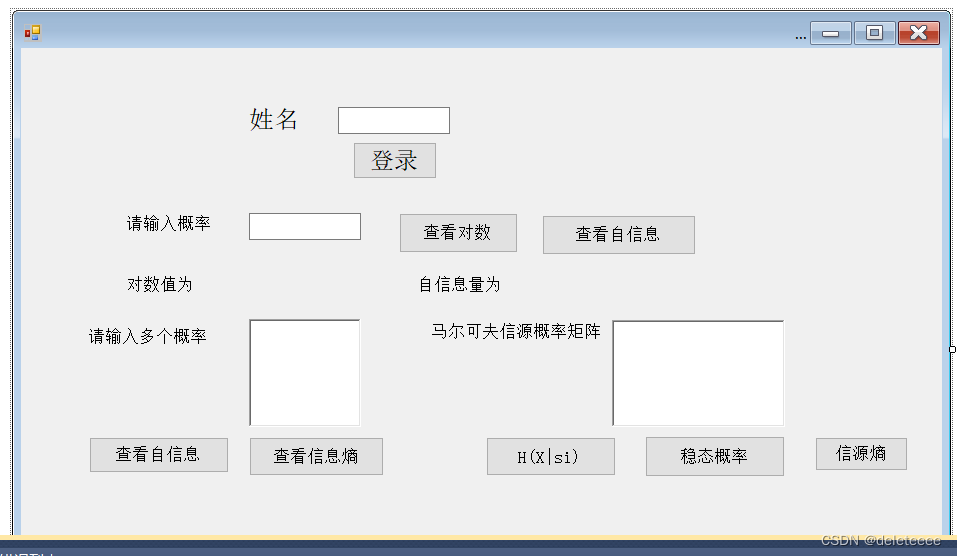
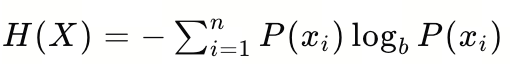信息熵是衡量DNA序列复杂度的常用方法之一,它基于信息论的概念,用于评估序列中碱基的分布情况和随机性。信息熵越高,表示序列越复杂、越随机。
#include <iostream>
#include <unordered_map>
#include <cmath>
double calculateEntropy(const std::string& sequence) {
std::unordered_map<char, int> baseCounts;
int totalBases = 0;
// 统计每种碱基的频率
for (char base : sequence) {
if (base == 'A' || base == 'C' || base == 'G' || base == 'T') {
baseCounts[base]++;
totalBases++;
}
}
// 计算信息熵
double entropy = 0.0;
for (const auto& pair : baseCounts) {
double probability = static_cast<double>(pair.second) / totalBases;
entropy -= probability * log2(probability);
}
return entropy;
}
int main() {
// 示例DNA序列
std::string dnaSequence = "ATCGATCGATCGATCG";
// 计算DNA序列的信息熵
double entropy = calculateEntropy(dnaSequence);
std::cout << "DNA序列的信息熵(复杂度): " << entropy << " 比特" << std::endl;
return 0;
}