目录
认识 Buffer Pool
我们知道磁盘的IO是十分缓慢的,当我们每次都需要从磁盘读取内容时,数据库访问速度十分缓慢
那么我们有什么东西可以改进了,我们把一部分经常访问的数据页,放到内存不久解决了吗?
Buffer Pool主要用于提高数据库的性能和效率。
1. 减少磁盘I/O操作:数据库中的数据通常存储在磁盘上,而磁盘I/O是相对较慢的操作。Buffer Pool通过将磁盘上的数据缓存在内存中,可以减少频繁的磁盘I/O操作,从而提高数据库访问速度。
2. 提高数据访问速度:通过将数据缓存在内存中,Buffer Pool可以加快对数据的访问速度。当应用程序请求某个数据时,如果该数据已经在Buffer Pool中,则可以直接从内存中获取,而不必访问磁盘。
3. 降低系统负载: 通过减少磁盘I/O操作和加快数据访问速度,Buffer Pool可以降低数据库系统的负载。这意味着数据库系统可以处理更多的并发请求,提高系统的整体性能和响应速度。
4. 优化内存利用: Buffer Pool管理内存中的数据缓存,可以根据数据库的访问模式和需求动态调整缓存的大小,从而更有效地利用内存资源。
Buffer Pool 分布图

值得注意的是:
当读取数据时,如果数据存在于 Buffer Pool 中,客户端就会直接读取 Buffer Pool 中的数据,否则再去磁盘中读取。(MySQL是一个服务器)
当修改数据时,首先是修改 Buffer Pool 中数据所在的页,然后将其页设置为脏页,最后由后台线程将脏页写入到磁盘。(后台线程异步写入,并不会阻塞主线程)
介绍 LRU算法
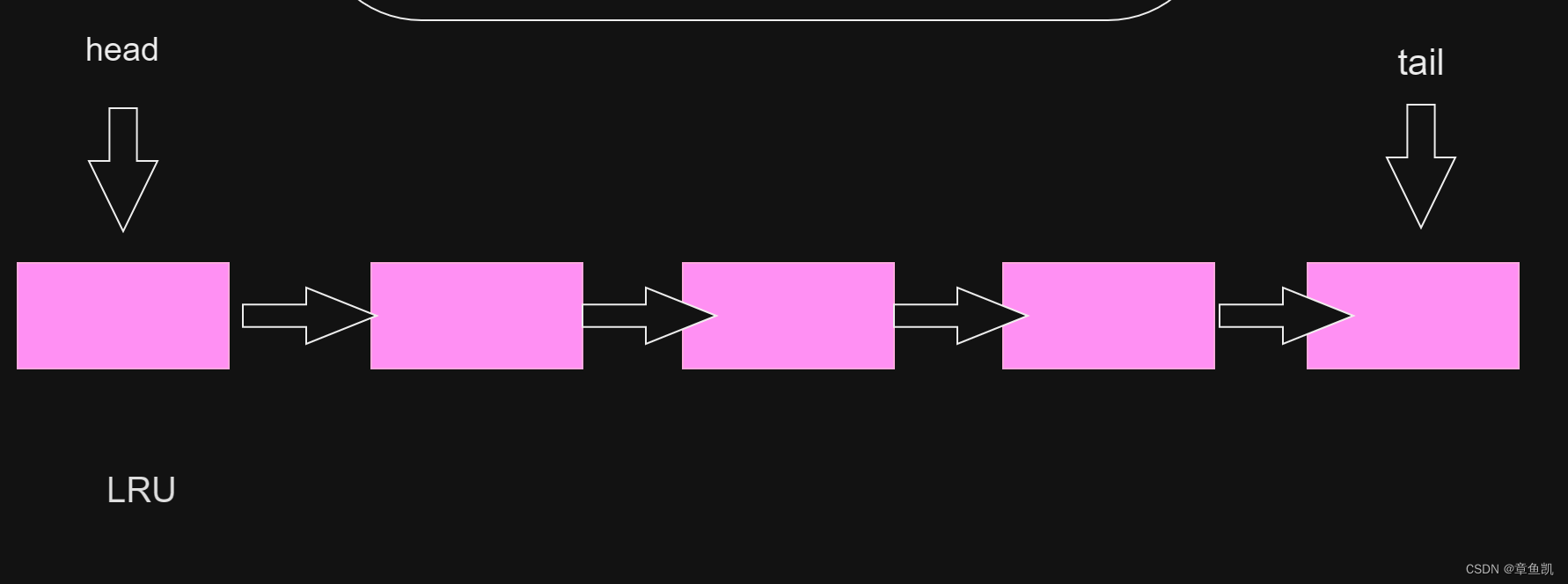
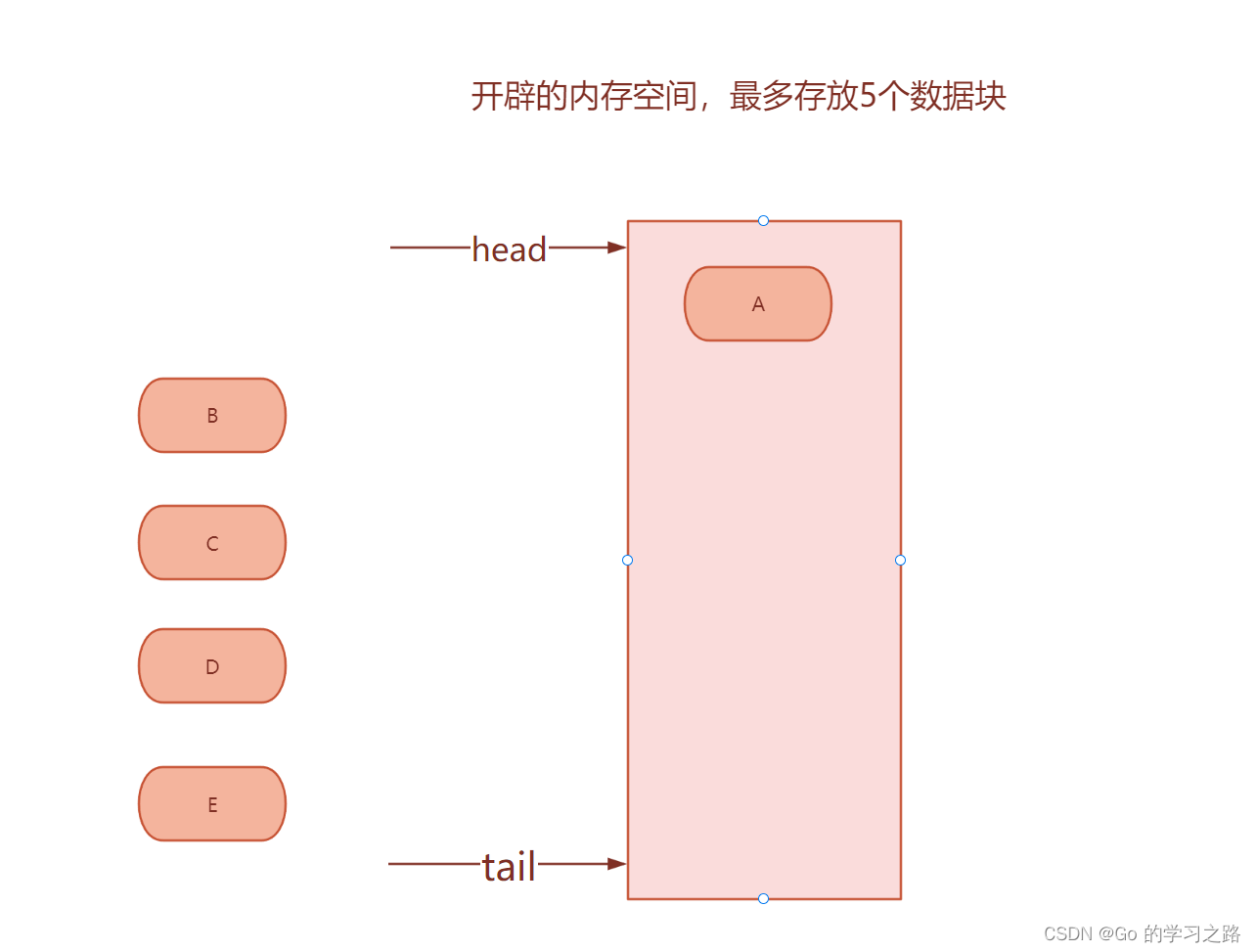
总的来说LRU 就是一个链表, 当我们使用一个节点 或者 插入一个新节点 , 就使用头插
这样因为链表是有限长度,末尾就会被淘汰,这样实现内存淘汰机制
传统的LRU有什么问题?
