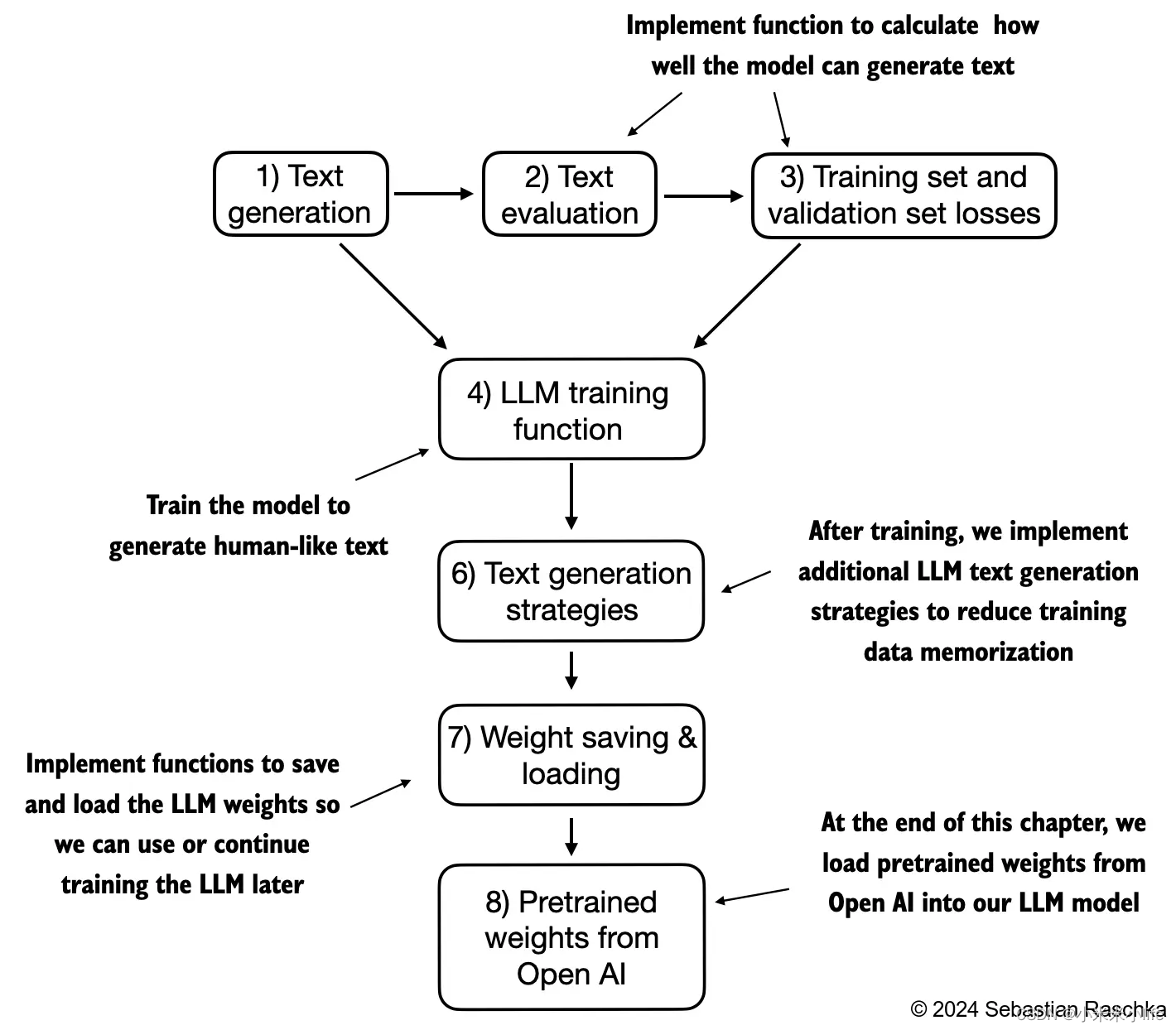
一、技术层面
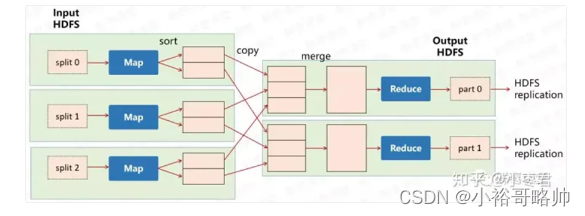
通过下面这张图,我们可以大概确定,在大数据行业里,自己的学习路线。
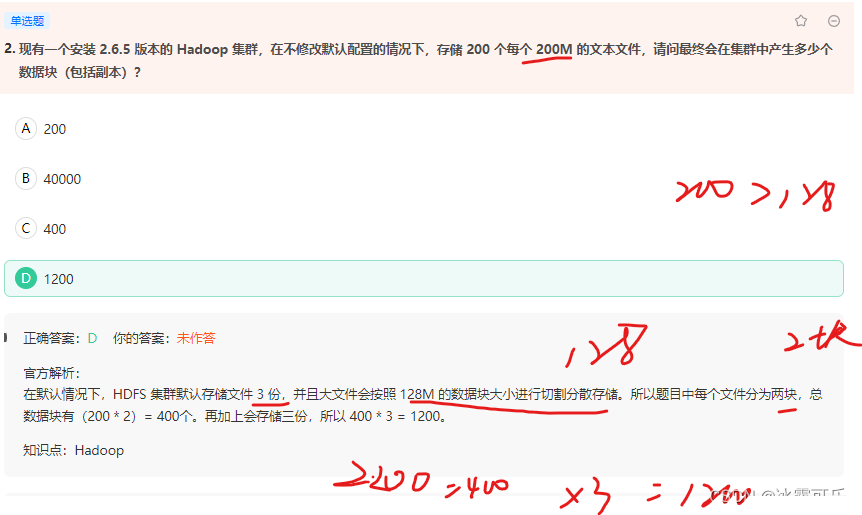
个人认为,Hadoop集群一旦搭建完工,基本就是个把人运维的事情
主要岗位应该是集中在数据计算层,尤其是实时计算!
