坚持7天,短期内快速完成C++后端面试突击。每天10题,弥补后端八股知识缺漏,熟练掌握后端的高频考点,后端面试更有把握。
1. Redis 的五种数据结构 + 使用场景
String(字符串):
- 使用场景:存储单个值,例如缓存数据、计数器、分布式锁等。
List(列表):
- 使用场景:实现队列、栈、消息队列等,记录一系列有序的值,支持从两端插入和删除元素。
Hash(哈希):
- 使用场景:存储对象的字段和值,适用于存储、读取和更新对象属性,例如用户信息、配置信息等。
Set(集合):
- 使用场景:存储唯一值的无序集合,支持集合间的交集、并集、差集等操作,例如好友列表、标签系统等。
Sorted Set(有序集合):
- 使用场景:与Set相似,但每个元素关联了一个分数(score),根据分数进行排序,适用于排行榜、按权重筛选数据等场景。
2. Redis 内存淘汰策略
Redis 内存淘汰策略用于在内存不足时选择哪些键值对(Key-Value pairs)应该被删除以释放内存空间。
Noeviction(无淘汰):
当内存不足以容纳新写入的数据时,新写入操作会报错并返回一个内存错误(OOM)。Allkeys-lru(LRU算法):
Least Recently Used(LRU)算法会删除最近最少使用的键,以释放内存空间。Redis会检查所有键的最近访问时间,并删除最近最少使用的键值对。Allkeys-random(随机淘汰):
在内存不足时,Redis会随机选择键值对进行删除,这种策略是简单且不可预测的。Volatile-lru(带过期时间的LRU算法):
类似于Allkeys-lru,但只会在设置了过期时间的键中选择淘汰。Volatile-ttl(带过期时间的TTL算法):
类似于Allkeys-lru,但只会在设置了过期时间的键中选择淘汰,并优先选择剩余时间最短的键。Volatile-random(带过期时间的随机淘汰):
类似于Allkeys-random,但只会在设置了过期时间的键中选择淘汰。
3. MySQL 和 Redis 数据一致性问题
数据同步延迟:
当应用同时使用MySQL和Redis时,如果更新数据到MySQL后立即查询Redis,由于数据同步的延迟,可能会导致Redis中的数据与MySQL中的数据不一致。- 解决方法:
- 引入缓存失效机制:在数据更新时,及时使Redis中对应的缓存失效,确保下一次查询会重新从MySQL获取最新数据。
- 使用主从复制:在MySQL中设置主从复制,将主库的更新同步到从库,应用读取数据时可以从从库获取,减少主库的压力。
- 解决方法:
数据丢失:
当写入Redis成功但MySQL写入失败时,可能会导致Redis中的数据和MySQL中的数据不一致。- 解决方法:
- 使用事务:在应用层面确保Redis和MySQL的写入操作在同一个事务中,如果其中一个写入失败,则回滚另一个写入。
- 引入消息队列:将写入Redis和MySQL的操作封装成消息,通过消息队列来确保消息的可靠传递,以避免数据丢失问题。
- 解决方法:
并发更新导致的数据不一致:
当多个客户端同时更新相同的数据时,可能会导致数据不一致的情况。- 解决方法:
- 使用分布式锁:在更新操作之前获取分布式锁,确保同时只有一个客户端可以进行更新操作,从而避免并发更新导致的数据不一致问题。
- 使用乐观锁或悲观锁:在MySQL中可以使用乐观锁(如通过版本号或时间戳)或悲观锁(如使用SELECT … FOR UPDATE语句)来确保并发更新的数据一致性。
- 解决方法:
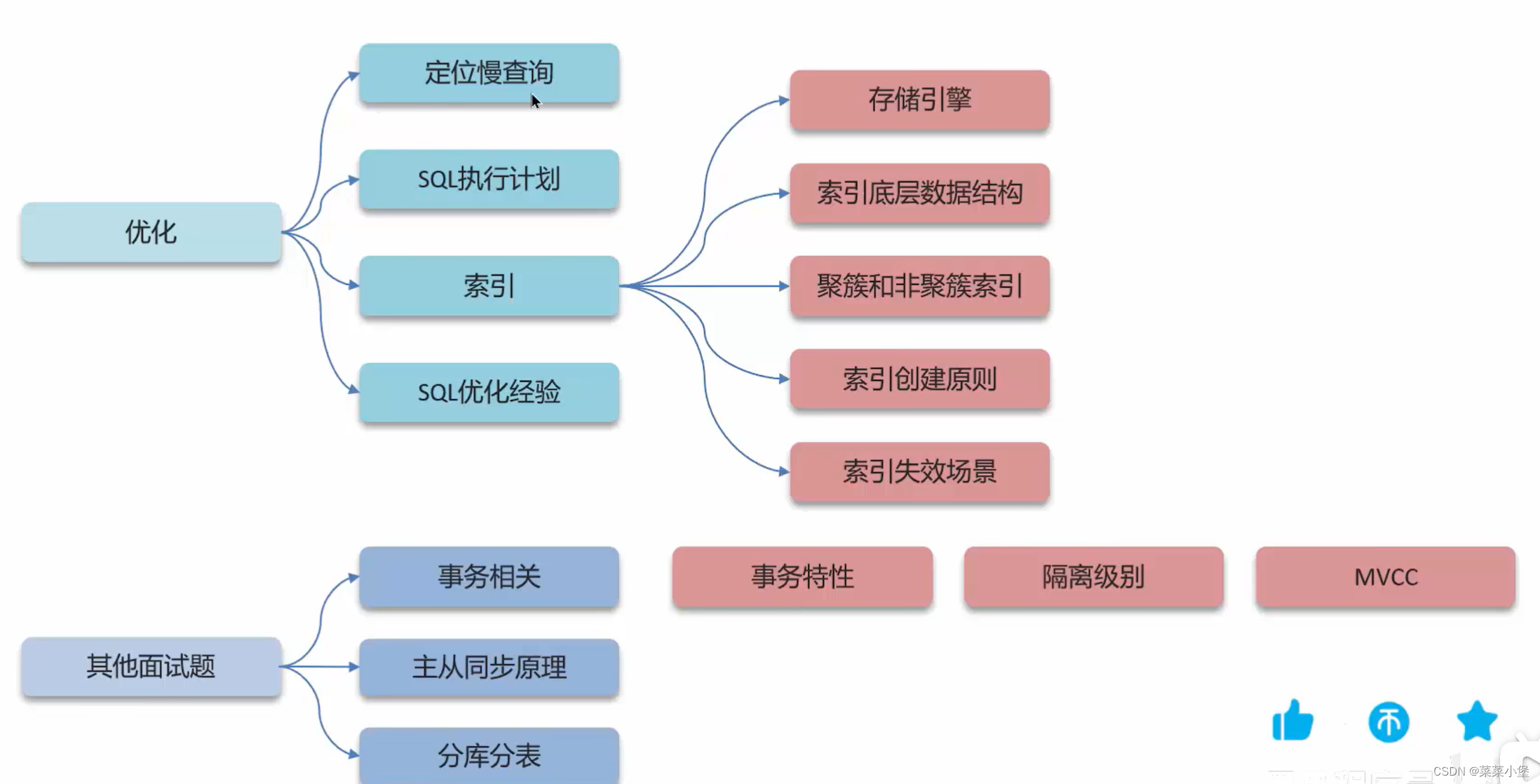
4.Mysql 里面为什么用 B+ 树?
高效的范围查询:
B+树对范围查询的支持非常高效。在B+树中,相邻的节点彼此有序连接,这使得范围查询(例如,WHERE条件中使用了范围)可以通过遍历树中的部分节点来实现,而不必遍历整个数据集。高效的顺序访问:
B+树的叶子节点形成了一个有序的链表,这使得顺序访问非常高效。例如,当需要按照索引顺序扫描表时,B+树可以快速地按顺序访问数据。适用于磁盘存储:
B+树结构在磁盘存储上的性能非常好。由于B+树的节点大小通常可以设置得非常大,因此每个节点可以容纳更多的索引键值对,从而减少了磁盘I/O的次数。支持快速的插入和删除:
B+树的平衡性质使得在其中进行插入和删除操作时,平均情况下的性能表现非常好。虽然插入和删除操作可能需要进行节点的分裂和合并,但这些操作的代价相对较低,因为它们只会影响树的局部结构。易于实现:
B+树的结构相对简单,易于实现。这使得在数据库系统中广泛采用B+树作为索引结构,同时也便于优化和调整。
5.什么是事务
事务(Transaction)是指数据库管理系统(DBMS)执行的一组数据库操作单元,这些操作被视为单个逻辑工作单元,要么全部执行成功,要么全部失败,保证数据库的一致性和完整性。
事务具有以下四个特性(ACID):
原子性(Atomicity):事务中的所有操作要么全部执行成功,要么全部失败,不存在部分执行的情况。如果一个操作失败,整个事务将回滚到事务开始之前的状态。
一致性(Consistency):事务的执行必须保证数据库的一致性。事务在执行前后,数据库从一个一致的状态转变到另一个一致的状态。
隔离性(Isolation):事务的执行过程中,其所做的修改对其他事务是不可见的,即事务之间的操作是隔离的。这样可以防止多个事务并发执行时产生的一些问题,如脏读、不可重复读、幻读等。
持久性(Durability):一旦事务提交,其所做的修改将永久保存在数据库中,即使系统发生故障或重启,事务提交后的修改也不会丢失。
通过事务,可以保证在并发执行的情况下,数据库操作的正确性和可靠性,确保数据的完整性和一致性。在数据库系统中,事务是实现数据管理和并发控制的重要机制。
6.数据库的隔离级别,分别怎么解决可能出现的问题?
