1,语法分析的若干问题
1.1 语法分析器的作用
编译器前端的重要组成部分:
(1) 根据词法分析器提供的记号流,为语法正确的输入构造分析树(或语法树)。
(2) 检查输入中的语法(可能包括词法)错误,并调用出错处理器进行适当处理。
语法分析器:
1、通用的语法分析方法
Cocke-Younger-Kasami算法和Earley算法
2、自上而下
对任何输入串,试图用一切可能的办法,从文法开始符号(根结点)出发,自上而下地为输入串建立一棵语法树;或者说为输入串寻找一个最左推导。
3、自下而上
自上而下的一般方法: 消除左递归 提取左因子 递归下降分析 预测分析器

1.2 语法错误的处理原则
1.2.1.源程序中可能出现的错误
语法错误
词法错误:非法字符或关键字、标识符拼写错误等
语法错误:语法结构出错,如少分号、{/}不配对等
语义错误
静态语义错误涉及的是编译时可检查出来的错误,如类型不一致、参数不匹配等;
动态语义错误一般是指程序运行时的逻辑错误,如无穷递归、变量为零时作除数等。
大多数错误的诊断和恢复集中在语法分析阶段,一个原因是大多数错误是语法错误,另一个原因是语法分析方法的准确性,它们能以非常有效的方法诊断语法错误。在编译的时候,想要准确地诊断语义或逻辑错误有时是很困难的。
1.2.2.语法错误处理的目标
① 清楚而准确地报告错误的出现,地点正确、不漏报、不错报也不多报;
② 迅速地从每个错误中恢复过来,以便分析继续进行;
③ 对语法正确源程序的分析速度不应降低太多。
1.2.3.语法错误的基本恢复策略
希望编译器的语法分析方式不是遇到一个语法错误就停止,就需要采取某种恢复策略,使得分析在遇到错误时还能够继续进行。
紧急方式恢复:这是最简单的方法,适用于大多数分析方法。
短语级恢复:建立在产生式(CFG)的基础上,以短语为基本分析单元,同时也便于进行语法制导翻译,恢复得比紧急方式要精确,因此被认为是一种较为理想的恢复方式。
出错产生式
全局纠正
例题:
下述两条是有语法错误的语句,其中第一条赋值句结束时忘记加分号:x = a + b y = c + d;
紧急方式: x = a + b + d; -- 丢弃b之后的若干记号,直到遇到同步记号+
短语级恢复:x = a + b; -- 加入分号,使之成为一个赋值句
2,上下文无关文法(CFG)
2.1 CFG的定义与表示
2.1.1 定义
定义3.1 上下文无关文法是一个四元组G =(N,T,P,S):
① N是非终结符的有限集合(Nonterminals);
② T是终结符的有限集合(Terminals),且N∩T=Φ;
③P是产生式的有限集合(Productions),每个产生式形如: A→α,其中A∈N,被称为产生式的左部,α∈(N∪T)*,被称为产生式的右部,若α=ε,则称A→ε为空产生式(也可以记为A →);
④ S是非终结符,被称为文法的开始符号(Start symbol)。
2.2.2 例题:
