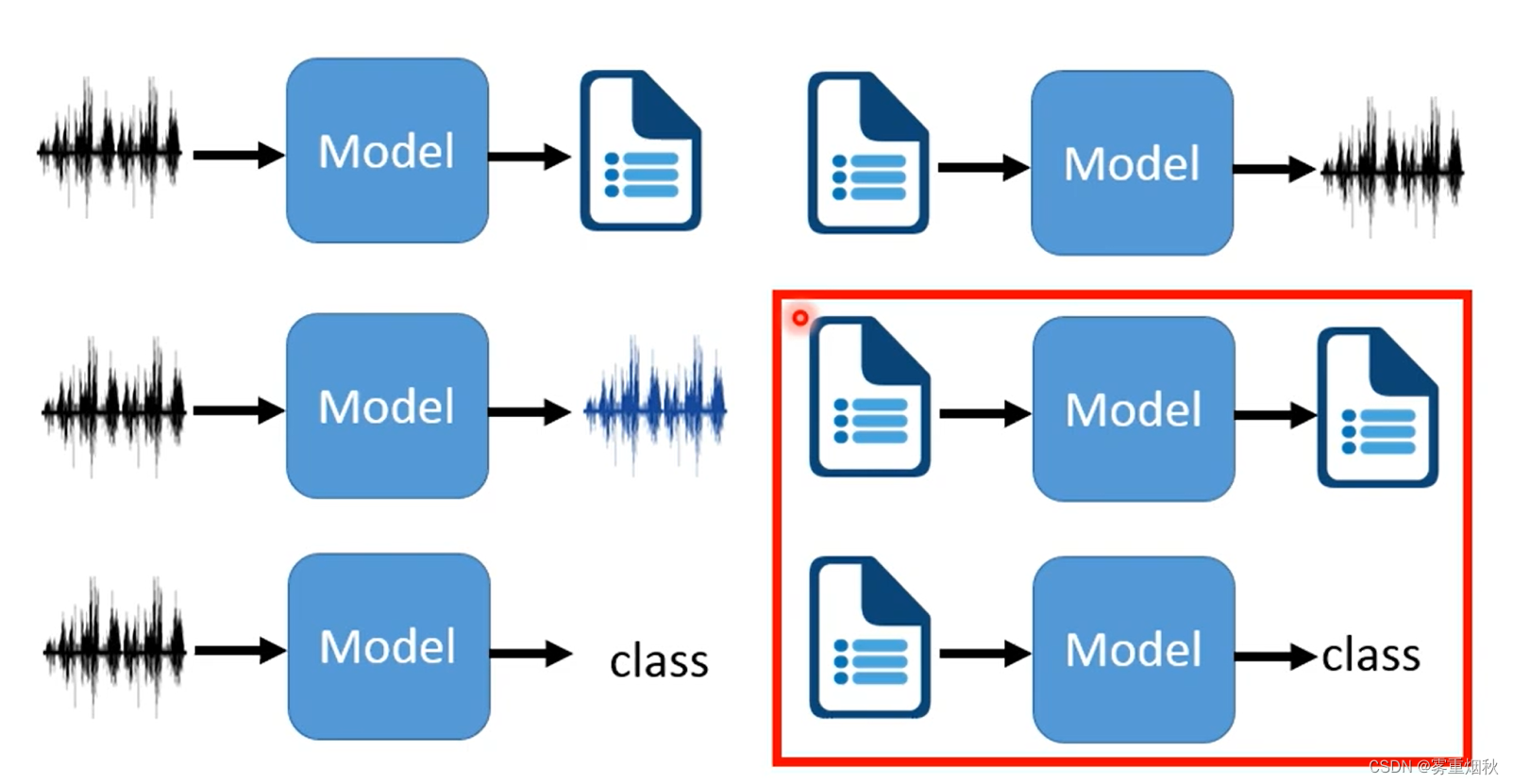
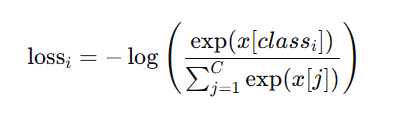自然语言处理(Natural Language Processing, 简称NLP)是计算机科学与语言学中关注于计算机与人类语言间转换的领域。NLP将非结构化文本数据转换为有意义的见解,促进人与机器之间的无缝通信,使计算机能够理解、解释和生成人类语言。人类等主要通过语言、文字进行交流,自然语言处理实际上是对人类思想数据的处理,诸如通义千问、文心一言、ChatGPT等都属于NLP,是人工智能的一个关键领域。
通常,NLP = NLU + NLG,NLU-Neural Language Understanding指的自然语言理解,NLG-Neural Language Generation指的自然语言生成。两者是相辅相成的,只有做好NLU才能做好NLG,做好NLG就可以做很多有趣的落地。
一、词法分析(Lexical Analysis)
对自然语言进行词汇层面的分析,是NLP基础性工作
分词(Word Segmentation/Tokenization):对没有明显边界的文本进行切分,得到词序列
新词发现(New Words Identification):找出文本中具有新形势、新意义或是新用法的词
形态分析(Morphological Analysis):分析单词的形态组成,包括词干(Sterms)、词根(Roots)、词缀(Prefixes and Suffixes)等
词性标注(Part-of-speech Tagging):确定文本中每个词的词性。词性包括动词(Verb)、名词(Noun)、代词(pronoun)等
拼写校正(Spelling Correction):找出拼写错误的词并进行纠正
二、句子分析(Sentence Analysis)
对自然语言进行句子层面的分析,包括句法分析和其他句子级别的分析任务
组块分析(Chunking):标出句子中的短语块,例如名词短语(NP),动词短语(VP)等
超级标签标注(Super Tagging):给每个句子中的每个词标注上超级标签,超级标签是句法树中与该词相关的树形结构
成分句法分析(Constituency Parsing):分析句子的成分,给出一棵树由终结符和非终结符构成的句法树
依存句法分析(Dependency Parsing):分析句子中词与词之间的依存关系,给一棵由词语依存关系构成的依存句法树
语言模型(Language Modeling):对给定的一个句子进行打分,该分数代表句子合理性(流畅度)的程度
语种识别(Language Identification):给定一段文本,确定该文本属于哪个语种
句子边界检测(Sentence Boundary Detection):给没有明显句子边界的文本加边界
三、语义分析(Semantic Analysis)
对给定文本进行分析和理解,形成能勾够表达语义的形式化表示或分布式表示
词义消歧(Word Sense Disambiguation):对有歧义的词,确定其准确的词义
语义角色标注(Semantic Role Labeling):标注句子中的语义角色类标,语义角色,语义角色包括施事、受事、影响等
抽象语义表示分析(Abstract Meaning Representation Parsing):AMR是一种抽象语义表示形式,AMR parser把句子解析成AMR结构
一阶谓词逻辑演算(First Order Predicate Calculus):使用一阶谓词逻辑系统表达语义
框架语义分析(Frame Semantic Parsing):根据框架语义学的观点,对句子进行语义分析
词汇/句子/段落的向量化表示(Word/Sentence/Paragraph Vector):研究词汇、句子、段落的向量化方法,向量的性质和应用
四、信息抽取(Information Extraction)
从无结构文本中抽取结构化的信息
命名实体识别(Named Entity Recognition):从文本中识别出命名实体,实体一般包括人名、地名、机构名、时间、日期、货币、百分比等