数据库的隔离级别定义了在多个事务并发执行时,事务之间的可见性和影响的程度。常见的隔离级别包括:读未提交(Read Uncommitted)、读已提交(Read Committed)、可重复读(Repeatable Read)和串行化(Serializable)。下面是这些隔离级别可能出现的问题以及解决方法:
读未提交(Read Uncommitted):
- 可能出现问题:脏读(Dirty Read):一个事务读取到了另一个事务未提交的数据。
- 解决方法:不采取特殊措施,允许脏读。
读已提交(Read Committed):
- 可能出现问题:不可重复读(Non-Repeatable Read):在一个事务内,同一个查询可能返回不同的结果。
- 解决方法:使用行级锁或快照隔离,确保每次查询读取的数据是已提交的版本。
可重复读(Repeatable Read):
- 可能出现问题:幻读(Phantom Read):一个事务在两次查询之间,另一个事务插入了新数据,导致第一个事务看到了不一致的结果。
- 解决方法:使用间隙锁或快照隔离,防止其他事务在事务执行期间插入或删除数据。
串行化(Serializable):
- 可能出现问题:并发性能低下,因为串行化级别要求所有事务按顺序执行。
- 解决方法:将事务串行化执行,确保每个事务都完全按顺序执行,以避免任何并发问题。
不同的隔离级别提供了不同的性能和数据一致性保证,选择适当的隔离级别取决于应用的需求和数据访问模式。在实际应用中,可以根据具体情况选择合适的隔离级别,并结合数据库提供的锁机制来解决可能出现的并发问题。
7.讲讲 MVCC
MVCC(Multi-Version Concurrency Control,多版本并发控制)是一种在数据库管理系统中实现事务并发的技术。MVCC允许读取和写入操作在并发执行时不互相干扰,从而提高了数据库的并发性能和可伸缩性。
在MVCC中,每个数据库行都有多个版本,每个版本都有一个时间戳或者序列号,用来表示它的创建时间或者更新顺序。当一个事务开始时,它会获得一个特定时间点或者序列号的快照视图,这个快照视图代表了数据库在事务开始时的状态。在事务执行期间,其他事务对数据库的修改不会影响到该事务的快照视图。
MVCC的核心原则包括:
可见性:一个事务只能看到它开始时数据库的状态,其他事务对数据的修改不会对它产生影响,即每个事务都在一个固定的快照视图上执行。
并发性:读写操作可以并发执行而不会互相干扰,读操作不会阻塞写操作,写操作也不会阻塞读操作,从而提高了数据库的并发性能。
数据一致性:MVCC保证事务的一致性,即使在多个并发事务执行的情况下,数据库也能保持一致的状态。
MVCC的实现通常基于两种技术:多版本数据和版本链。在多版本数据模型中,数据库中的每个数据行可以有多个版本,每个版本都有一个时间戳或者序列号来表示。在版本链模型中,每个数据行都有一个版本链,链中的每个节点都代表一个版本,链头指向最新版本,链尾指向最老版本。
MVCC提供了一种高效且灵活的并发控制机制,被广泛应用于许多流行的数据库管理系统中,例如MySQL的InnoDB引擎、PostgreSQL等。
8.既然用了 MVCC 版本查看,为什么还会出现幻读?