实时计算框架比较实用的是Spark Streaming 和 Flink
数据传输层,有叫数据采集层,将不同的数据源中的各种类型数据,采集到Hadoop中进行存储
Flume组件,个人觉得与Logstash组件等效。
这里的定时任务,任务之间是可以相互依赖的
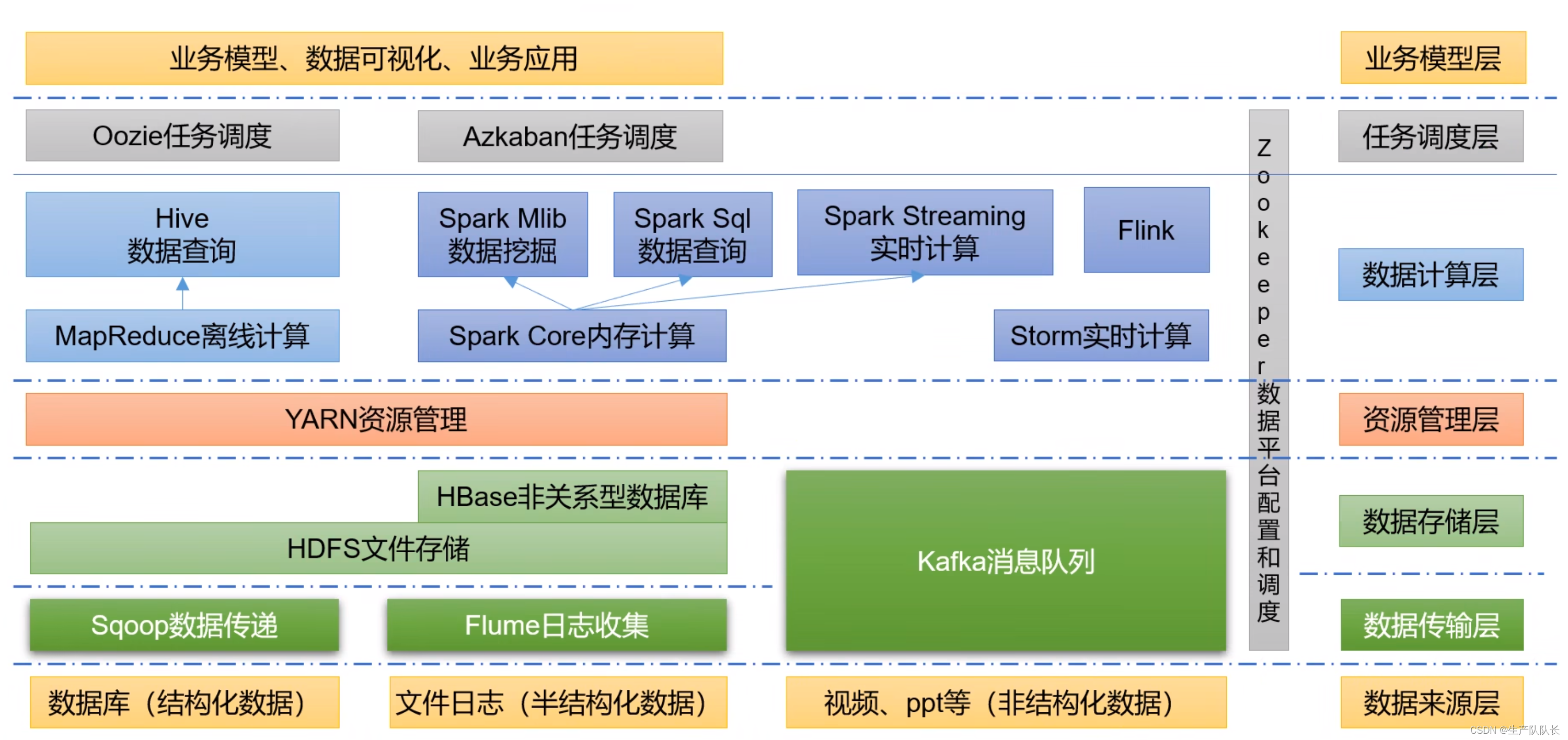
二、业务层面
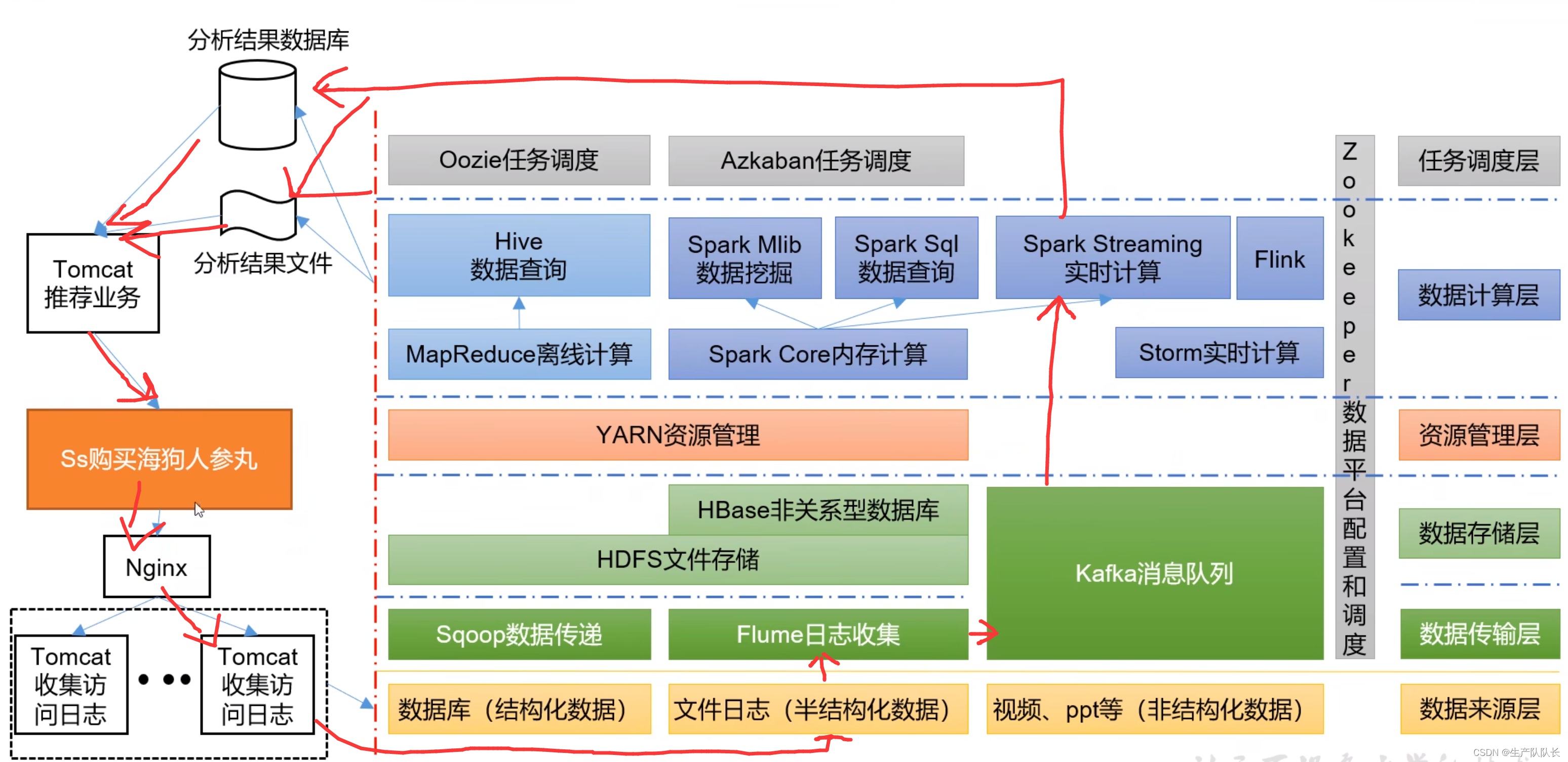
个人偏好推荐功能































![[阅读笔记25][WebArena]A Realistic Web Environment for Building Autonomous Agents](https://img-blog.csdnimg.cn/direct/aed12c1ba3fe46868b4dd478d74319a6.png)