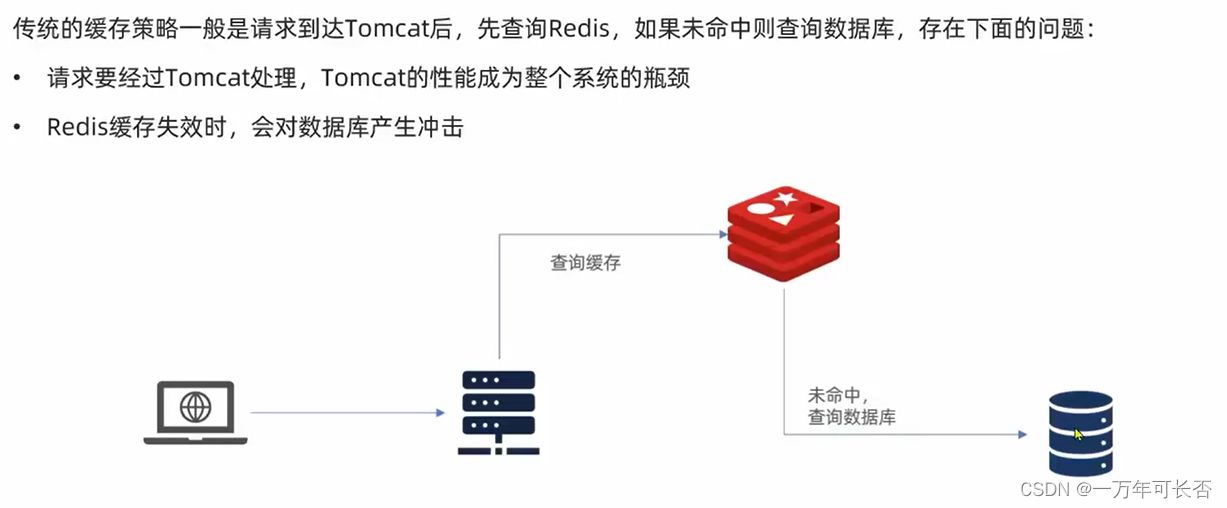
前言
Redis多级缓存系列文章:
Redis从入门到精通(十六)多级缓存(一)Caffeine、JVM进程缓存
Redis从入门到精通(十七)多级缓存(二)Lua语言入门、OpenResty集群的安装与使用
Redis从入门到精通(十八)多级缓存(三)OpenResty请求参数处理、Lua脚本查询Redis和Tomcat
6.5 实现多级缓存
6.5.6 Nginx本地缓存
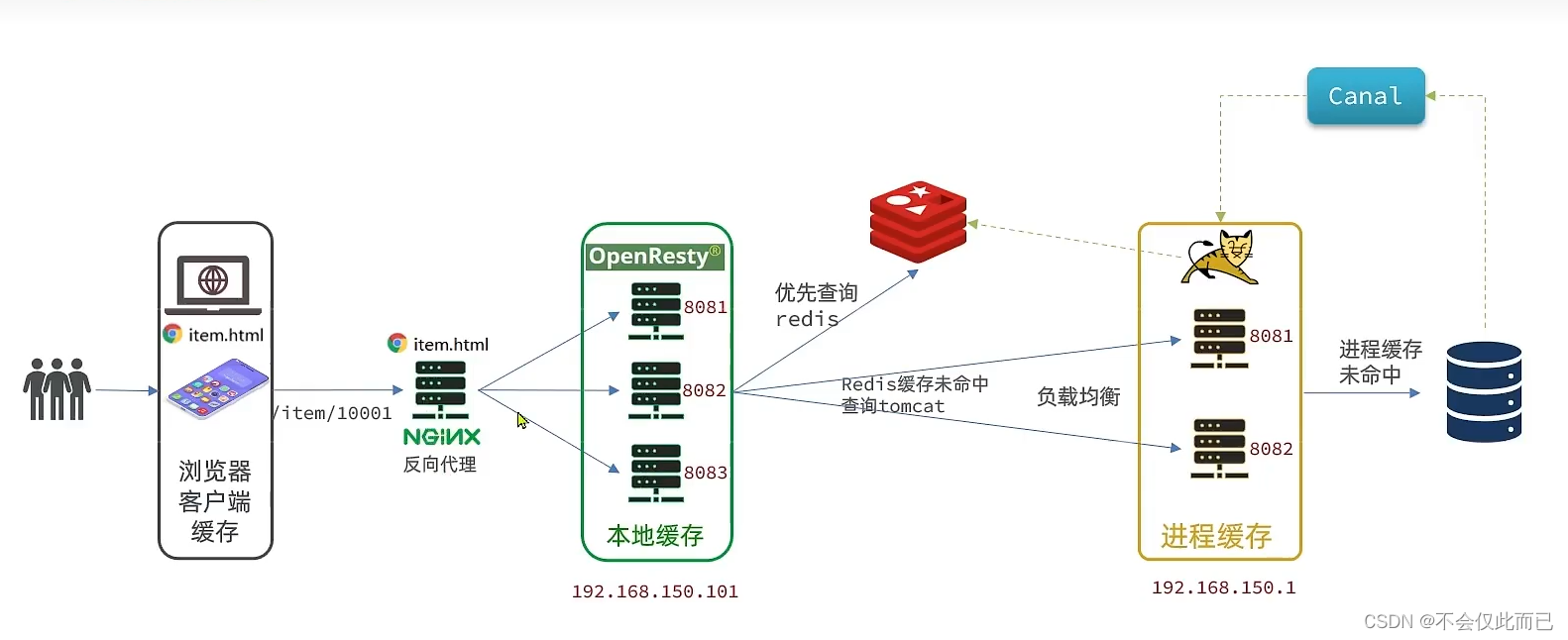
经过前面两节的开发,整个多级缓存只差最后一环,就是Nginx本地缓存,如图:
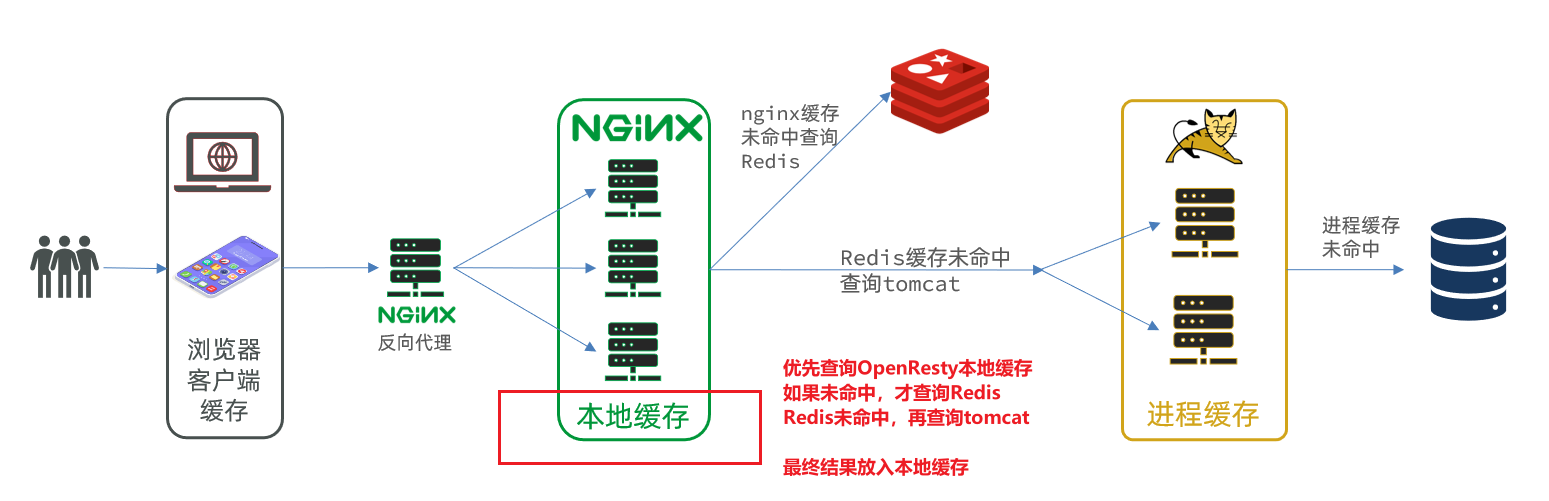
OpenResty为Nginx提供了共享字典的功能,用于在Nginx的多个worker之间共享数据,实现缓存功能。
6.5.6.1 代码实现
要开启共享字典,需要在nginx.conf文件的http块下添加配置:
# 共享字典,也就是本地缓存,名称叫做:item_cache,大小150m
lua_shared_dict item_cache 150m;
然后修改/usr/local/openresty/nginx/lua/item.lua文件,实现Nginx本地缓存查询:
...
-- 导入共享词典
local item_cache = ngx.shared.item_cache
-- 封装函数,查询Redis数据
function read_data(key, expire, path, params)
-- 查询本地缓存
local val = item_cache:get(key)
if not val then
ngx.log(ngx.ERR, "[本地缓存查询失败,尝试查询Redis,", key, "]")
-- 查询Redis
val = read_redis("192.168.146.128", 6379, key)
if not val then