尽管MVCC技术提供了快照读的能力,每个事务都在一个固定的快照视图上执行,但在某些情况下,仍然可能出现幻读(Phantom Read)的现象。幻读指的是一个事务在两次查询之间,另一个事务插入了新数据,导致第一个事务看到了不一致的结果。
幻读通常发生在以下情况下:
范围查询:当一个事务执行范围查询时,例如使用了WHERE条件的SELECT语句,而另一个事务在该范围内插入了新数据,导致第一个事务在两次查询之间看到了不同的结果,即出现了幻读。
并发事务的更新或插入操作:即使一个事务采用MVCC技术,其他并发事务的更新或插入操作仍然可能导致幻读。虽然MVCC技术保证了事务的一致性视图,但是如果其他事务在执行范围内插入了新数据,那么该范围内的查询结果可能发生变化,导致了幻读。
解决幻读的方法包括:
使用串行化隔离级别:串行化隔离级别会完全禁止并发事务的执行,从而避免了幻读的发生。但是串行化级别会影响数据库的并发性能,通常只在必要时才使用。
使用锁:可以在事务执行期间对需要查询的数据行或范围进行加锁,确保其他事务不能插入新数据,从而避免了幻读的发生。但是使用锁可能会导致性能下降和死锁的风险,因此需要谨慎使用。
使用间隙锁:间隙锁可以锁定一个范围而不是单个数据行,从而防止其他事务在这个范围内插入新数据,避免了幻读的发生。
虽然MVCC技术可以减少幻读的发生,但在特定的并发环境下,仍然需要考虑其他因素并采取适当的措施来防止幻读的发生。
9.乐观锁和悲观锁
乐观锁(Optimistic Locking)和悲观锁(Pessimistic Locking)是两种处理并发访问的数据库锁定机制,它们的选择取决于应用的需求和性能特征。
悲观锁:
工作原理:悲观锁假设在事务执行期间会发生并发冲突,因此在读取或修改数据之前会先锁定数据。如果一个事务获取了悲观锁,则其他事务不能对该数据进行操作,直到锁被释放。
实现方式:在数据库层面,可以使用诸如行级锁或表级锁等机制来实现悲观锁。
适用场景:悲观锁适用于并发写入频繁、冲突概率较高的场景,例如高并发的在线交易系统、数据更新频繁的管理系统等。
乐观锁:
工作原理:乐观锁假设在事务执行期间并发冲突的概率较低,因此不主动加锁,而是在提交事务时检查数据是否被其他事务修改过。如果检测到冲突,则拒绝当前事务的提交。
实现方式:在数据层面,通常是通过在表中增加一个版本号字段或者使用时间戳来实现乐观锁。
适用场景:乐观锁适用于读取操作频繁、写入操作较少、并发冲突概率较低的场景,例如读多写少的数据报表系统、博客系统等。
比较:
并发性能:悲观锁会在事务开始时锁定数据,可能会降低并发性能,因为其他事务需要等待锁的释放。而乐观锁在大多数情况下不加锁,可以提高并发性能。
冲突处理:悲观锁在事务开始时就预防了并发冲突,而乐观锁在事务提交时才进行检查和处理冲突。
实现复杂度:悲观锁的实现相对简单,因为加锁和释放锁的过程都是数据库自动处理的;而乐观锁需要在应用层面进行冲突检测和处理,实现起来可能会更复杂一些。
在实际应用中,应根据具体的业务需求和性能特征选择合适的锁定机制。
10.乐观锁和悲观锁的使用场景
乐观锁和悲观锁适用于不同的并发场景,根据应用需求和数据访问模式的不同,可以选择合适的锁定机制:
悲观锁的使用场景:
频繁写入的场景:当并发写入频繁时,悲观锁可以有效地防止数据的并发修改,确保数据的一致性。例如,在在线交易系统中,多个用户可能同时对同一笔订单进行修改,为了避免订单数据的不一致,可以使用悲观锁来锁定订单数据。
需要强制顺序访问的场景:某些情况下,需要确保数据的顺序访问,例如对账操作,需要按照特定的顺序对数据进行处理。悲观锁可以在事务开始时锁定数据,确保只有一个事务可以访问数据,从而保证顺序访问。
数据冲突概率较高的场景:在某些场景下,由于数据之间的关联性较高或者写入操作的复杂性较高,可能会导致数据冲突的概率较高。悲观锁可以在事务开始时锁定数据,确保数据的一致性和完整性。
乐观锁的使用场景:
读多写少的场景:当读取操作远远多于写入操作时,使用乐观锁可以减少锁的竞争,提高并发性能。例如,对于博客系统或者新闻网站等读多写少的场景,可以使用乐观锁来处理并发访问。
无需强制顺序访问的场景:某些场景下,不需要强制顺序访问,只需要保证数据的一致性即可。在这种情况下,使用乐观锁可以减少对数据的加锁操作,提高系统的并发性能。
冲突概率较低的场景:在某些场景下,并发冲突的概率较低,例如对于独立的用户操作或者对不相关数据的操作,可以使用乐观锁来处理并发访问。
总的来说,悲观锁适用于对并发冲突较为敏感的场景,需要在事务开始时就锁定数据;而乐观锁适用于读多写少、并发冲突较少的场景,可以在事务提交时检测并处理冲突。在实际应用中,应根据具体的业务需求和性能特征选择合适的锁定机制。






























![[408计算机组成原理] 第三章 存储系统](https://img-blog.csdnimg.cn/direct/11de7a5b82c2465a85d0bd7380867802.png)