定义简单算术表达式的上下文无关文法G3.1=(N,T,P,S)如下所示。
N={E} T={+,*,(,),–,id} S=E
P:
E → E + E (1)
E → E * E (2)
E → (E) (3)
E → –E (4)
E → id (5)
2.2.3 表示
1.由产生式集表示CFG
文法可以由其产生式集P代替,而不写四元组。CFG的产生式表示也被称为巴克斯范式(BNF),值得注意的是,规范的BNF中,“→”用“::=”表示。
2.产生式的一般读法:
一般情况下,可以将产生式中的记号“→”读作“定义为”或者“可导出”。
3.终结符与非终结符书写上的区分
本教材默认采用区分大小写的方法来区分终结符与非终结符,若不作特殊说明,一般用大写英文字母A、B、C表示非终结符,小写英文字母a、b、c表示终结符,小写希腊字母α、β、δ表示任意的文法符号序列,即大小写混合的英文字母串。
4.产生式的缩写形式
2.2.2的例题 G3.1可以重写为如下形式:E → E + E | E * E | (E) | –E | id
2.2 CFG产生语言的基本方法 —— 推导
2.2.1 推导定义以及性质
通过推导可以产生CFG所描述的语言。
推导就是从文法的开始符号S开始,反复使用产生式,将产生式左部的非终结符替换为右部的文法符号序列,直到得到一个终结符序列

2.2.2 例题:
文法G(E):
E → E + E (1)
E→ E * E (2)
E → (E) (3)
E → –E (4)
E → id (5)
根据文法G使用最左推导得出终结符序列 ”–(id+id)” 。
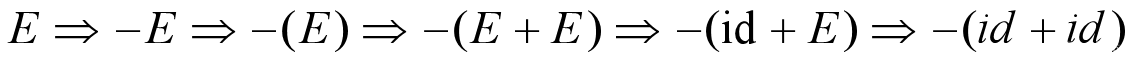
2.2.3 上下文无关语言(CFL),最左推导
定义3.3
由CFG G所产生的语言L(G)被定义为:
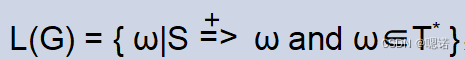
L(G)称为上下文无关语言(CFL),ω称为句子。若S
α,α∈(N∪T)*,则称α为G的一个句型。
定义3.4
在推导过程中,若每次直接推导均替换句型中最左边的非终结符,则称为最左推导,由最左推导产生的句型被称为左句型。
类似地,可以定义最右推导与右句型,最右推导也被称为规范推导。
2.3 推导、分析树与语法树
定义3.5 对CFG G的句型,分析树被定义为具有下述性质的一棵树。
① 根由开始符号所标记;
② 每个叶子由一个终结符、非终结符或ε标记;
③ 每个内部结点由一个非终结符标记;
④ 若A→X1X2...Xn是一个产生式,则X1,X2,...,Xn是标记为A的内部结点从左到右所有孩子的标记。若A→ε,则标记为A的结点可以仅有一个标记为ε的孩子。
分析树与文法和语言存在下述关系:
① 每一直接推导(或者每个产生式),对应一棵仅有父子关系的子树,即产生式左部非终结符“长出”右部的孩子;
② 分析树的叶子从左到右,构成G的一个句型。若叶子仅由终结符标记,则构成一个句子。
