一、爬虫的概念
爬虫(Web crawler)是指一种自动获取网页内容的程序,可以自动地浏览互联网上的网页,并提取其中的数据。
爬虫通常由搜索引擎、数据挖掘、信息监测等应用所使用。它通过模拟人的浏览行为,自动地访问网页、下载网页内容,然后解析网页并提取出需要的数据。
爬虫可以从一个起始网址开始,通过分析网页上的链接,不断地跳转到其他网页,从而实现对整个互联网的遍历和数据获取。
爬虫可以通过网页的HTML结构分析和正则表达式等方法来提取数据,也可以通过处理JavaScript渲染和使用XPath、CSS选择器等工具来解析网页。同时,爬虫需要处理反爬虫机制,如验证码、频率限制等,以确保能够正常获取数据。
二、爬虫的作用
场景应用广泛,可以在自已选定目标网站中爬取自已所需要的信息,例如爬取VIP视频、小说、图片、抢票抢购等,或者搜索引擎的索引更新、数据挖掘与分析、价格监控、舆情监测等等。
提示:但是你必须确保自已所爬取的信息不能包含有用户的敏感信息,甚至不能影响网站的正常运转,否则,你会被警察叔叔上门亲自带你去局子喝茶,聊聊天哟
三、爬虫的类别
通用爬虫:通用爬虫是一种能够抓取整个互联网上的信息的爬虫,它会从一个起始链接开始,递归地爬取其他链接。例如,搜索引擎的爬虫就是通用爬虫。
垂直爬虫:垂直爬虫是针对特定领域的爬虫,它只抓取某个特定网站或某类相关网站的信息。例如,新闻爬虫、电商爬虫等。
增量式爬虫:增量式爬虫是指能够识别和抓取新增或更新的网页内容的爬虫,以实现对已存在数据的增量更新。这种爬虫能够记录已访问过的链接,仅对新增的链接进行爬取。
深度爬虫:深度爬虫是指能够实现对动态网页的爬取,包括JavaScript渲染、动态加载和用户交互等。它能够模拟浏览器行为,实现对JavaScript生成内容的爬取。
聚焦爬虫:聚焦爬虫是一种根据用户定义的关键词或规则进行爬取的爬虫,以满足用户特定需求。例如,针对某个特定关键词进行搜索并抓取相关内容。
社交媒体爬虫:社交媒体爬虫主要用于抓取和分析社交媒体平台上的用户数据、帖子、评论等信息,以进行舆情分析、用户行为分析等。
提示:可以根据爬虫的场景来选用不同的爬虫策略,不过在爬虫的过程中需要遵守规则,以免吃上国家饭😂😜
四、爬虫的协议
爬虫协议通常指的是网站通过robots.txt文件或其他方式为网络爬虫(也称为网络机器人或蜘蛛)设定的一系列规则和指南。这些协议定义了爬虫在访问和索引网站内容时应遵循的行为准则,旨在平衡网站内容的可发现性与保护网站资源和版权的需要。
robots.txt的简介
robots.txt是一个位于网站根目录的文本文件,它使用一种简单而通用的格式来告诉爬虫哪些页面可以被抓取,哪些不应该被访问。这个文件的名称和位置遵循了一种约定俗成的协议,大多数遵守规则的爬虫在访问网站之前都会检查这个文件。
robots.txt文件中的指令主要包括:
User-agent:指定哪些爬虫需要遵守以下规则。Disallow:指定不允许爬虫访问的路径。Allow:指定允许爬虫访问的路径(在Disallow指令的上下文中)。Sitemap:指向网站地图文件的URL,帮助爬虫更好地发现网站内容。Crawl-delay:指定了爬虫在连续请求之间应等待的时间,以减轻对服务器的负担。
robots.txt示例文件
User-agent: *
Disallow: /private/
Disallow: /tmp/
Sitemap: http://www.example.com/sitemap.xml
Crawl-delay: 5
提示:
./ #代表根目录
User-agent: * #代表的是那些爬虫
Disallow: / #代表不允许爬虫访问的目录解释:这个文件告诉所有爬虫不要访问private和tmp目录,同时提供了网站地图的URL,并设置了每次爬取之间的延迟为5秒。
其他爬虫协议
除了robots.txt之外,还有一些其他的爬虫协议,例如:
- Crawl-delay:这是一个
robots.txt文件中的参数,用来指定爬虫在连续请求之间应等待的时间,以减轻对服务器的负担。 - Prefer:这是一个HTTP头,用于告诉服务器爬虫希望接收的响应类型,例如,爬虫可能希望避免接收搜索引擎优化(SEO)的页面版本。
注意哈,不是所有的网站都会有robots.txt协议,另外想要查看目标网站的爬虫协议,可以直接在网址上加个“/robots.tx”即可查看(网站也许有可能没有协议),例如:
百度:http://www.baidu.com/robots.txt
新浪新闻:http://news.sina.com.cn/robots.txt
腾讯:http://www.qq.com/robots.txt
腾讯新闻:http://news.qq.com/robots.txt
国家教育部:http://www.meo.edu.cn/robots.txt (注:无robots协议)
五、爬虫的原理
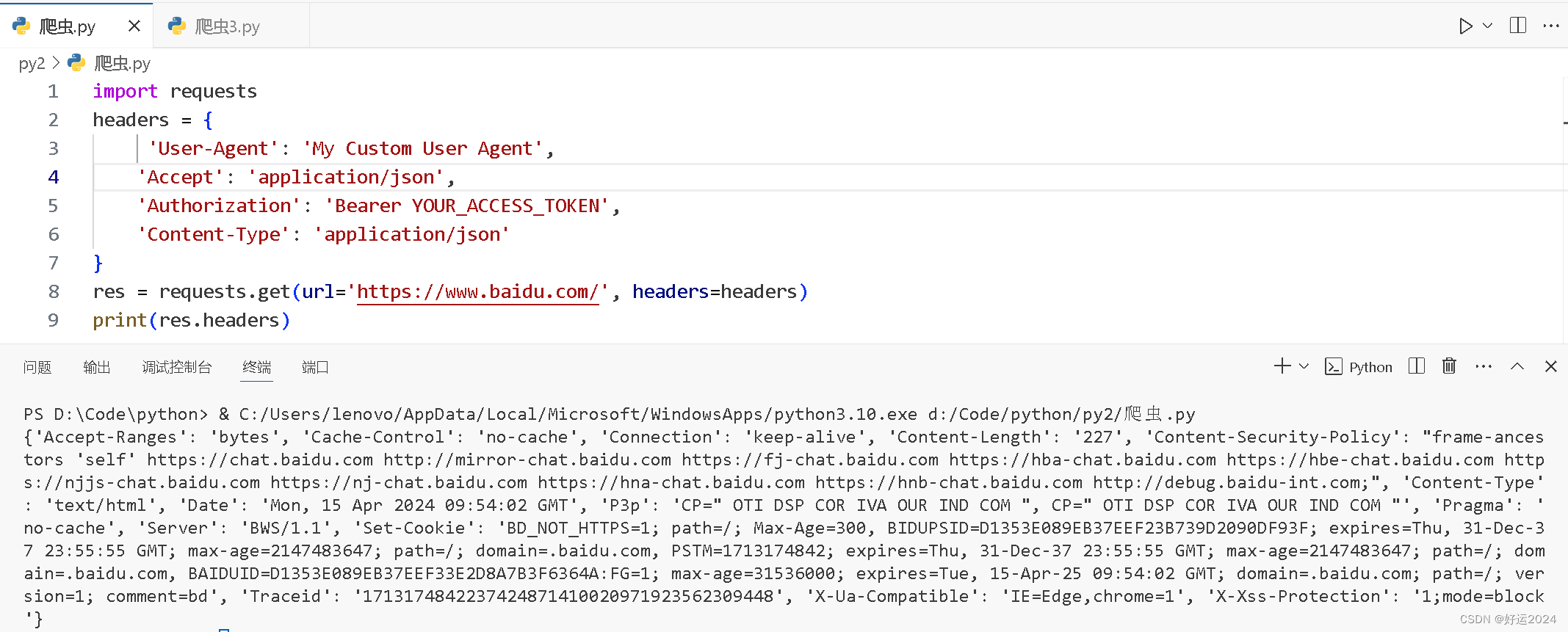
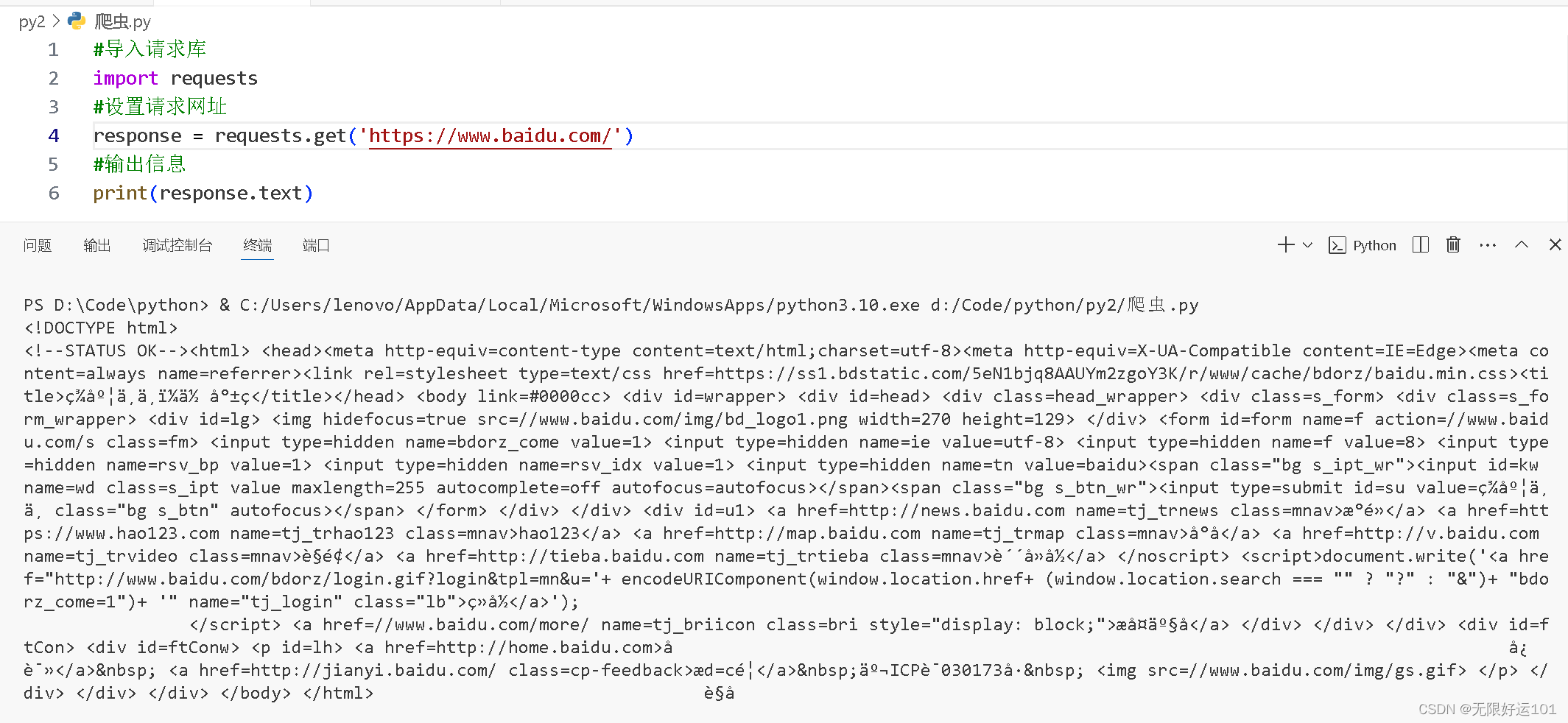
发起请求:爬虫首先需要发送HTTP请求到目标网址,通常使用GET方法。
获取响应:爬虫接收到服务器返回的HTTP响应,包含了网页的内容和相关信息,如状态码、头部信息等。
解析响应:爬虫根据响应的内容,可以使用HTML解析库(如BeautifulSoup)对网页进行解析,提取出需要的数据。
数据处理:爬虫可以对提取的数据进行清洗、整理和处理,以满足特定的需求。
存储数据:爬虫可以将处理后的数据存储到数据库、文件或内存中,以备后续使用。
跟踪链接:爬虫可以从解析的网页中提取出其他链接,将这些链接添加到待爬取的队列中,进行后续的抓取。
重复上述步骤:重复以上步骤,直到完成对所有目标网页的抓取。
基本的爬虫原理就是通过模拟浏览器的行为,从目标网站获取网页数据,并提取出自己需要的信息,然后进行数据处理和存储。
好了今日分享到此一游,点个关注不迷路。感谢有你💖❤️❤️🎁