预读失效导致缓存命中率下降
什么是预读机制呢?
操作系统出于空间局部性原理(靠近当前被访问数据的数据,在未来很大概率会被访问到)
所以当我们,读取一部分内容时,它旁边的内容也会被加载到内存中,同时如果文件读取内容小,
那么预读机制也可以充分利用空间,将这一部分缺少的内存补充,为未来访问作准备
什么是预读失效
如果这些被提前加载进来的页,并没有被访问,相当于这个预读工作是白做了,这就是预读失效。
传统的 LRU 算法,就会把「预读页」放到 LRU 链表头部,而当内存空间不够的时候,淘汰掉末尾
如果这些「预读页」如果一直不会被访问到,就会出现一个很奇怪的问题,不会被访问的预读页却占用了 LRU 链表前排的位置,而末尾淘汰的页,可能是热点数据,这样就大大降低了缓存命中率
也就是俗话说的占着茅坑不拉屎
缓存污染导致缓存命中率下降;
当我们大量访问 只访问一次的数据时, 链表中大量的热点数据被淘汰 ,
这样当我们再次访问热点数据时 又需要向磁盘IO导致访问速度变慢
如何改进LRU算法
解决预读失效
我们不能因为害怕预读失效,而将预读机制去掉,大部分情况下,空间局部性原理还是成立的。
要避免预读失效带来影响,最好就是让预读页停留在内存里的时间要尽可能的短,
让真正被访问的页才移动到 LRU 链表的头部,
从而保证真正被读取的热数据留在内存里的时间尽可能长。
下面就是MySQL的处理
