参考资料:python统计分析【托马斯】
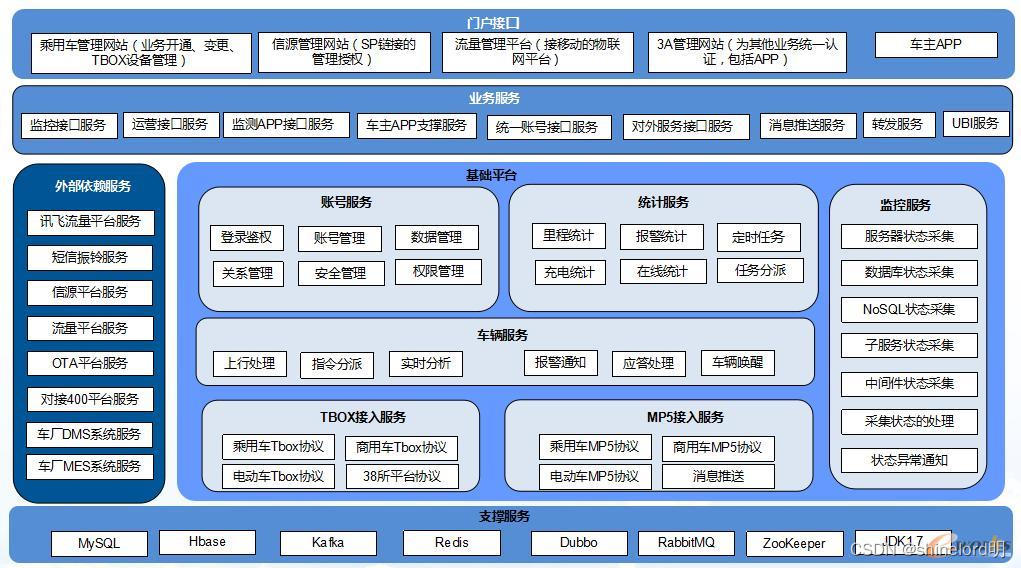
scikit-learn提供了简单而有效的数据挖掘和数据分析工具,包括监督和无监督学习。它提供了如下工具:
分类:辨别出新的观测值应该属于哪一组类别。
回归:对一个新的例子预测一个连续值。
聚类:自动将类似的对象聚成一类。
降维:减少需要考虑的随机变量的个数。
模型选择:比较、验证和选择参数和模型。
预处理:特征抽取和标准化。
在这里我们用它进行一个简单的回归分析。
为了使用sklearn,我们需要以列向量的形式输入我们的数据。因此,我们的例子中,将DataFrame转换为np.matrix,使得垂直数组在数据集中被切下后保持垂直。(这很必要,因为这个别扭的python特性,即numpy数组的一维切片是一个向量,而该向量通常定义为水平方向。)
# 导入库
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import statsmodels.formula.api as smf
from sklearn.linear_model import LinearRegression
from scipy import stats
# 录入数据
region=['North','Yorkshire','Northeast','East_Midlands','West_Midlands',
'East_Anglia','Southeast','Southwest','Wales','Scotland','Northern_Ireland']
Alcohol=[6.47,6.13,6.19,4.89,5.63,4.52,5.89,4.79,5.27,6.08,4.02]
Tobacco=[4.03,3.76,3.77,3.34,3.47,2.92,3.20,2.71,3.53,4.51,4.56]
# 生成dataFrame数据集
df=pd.DataFrame({
'Region':region,
'Alcohol':Alcohol,
'Tobacco':Tobacco
})
# 将dataframe格式数据转换为np.matrix
data=np.array(df)
# 创建回归对象
cln=LinearRegression()
org=LinearRegression()
X,Y=data[:,2].reshape(-1, 1),data[:,1].reshape(-1, 1)
# 线性回归拟合
cln.fit(X[:-1],Y[:-1])
org.fit(X,Y)
# 输出拟合得分
clean_score='{0:.3f}'.format(cln.score(X[:-1],Y[:-1]))
original_score='{0:.3f}'.format(org.score(X,Y))
# 绘制散点图
mpl.rcParams['font.size']=16
plt.plot(df.Tobacco[:-1],df.Alcohol[:-1],'bo',
markersize=10,label='All other regions,$R^2$='+clean_score)
plt.plot(df.Tobacco[-1:],df.Alcohol[-1:],'r*',
ms=20,lw=10,label='N, Ireland, outlier, $R^@$='+original_score)
# 添加预测曲线
test=np.c_[np.arange(2.5,4.85,0.1)]
plt.plot(test,cln.predict(test),'k')
plt.plot(test,org.predict(test),'k--')
# 设置坐标等辅助项目
plt.xlabel('Tobacco')
plt.ylabel('Alcohol')
plt.xlim(2.5,4.75)
plt.ylim(2.75,7.0)
plt.title('Rgression of Alcohol from Tobacco')
plt.grid()
plt.legend(loc='lower center')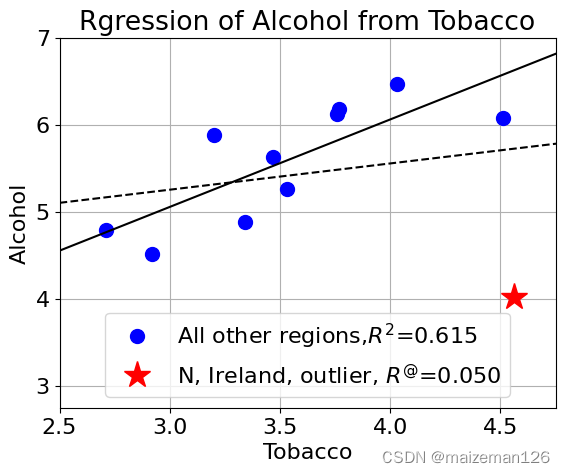
建议1:在做任何数据分析之前,先将数据进行可视化展示。如果数据是高维度的,那么至少用箱线图检查一些切片。
建议2:在数据分析完成后,应该根据我们自有专业背景知识,对模型进行判断。统计学检验应该指导仅指导我们进行推断,但它们不应该占主导地位。