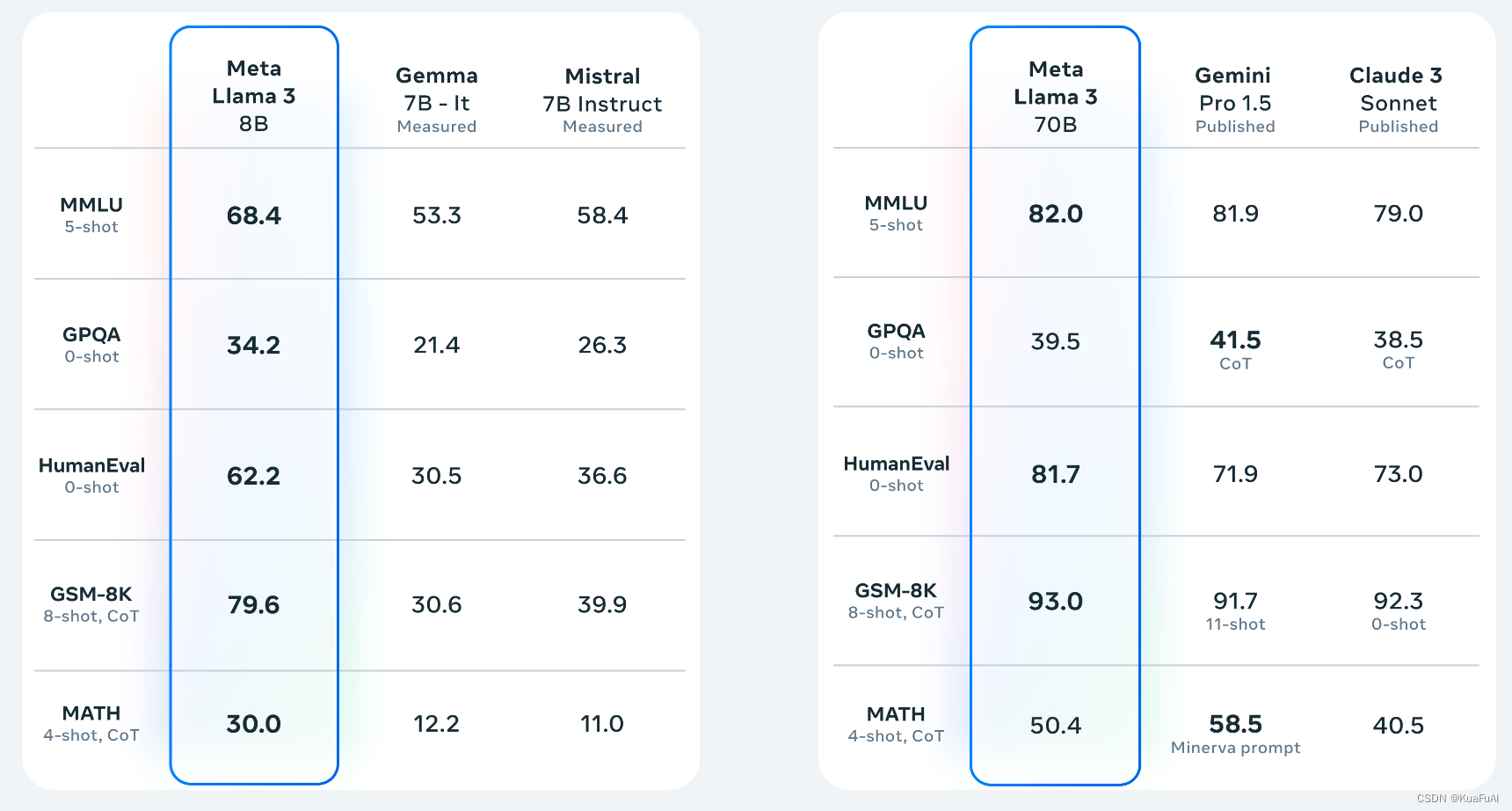
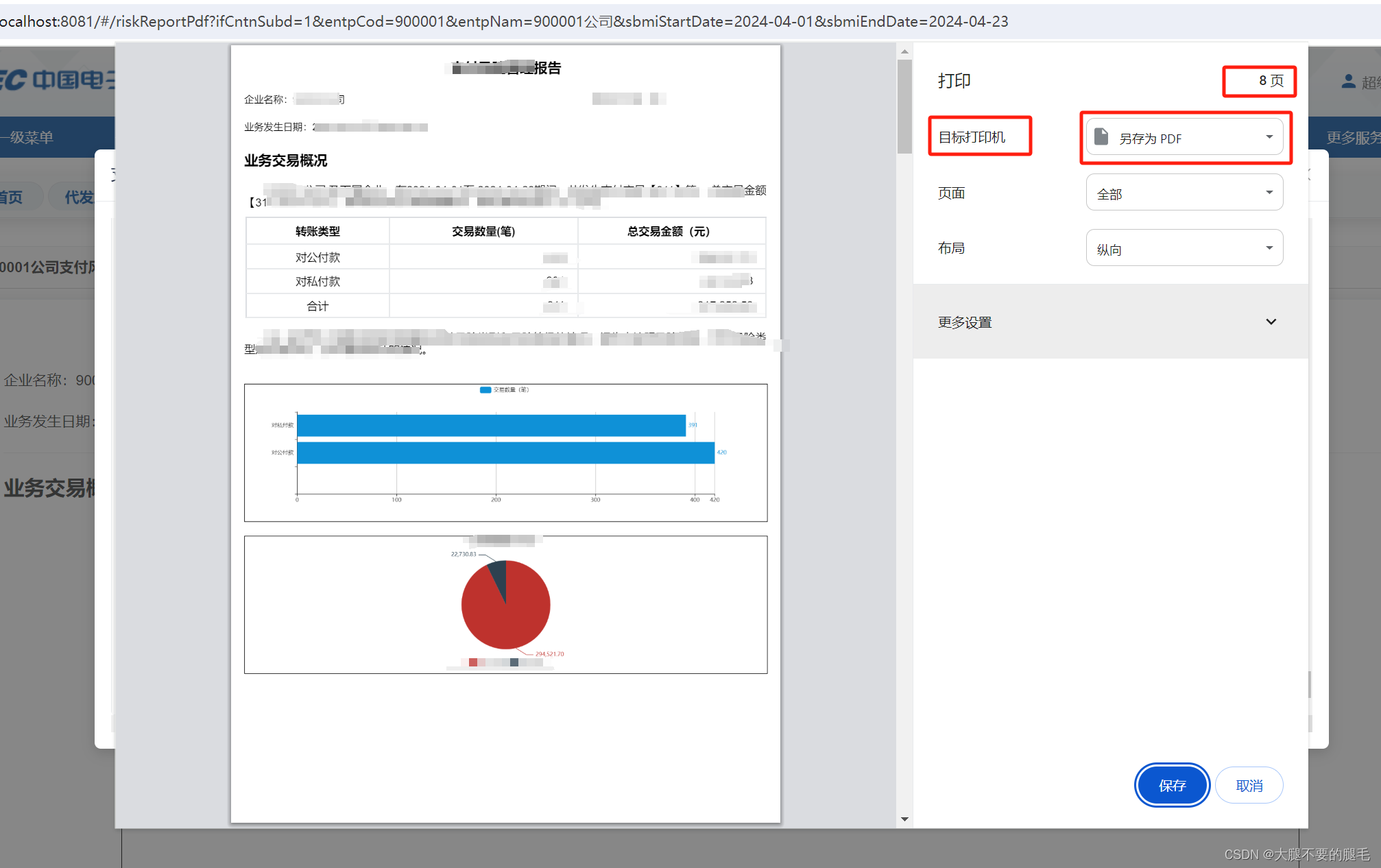
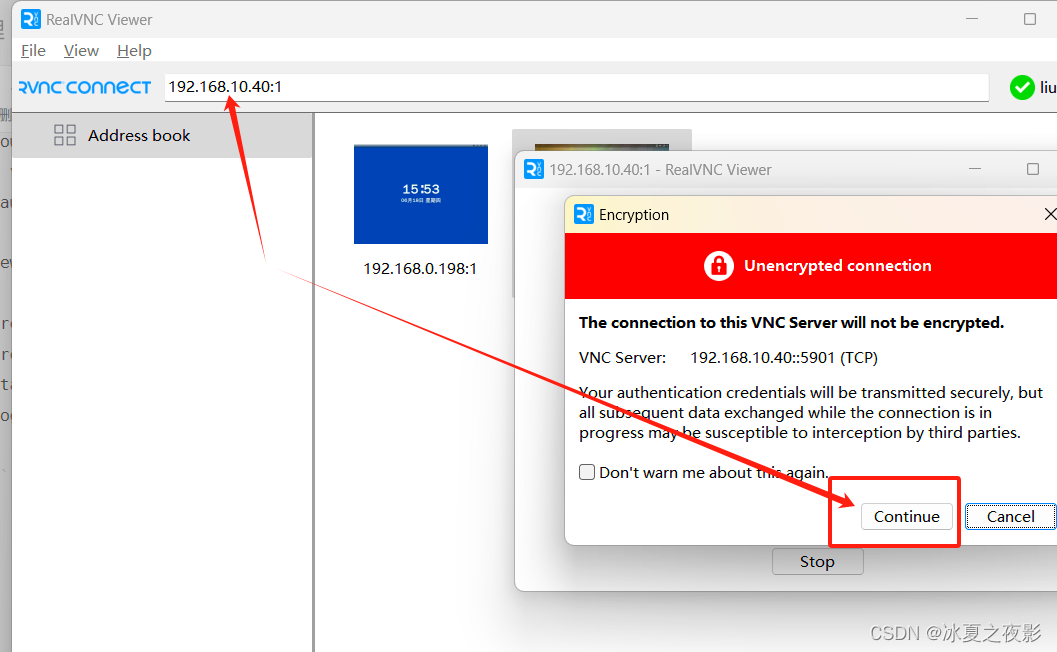
核函数:kernelFunc<<<grideDim,blockDim,nSem,iStream>>>(args)
多少个块,多少个线程,共享内存,流
kernenl1<<<size_element/128,128,0,stream[1]>>(Md);
Md为类对象
cudaStreamCreate 创建流并发
cudaMalloc() 申请内存
cudaDeviceSyncchronize() 异步,暂停cpu执行,等待执行gpu执行完成
cudaMecpyHostToDevice()
cudaMecpyDeviceTohost() 内存拷贝
device 在设备处执行,在设备处调用,
global 核函数定义,在设备处执行,在主机处调用





















![[Meachines][Medium]IClean](https://img-blog.csdnimg.cn/img_convert/aaffd918d0aed9bff086b15fe4b79d80.jpeg)