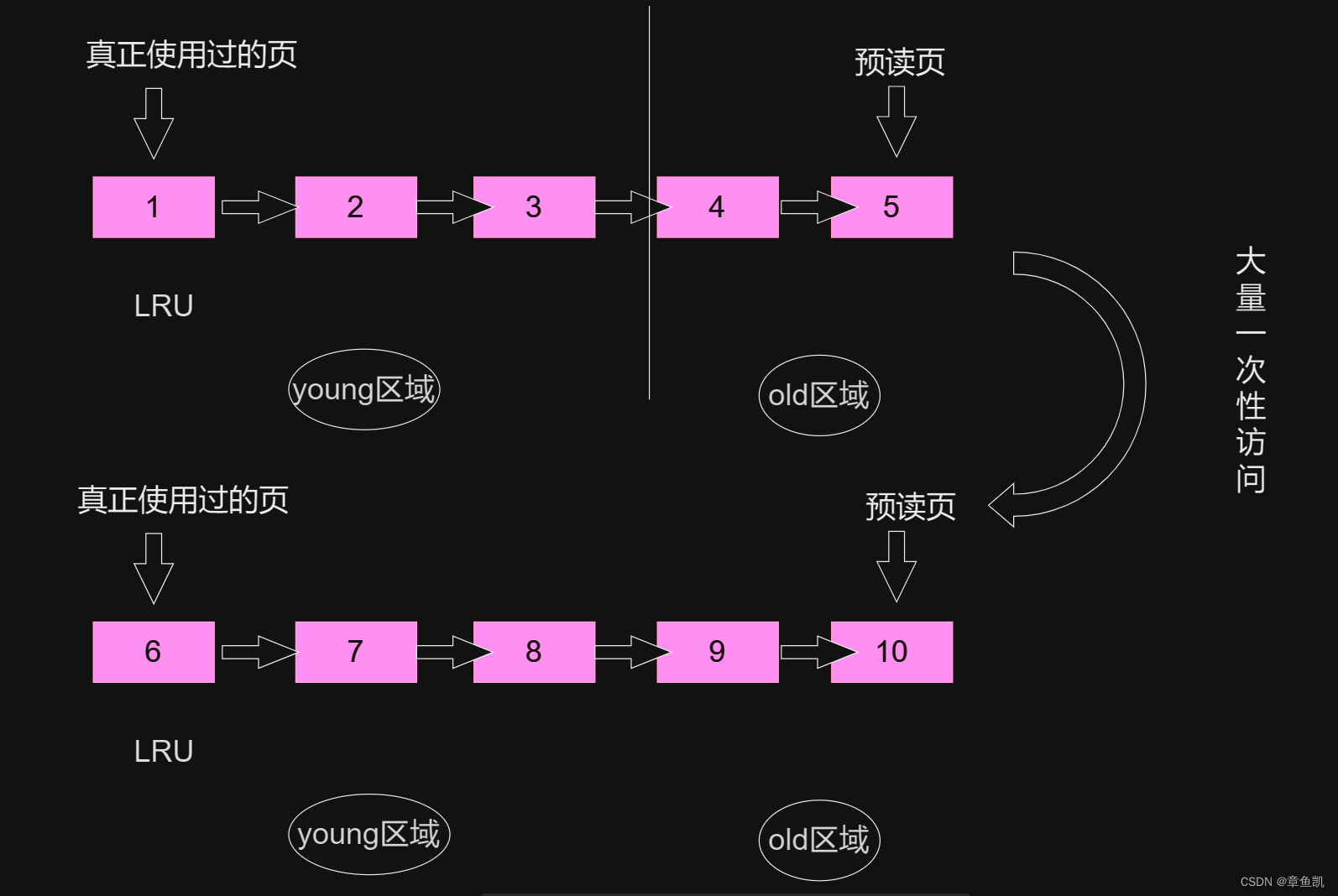
把链表分为 young区域和old区域
使用过的页插入young区域 而预读页插入 old 区域

解决缓存污染
传统的 LRU 算法只要数据被访问一次,就将数据加入 young 区域,
这种 LRU 算法进入活跃 LRU 链表的门槛太低了!因为门槛太低,导致在发生缓存污染的时候,
很容易将原本在活跃 LRU 链表里的热点数据淘汰了。
只要我们提高进入到活跃 LRU 链表(或者 young 区域)的门槛,
就能有效地保证活跃 LRU 链表(或者 young 区域)里的热点数据不会被轻易替换掉。
那么如何提高门槛呢?
在内存页被访问第二次的时候,并不会马上将该页从 old 区域升级到 young 区域,
因为还要进行停留在 old 区域的时间判断:
如果第二次的访问时间与第一次访问的时间在 1 秒内(默认值),
那么该页就不会被从 old 区域升级到 young 区域;(短时间内频繁访问)
如果第二次的访问时间与第一次访问的时间超过 1 秒,
那么该页就会从 old 区域升级到 young 区域;
提高了进入活跃 LRU 链表(或者 young 区域)的门槛后,就很好了避免缓存污染带来的影响。
在批量读取数据时候,如果这些大量数据只会被访问一次,那么它们就不会进入到 young 区域,也就不会把热点数据淘汰,只会待在 old 区域 中,后续很快也会被淘汰。