分析树与推导的关系:
① 分析树是推导的图形表示,但不能显示推导的顺序;
② 每棵分析树都可以对应惟一的最左推导或最右推导;但每个句子(产生式)不一定只有一棵分析树,也就是说每个句子不一定只有一个最左推导或者最右推导。 例:句子id + id * id
例题:
用文法G采用最左推导产生句子id+id*id.
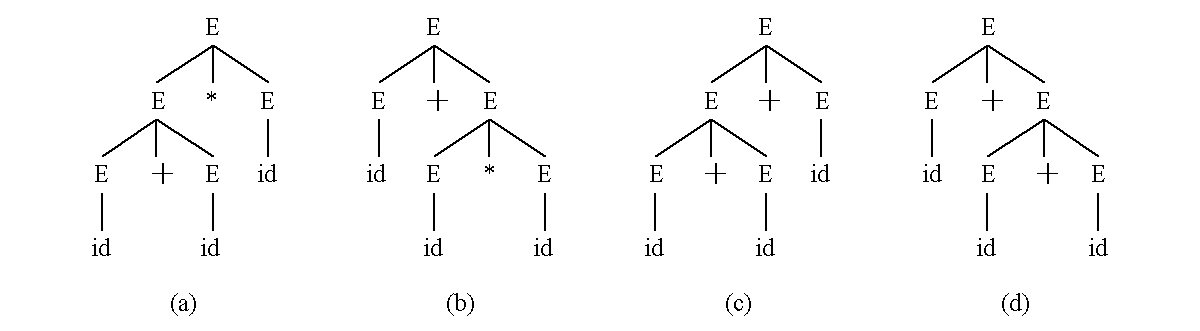
一个句子两棵分析树 (a) 先进行+运算;(b) 先进行*运算;(c) +左结合;(d) +右结合

2.4 二义性与二义性的消除
2.4.1 二义性(Ambiguity)
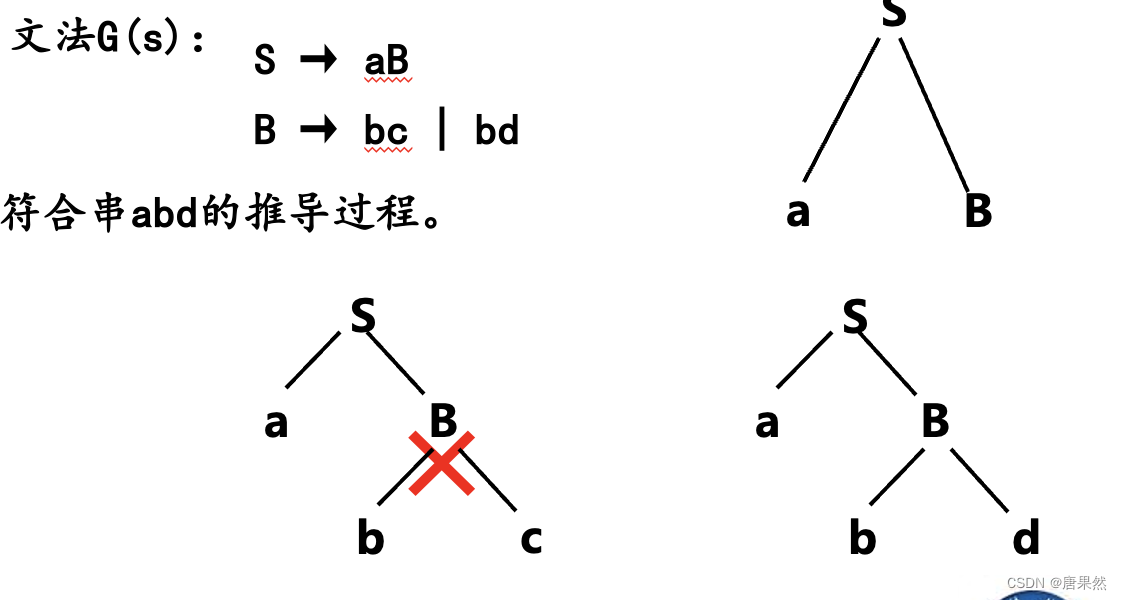
定义3.7 若文法G对同一个句子产生不止一棵分析树,则称G是二义的。
① 一个句型有多于一棵分析树,仅与文法和句型有关,与采用的推导方法无关;
② 造成二义性的原因,是文法中缺少对文法符号优先级和结合性的规定。
在任何一个程序设计语言中,如果出现了二义性,则表示同一段程序在确定的、相同的环境下反复执行,会得到不同的结果,而这种情况在程序设计中是不允许的。也就是说,任何一个程序设计语言不应该有二义性。
2.4.2 为文法符号规定优先级和结合性
改写文法可以解决二义性问题,但不是唯一的解决方法。比较上述讨论过的二义文法和非二义文法,发现二义文法至少有两个优点:
① 比非二义文法容易理解;
② 分析效率高(分析树低,直接推导步骤少)。
3,语言与文法简介
到目前为止,我们在两个层面上讨论了程序设计语言的结构:从词法分析的层面上看,语言是由字母组成的记号的集合;从语法分析的层面上看,语言是由记号组成的句子的集合。记号可以用正规式描述,句子可以用CFG描述。
程序设计语言的结构均可以用文法来描述。文法无论对程序设计语言的设计还是对编译器的编写,至少在以下三个方面起着重要作用:
① 文法给出了精确的、易于理解的语言结构的说明;
② 以文法为基础的语言,便于加入新的或修改、删除旧的语言结构;
③ 有些类别的文法,可以自动生成高效的分析器。
3.1.为什么用正规式而不用CFG描述程序设计语言的词法
根据推论3.1,CFG既描述程序设计语言的语法又描述词法,而基于下述几个原因,往往采用正规式而不是CFG描述词法:
① 词法规则简单,用正规式描述已足够;
② 正规式的表示比CFG更直观、简洁、易于理解;
③ 有限自动机的构造比下推自动机简单,且分析效率高;
④ 区分词法和语法,为编译器前端的模块划分提供方便。
3.2 正规式和CFG的适用条件
一般情况下,正规式适合描述线性结构,如标识符、关键字、注释等。而CFG适合描述具有嵌套(层次)性质的非线性结构,如不同结构的句子if-then-else、begin-end等。
3.3 形式语言与自动机简介
乔姆斯基(Chomsky)把文法分为四种类型: 0型、1型、2型和3型。文法之间的差异在于对产生式施加不同的限制。
定义3.8 若文法G=(N,T,P,S)的每个产生式α→β中,均有α∈(N∪T)*,且至少含有一个非终结符,β∈(N∪T)*,则称G为0型文法。
对0型文法施加以下第i条限制,即可得到i型文法。
1.G的任何产生式α→β(S→ε除外) 均满足|α|≤|β| (|x|表示x中文法符号的个数);
2.G的任何产生式形如A→β,其中A∈N,β∈(N∪T)*;
3.G的任何产生式形如A→a 或者A→aB(或者A→Ba),其中A,B∈N,a∈T。
0型文法也被称为短语文法,任何0型语言都是递归可枚举的,反之,递归可枚举集也必定是一个0型语言。
1型文法就是上下文有关文法,这种文法意味着对非终结符的替换必须考虑上下文,并且一般不允许换成ε串。例如,若αAβ→αγβ是1型文法的产生式,α和β不全为空,则非终结符A只有在左边是α,右边是β这样的上下文中才可能替换成γ。
2型文法就是上下文无关文法,非终结符的替换无需考虑上下文。
3型文法等价于正规式,因而也被称为正规文法或线性文法。
四种类型的文法和它们所描述的语言,以及识别对应语言的自动机分别列举在表中。

4, 自上而下分析的一般方法
4.1 基本思想
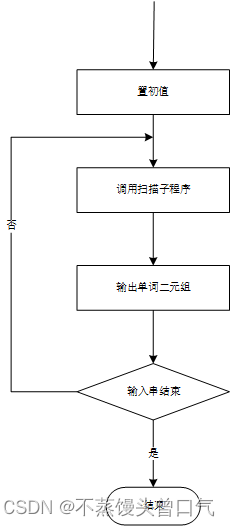
自上而下分析的基本思想是:对于任何一个输入序列,从文法的开始符号开始,进行最左推导,直到得到一个合法句子或者发现一个非法结构。在推导的过程中试图用一切可能的方法,自上而下、从左到右为输入序列建立分析树。整个分析是一种试探的过程,是反复使用不同产生式谋求与输入序列匹配的过程。
4.2 例题
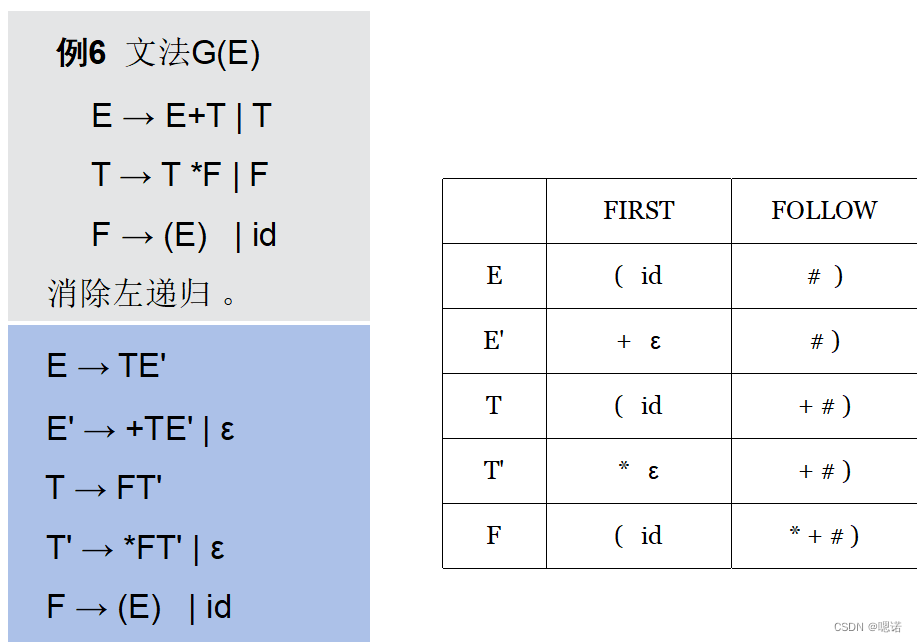
已知如下文法G(S),给出输入序列ω=cad,自上而下试探建立分析树的过程。
G(S): S → cAd A → ab | a

(1) 若存在形如A → αβ1|αβ2的产生式,即A产生式中有多于一个候选项的前缀相同(称为公共左因子,或简称左因子),则可能会造成虚假匹配,使得在分析过程中可能需要进行大量回溯,从而造成分析效率低、语义动作难以恢复以及出错位置的报告不确切等。
(2) 若存在形如A → Aα的产生式,则分析过程中一旦采用了该产生式去替换,就会陷入死循环而使分析无法进行下去。产生式的这种形式被称为左递归。
为了避免上述弱点,需要对文法进行重写。消除左递归,以避免陷入死循环;提取左因子,以避免回溯。
4.3 消除左递归
分类:直接左递归 间接左递归

规则1 直接左递归的产生式A→Aα|β (β不以A开头), A→βA' A'→αA'|ε
规则2 直接左递归的产生式 A→ Aα1 | Aα2 | ... | Aαm |β1 |β2 | ...|βn(所有βi均不以A直接开头或间接开头), A→β1A'|β2A'|...|βnA' A'→α1A'|α2A'|...αmA'|ε


并不是所有的文法都能消除左递归!!!
4.4 提取左因子
对于有左因子的文法,推导过程中会出现无法确定用A产生式的哪个候选项替换A的情况,这时,可以重写A产生式来推迟这种决定,直到看见足够的输入,能正确决定所需选择为止。这一过程类似于有限自动机的确定化,被称为提取左因子。
算法3.3 提取文法的左因子
输入 : 文法G
输出: 等价的无左因子文法G'
方法 :为每个产生式A,找出其候选项中最长公共前缀α,重排A产生式如下,其中γ是不以α为前缀的其他候选项。
A→ αβ1|αβ2| ...|αβn|γ
并用下述产生式替代之。
A→ αA'|γ
A'→ β1|β2| ...|βn
重复此过程,直到所有A产生式的候选项中均不再有公共前缀。

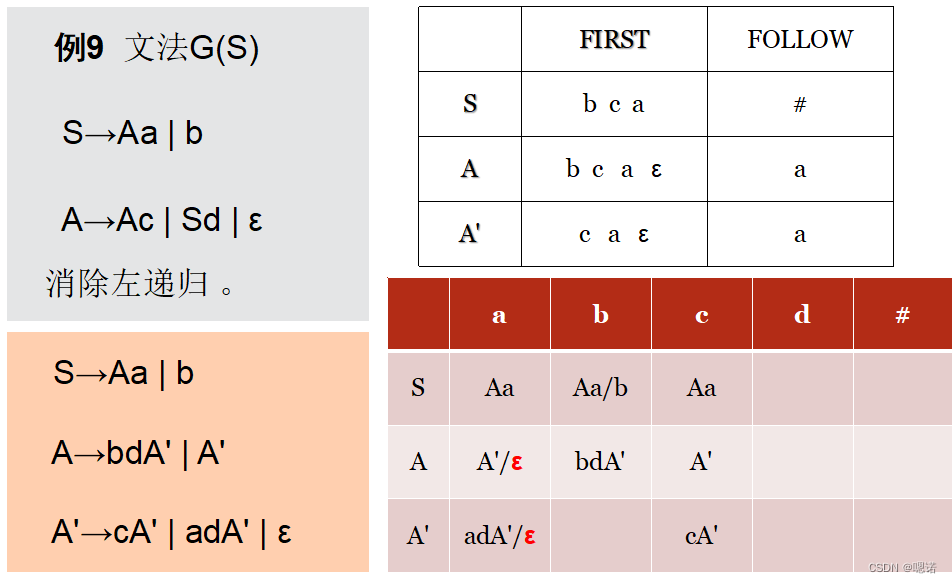
练习:
1、文法G(A):A→aABj | a B→Bb | d
2、文法G(M):M→MaH | H H→b(M) | (M) | b
3、文法G(S):S→AdD | ε A→aAd | ε D→DdA | b | ε
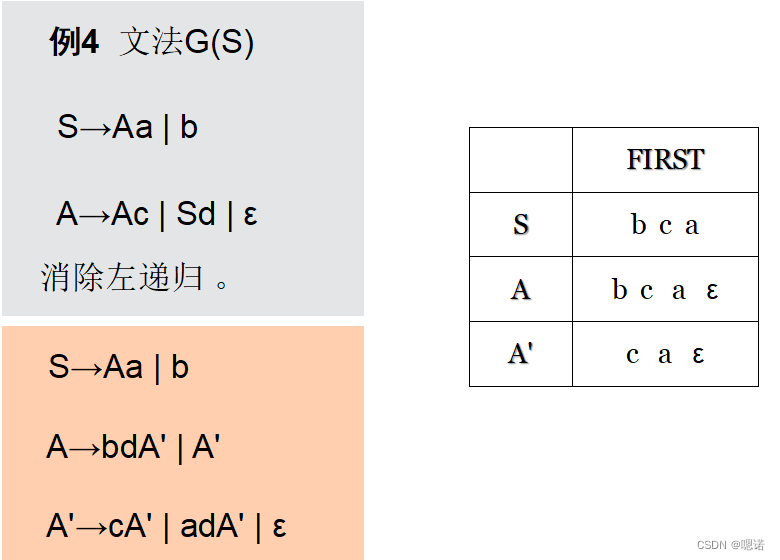
5,FIRST集和FOLLOW集

5.1 FIRST集
算法3.5 计算X的FIRST集合
输入 文法符号X
输出 X的FIRST集合
方法 应用下述规则:
① 若X是终结符,则FIRST(X)={X};
② 若X 是非终结符且有X→ε,则加入ε到FIRST(X);
③ 若X 是非终结符且有X→Y1Y2...Yk,并令Y0=ε,Yk+1=ε,则对所有j(0≤j≤k),若a∈FIRST(Yj+1)且ε∈FIRST(Yj),加入a到FIRST(X)。



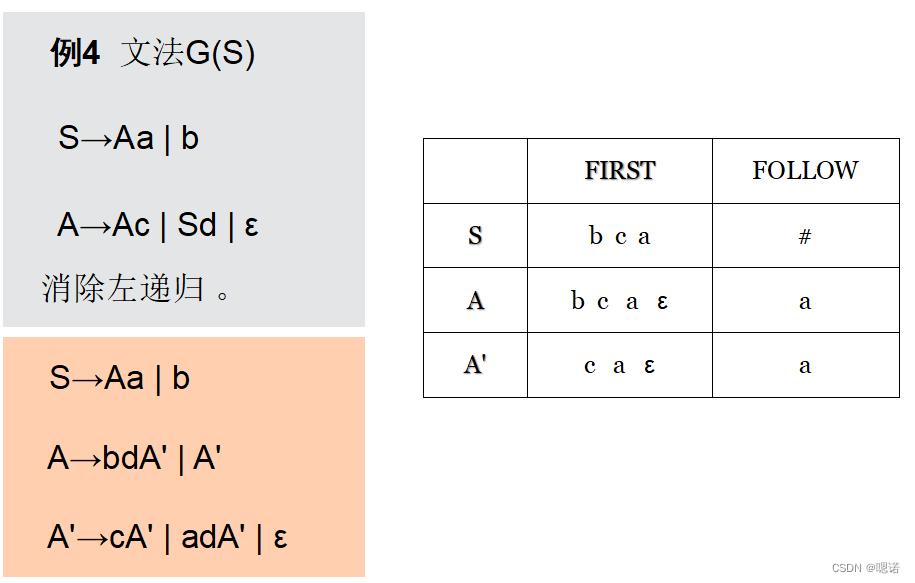
5.2 FOLLOW
算法3.6 计算所有非终结符的FOLLOW集合
输入 文法G
输出 G中所有非终结符的FOLLOW集合
方法 应用下述规则:
① 加入#到FOLLOW(S),其中,S是开始符号,#是输入结束标记;
② 若有产生式A→αBβ,则除ε外,FIRST(β)的全体加入到FOLLOW(B);
③ 若有产生式A→αB或A→αBβ而ε∈FIRST(β),则FOLLOW(A)的全体加入FOLLOW(B)。
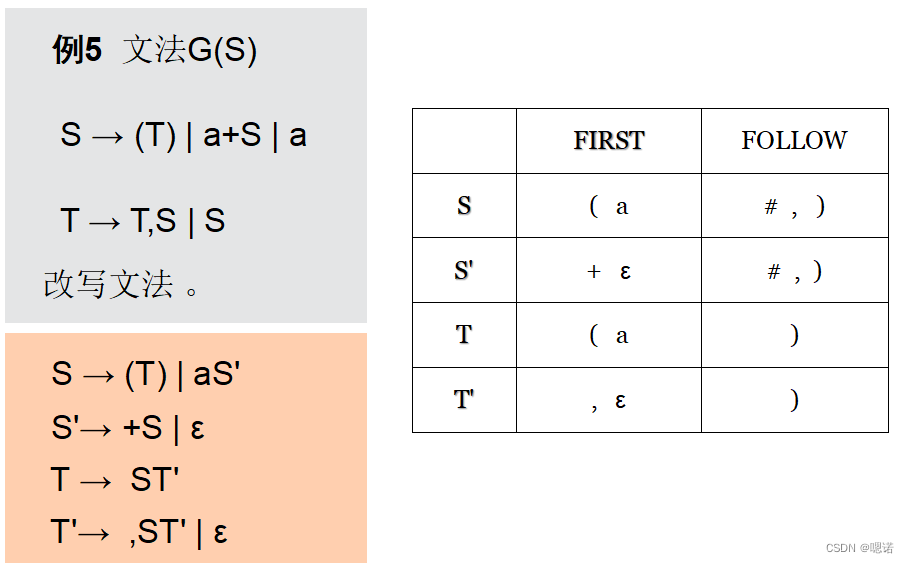
6,预测分析表
算法3.7 构造预测分析表
输入 文法G
输出 分析表M
方法 应用下述规则:
① 对文法的每个产生式A→α,执行②和③;
② 对FIRST(α)的每个终结符a,加入α到M[A,a];
③ 若ε在FIRST(α)中,则对FOLLOW(A)的每个终结符b(包括#),加入α到M[A,b];
④ M中其他没有定义的条目均是error。
预测分析表是一个二维数组M[A, a] 所有的非终结符构成分析表的行下标; 所有的终结符构成分析表的列下标,其中包括特殊的结束标志#。 M[A, a]中的内容表示当前栈顶为非终结符A且当前输入为终结符a时,分析器要进行的动作。


3.4.5.3 LL(1)文法
定义3.12 一个文法G被称为是LL(1)文法,当且仅当为它构造的预测分析表中不含多重定义的条目。由此分析表所组成的分析器被称为LL(1)分析器,它所分析的语言被称为LL(1)语言。第一个L表示从左到右扫描输入序列,第二个L表示产生最左推导,1表示在确定分析器的每一步动作时向前看一个终结符。
推论3.2 一个文法G是LL(1)的,当且仅当G的任何两个产生式A→α|β,满足下面条件: ① 对任何终结符a,α和β不能同时推导出以a开始的文法符号序列;
② α和β最多有一个可以推导出ε;
③ 若β ε,则α不能推导出以在FOLLOW(A)中的终结符开始的任何文法符号序列。
推论3.2实际上等价于当且仅当G的任何两个产生式A→α|β满足上述三个条件时,为文法G构造的预测分析表中不含多重定义的条目。反之,若不满足三个条件之一,则分析表中有多重定义条目。 若条件①不满足,即存在终结符a,α和β同时推导出以a开始的文法符号序列,则根据算法3.7规则②,M[A,a]中就会有多重定义条目A→α和A→β;
若条件②不满足,即α和β均可推出ε,则根据算法3.7规则③,任何属于FOLLOW(A)的终结符b(包括#),M[A,b]中就会有多重定义条目A→α和A→β; 若条件③不满足,即存在终结符b,它既在FOLLOW(A)中,又在FIRST(α)中,则 算法3.7规则②把条目A→α加入到M[A,b]中,而规则③又把条目A→β加入到M[A,b]中。
LL(1)文法的弱点: (1) 文法比较难写。因为按照人们习惯写出的文法,往往含有左递归和左因子。虽然有成熟的算法可以消除左递归和提取左因子,但改写之后的文法很难读也很难使用。同时对比分析树可以看出,改写后文法构造的分析树不直观且推导步骤增加。 (2) LL(1)文法适应范围有限,对于有些语言,往往写不出它的LL(1)文法。
![<span style='color:red;'>编译</span><span style='color:red;'>原理</span>2.3习题 <span style='color:red;'>语法</span>制导<span style='color:red;'>分析</span>[C++]](https://img-blog.csdnimg.cn/direct/e02e522b57424727ab519469d37d2e83.png)