实体消歧(Entity Disambiguation):确定实体指代的现实世界中的对象
术语抽取(Terminology/Giossary Extraction):从文本中确定术语
共指消解(Coreference Resolution):确定不同实体的等价描述,包括代词消解和名词消解
关系抽取(Relationship Extraction):确定文本中两个实体之间的关系类型
事件抽取(Event Extraction):从无结构的文本中抽取结构化事件
情感分析(Sentiment Analysis):对文本的主观性情绪进行提取
意图识别(Intent Detection):对话系统中的一个重要模块,对用户给定的对话内容进行分析,识别用户意图
槽位填充(Slot Filling):对话系统中的一个重要模块,从对话内容中分析出于用户意图相关的有效信息
五、顶层任务(High-level Tasks)
直接面向普通用户,提供自然语言处理产品服务的系统级任务,会用到多个层面的自然语言处理技术
机器翻译(Machine Translation):通过计算机自动化的把一种语言翻译成另外一种语言
文本摘要(Text summarization/Simplication):对较长文本进行内容梗概的提取
阅读理解(Reading Comprehension):机器阅读完一篇文章后,给定一些文章相关问题,机器能够回答
自动文章分级(Automatic Essay Grading):给定一篇文章,对文章的质量进行打分或分级
问答系统(Question-Answering Systerm):针对用户提出的问题,系统给出相应的答案
对话系统(Dialogue Systerm):能够与用户进行聊天对话,从对话中捕获用户的意图,并分析执行
智能生成系统(Intent Generation Systerm):机器学习完相关的给定知识后,机器能够在给定的前提条件下自动生成具有一定意图的内容
NLP任务面临的挑战
自然语言处理(NLP)作为一门研究和应用广泛的技术领域,在推动人工智能与人类语言交互方面发挥了重要作用。然而,尽管取得了诸多进展,NLP任务仍然面临一系列挑战,其中包括但不限于:
1、数据稀缺性和标注困难
- NLP任务通常需要大量的标注数据来训练模型,但获取这些数据往往是一项艰巨的任务。
- 标注数据的质量和数量直接影响模型的性能,而标注工作本身既耗时又易出错,特别是对于一些复杂的NLP任务,如关系抽取或事件检测,需要专业的语言学知识。
2、语义理解的复杂性
- 自然语言具有丰富的语义和上下文依赖关系,这使得准确理解文本含义成为一项极具挑战性的任务。
- 同一句话在不同的语境下可能有不同的意义,而NLP模型需要能够捕捉这些细微的差别,以实现精确的理解和推理。
3、多义性和歧义性
- 词汇和短语在自然语言中常常具有多义性,即同一词汇或短语在不同的上下文中有不同的意义。
- 歧义性则是指某些句子或段落的结构和含义可能存在不确定性,需要借助额外的上下文或知识才能准确理解。
4、模型的可解释性和可复现性
- 深度学习模型在处理NLP任务时取得了显著的效果,但这些模型往往被视为“黑盒子”,其决策过程难以解释。
- 这在某些应用场景下是不可接受的,如法律或医疗领域,需要对模型的决策进行审查。
- 此外,由于深度学习模型的性能受到多种因素的影响(如初始化、超参数设置等),模型的可复现性也是一个重要挑战。
5、跨语言处理
- NLP任务通常涉及多种语言,而不同语言之间的语法、词汇和语义差异给跨语言处理带来了挑战。
- 尽管有些技术(如机器翻译)可以在一定程度上解决跨语言处理的问题,但如何有效地利用 - - 不同语言之间的共享信息仍然是一个难题。
6、技术更新与算法选择
- NLP领域的技术和算法不断更新,新的模型和方法不断涌现。
- 选择合适的算法和技术对于解决NLP任务至关重要,但这也增加了任务的复杂性和挑战性。
综上所述,NLP任务面临着多方面的挑战,这些挑战需要研究者们不断探索和创新,以推动NLP技术的不断发展和进步。