ngx.log(ngx.ERR, "[Redis查询失败,尝试查询HTTP," .. key .. "]")
-- Redis查询失败,去查询HTTP
val = read_http(path, params)
else
ngx.log(ngx.ERR, "[Redis查询成功," .. key .. "]")
end
if val then
-- 查询成功,把数据写入本地缓存
item_cache:set(key, val, expire)
ngx.log(ngx.ERR, "[保存本地缓存成功,", key, "]")
end
else
ngx.log(ngx.ERR, "[本地缓存查询成功,", key, "]")
end
return val
end
...
-- 3.根据ID发起请求查询商品信息
local itemJSON = read_data("item:id:" .. id, 1800, "/dzdp/item/" .. id, nil)
ngx.log(ngx.ERR, "[查询商品信息结果: " .. itemJSON .. "]")
-- 4.根据ID发起请求查询商品库存信息
local itemStockJSON = read_data("item:stock:" .. id, 60, "/dzdp/item/stock/" .. id, nil)
...
修改后,item.lua文件的逻辑是:先查询Nginx本地缓存,查到结果直接返回,未查到结果再去查Redis缓存;Redis查到结果,则将结果写入Nginx本地缓存后返回,否则再去查Tomcat;Tomcat查到结果,则将结果写入Nginx本地缓存后返回,未查到结果则最终返回空。
还需要注意的是,read_data函数新增了一个expire参数,即过期时间,过期后Nginx缓存会自动删除,下次访问时会再次更新缓存。这里给商品信息设置超时时间为30分钟,库存信息为1分钟,因为库存更新频率较高。
6.5.6.2 功能测试
在页面发起请求ID=2的商品信息,会查询Nginx本地缓存失败,然后去Redis中查询:

再次在页面发起请求ID=2的商品信息,由于上一次已经将商品信息保存到了Nginx本地缓存,因此这次会直接查询Nginx本地缓存成功并返回:

至此,多级缓存已全部实现。
6.6 缓存同步
大多数情况下,浏览器查到的都是缓存数据,在多级缓存架构中必须要求缓存数据和数据库数据不存在较大差异,即必须保证缓存数据和数据库数据的一致性。
6.6.1 缓存同步策略
缓存数据同步的常见策略有三种:
1)设置有效期:给缓存设置有效期,到期后自动删除,再次查询时更新
- 优势:简单、方便
- 缺点:时效性差,缓存过期之前可能不一致
- 场景:更新频率较低,时效性要求低的业务
2)同步双写:在修改数据库的同时,直接修改缓存
- 优势:时效性强,缓存与数据库强一致
- 缺点:有代码侵入,耦合度高;
- 场景:对一致性、时效性要求较高的缓存数据
3)异步通知:修改数据库时发送事件通知,相关服务监听到通知后修改缓存数据
- 优势:低耦合,可以同时通知多个缓存服务
- 缺点:时效性一般,可能存在中间不一致状态
- 场景:时效性要求一般,有多个服务需要同步
6.6.2 异步通知策略
而异步通知又可以基于MQ或者Canal来实现:
1)基于MQ:

基于MQ时,商品服务完成对数据的修改后,只需要发送一条消息到MQ中。缓存服务监听MQ消息,然后完成对缓存的更新。但依然有少量的代码侵入。
2)基于Canal:

基于Canal时,商品服务完成商品修改后,业务直接结束,代码零侵入;Canal监听MySQL变化,当发现变化后,立即通知缓存服务;缓存服务接收到canal通知,更新缓存。
Canal,译意为水道/管道/沟渠,是阿里巴巴旗下的一款开源项目,基于Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。GitHub的地址:https://github.com/alibaba/canal
Canal是基于MySQK的主从同步来实现的,MySQL主从同步的原理如下:

- 1)MySQL master 将数据变更写入二进制日志( binary log),其中记录的数据叫做 binary log events。
- 2)MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)。
- 3)MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据。
而Canal就是把自己伪装成MySQL的一个slave节点,从而监听master的binary log变化,再把得到的变化信息通知给Canal的客户端,进而完成对其它数据库的同步。
…
本章完,多级缓存的内容结束。
本章所涉及的代码和资源可从git仓库下载:https://gitee.com/weidag/redis_learning.git
更多内容请查阅分类专栏:Redis从入门到精通
感兴趣的读者还可以查阅我的另外几个专栏: