语法制导翻译
编译器在做语法分析过程中除了回答程序语法是否合法外,还必须完成后续工作
- 可能的工作包括(但是不限于)
- 类型检查
- 目标代码生成
- 中间代码生成
- …等等
- 可能的工作包括(但是不限于)
这些后续的工作一般可通过语法制导的翻译完成
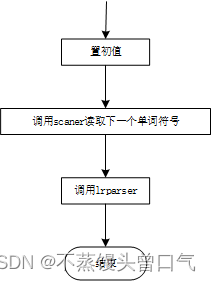
LR分析中的语法制导翻译
在之前的加法中实现语法制导翻译
%{
#include <stdio.h>
#include <stdlib.h>
int yylex();
void yyerror();
%}
%left '+'
%%
lines: line
| line lines
;
line: exp '\n' {
printf("value=%d\n", $1);}
;
exp: n {
$$=$1;}
| exp '+' exp {
$$=$1+$3;}
;
n: '1' {
$$=1;}
| '2' {
$$=2;}
| '3' {
$$=3;}
| '4' {
$$=4;}
| '5' {
$$=5;}
| '6' {
$$=6;}
| '7' | '8' | '9' | '0';
%%
int yylex()
{
return getchar();
}
void yyerror(char *s)
{
fprintf(stderr, "%s\n", s);
return;
}
int main(int argc, char **argv)
{
yyparse();
return 0;
}
基本思想
- 给每条产生式规则附加一个语义动作
- 一个代码片段
- 语义动作在产生式“归约”时执行
- 即由右部的值计算左部的值
- 以自底向上的技术为例进行讨论
- 自顶向下的技术与此类似
抽象语法树
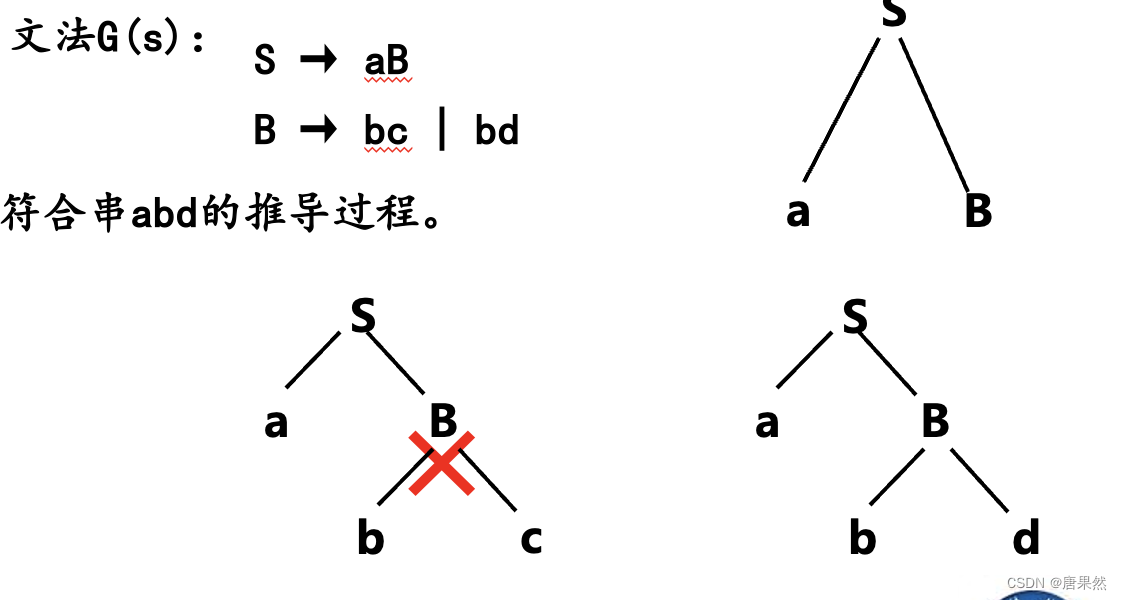
将分析树的浓缩过程生成的树是抽象语法树
分析树
- 分析树编码了句子的推导过程
- 但是包含很多不必要的信息
- 注意:这些节点要占用额外的存储空间
- 本质上,这里的那些信息是重要的?
- 对于表达式而言,编译只需要知道运算符和运算数
- 优先级、结合性等已经在语法分析部分处理掉了
- 对于语句、函数等语言其他构造而言也一样
- 例如:编译器不关系赋值符号是=还是:=或者其他符号
- 对于表达式而言,编译只需要知道运算符和运算数
具体语法和抽象语法
- 具体语法是语法分析器使用的语法
- 必须适合语法分析,如各种分隔符、消除左递归、提取左公因子等
- 抽象语法是用来表达语法结构的内部表示
- 现代编译器一般都采用抽象语法作为前端(词法语法分析)和后端(代码生成)的接口
抽象语法树的数据结构
- 在编译器中,为了定义抽象语法树,需要使用实现语言来定义一组数据结构
- 和实现语言密切相关
- 早期的编译器有的不采用抽象语法树数据结构
- 直接在语法制导翻译中生成代码
- 但现代的编译器一般采用抽象语法树作为语法分析器的输出
- 更好的系统支持
- 简化编译器的设计
抽象语法树的自动生成
在语法动作当中,加入生成语法树的diam
- 代码片段一般是语法树的构造函数
在产生式归约的时候,会自底向上构造整棵树
- 从叶子到根
抽象语法树是编译器前端和后端的接口
- 程序一旦被转换为抽象语法树,则源代码即被丢弃
- 后续的阶段只处理抽象语法树
所以抽象语法树必须编码足够多的源代码信息
- 例如:它必须编码每个语法结构在原代码中的位置(文件,行号、列号等)
- 这样,后续的检查阶段才能精确的报错
- 或者获取程序的执行刨面
抽象语法书必须仔细设计

![<span style='color:red;'>编译</span><span style='color:red;'>原理</span>2.3习题 <span style='color:red;'>语法</span><span style='color:red;'>制导</span>分析[C++]](https://img-blog.csdnimg.cn/direct/e02e522b57424727ab519469d37d2e83.png)

























![光条中心线提取-Steger算法 [OpenCV]](https://img-blog.csdnimg.cn/20190322170216582.png)