参考:
https://github.com/alibaba-damo-academy/FunASR
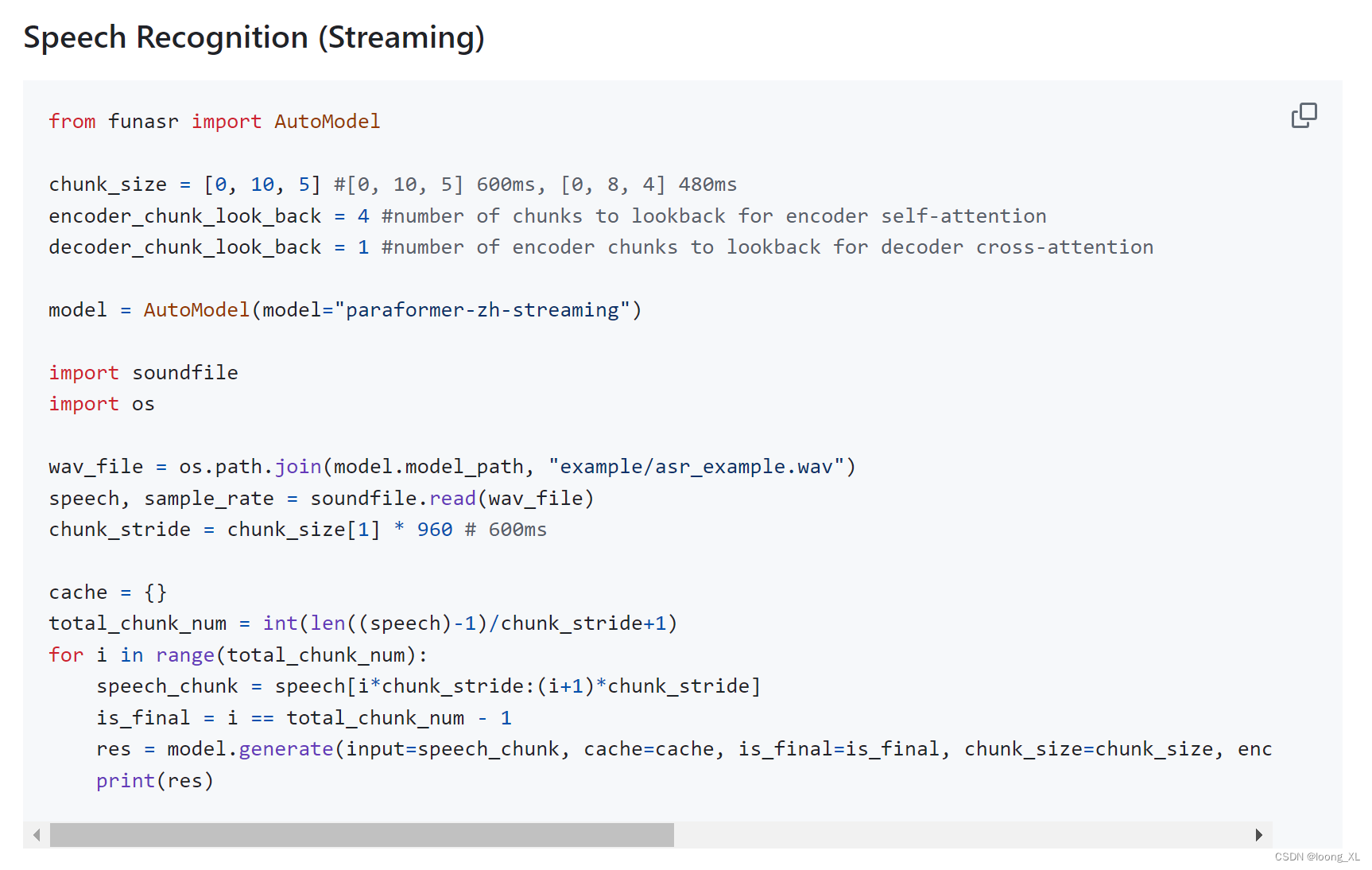
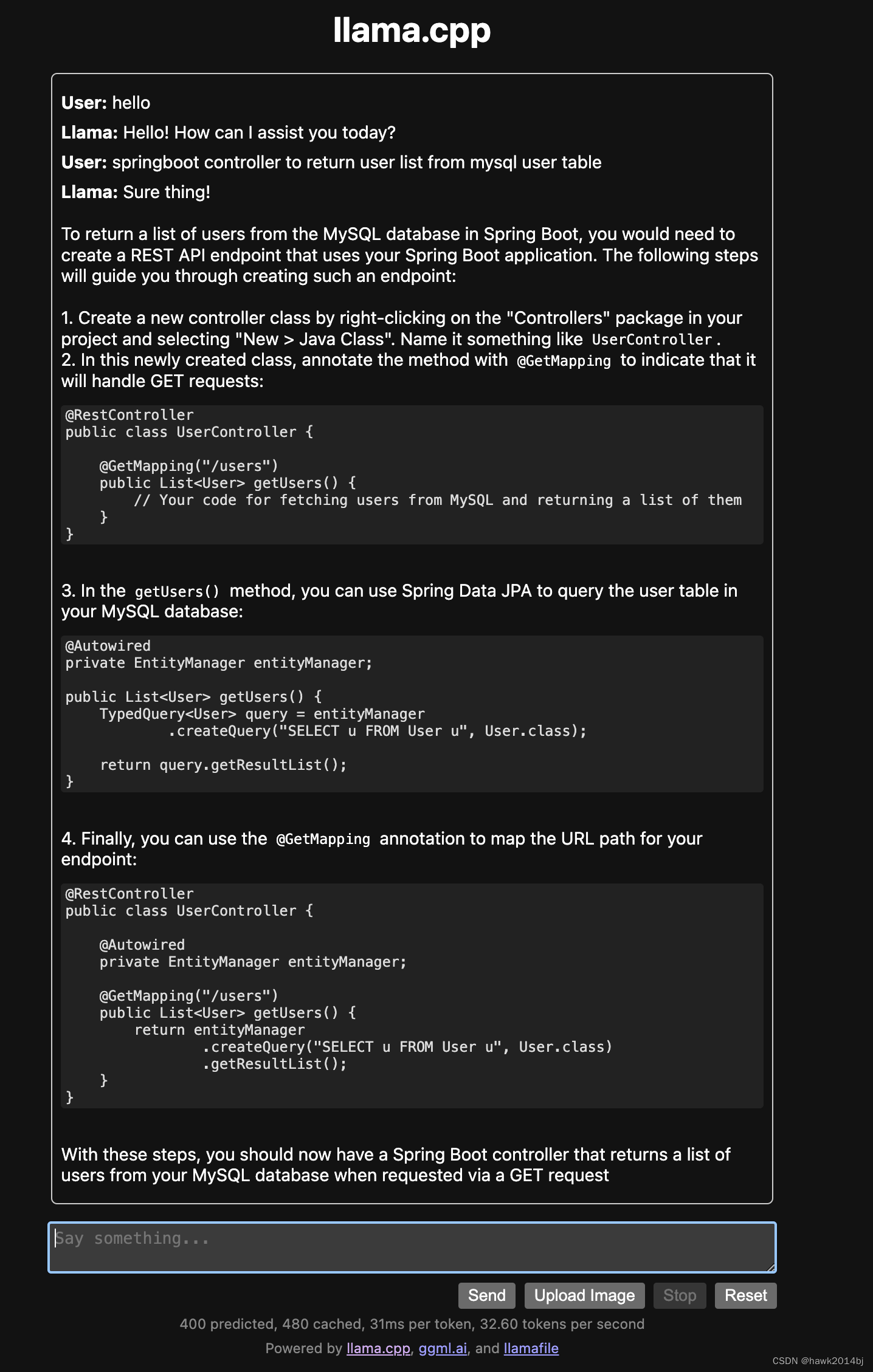
chunk_size 是用于流式传输延迟的配置。[0,10,5] 表示实时显示的粒度为 1060=600 毫秒,并且预测的向前信息为 560=300 毫秒。每个推理输入为 600 毫秒(采样点为 16000*0.6=960),输出为相应的文本。对于最后一个语音片段的输入,需要将 is_final=True 设置为强制输出最后一个词语。
采样率和采样点之间的关系可以用以下公式表示:
总样本数 = 采样率 * 采样时长 ( 16000 * 0.6 = 9600 )
采样率是 16000 Hz,代表每秒钟采集 16000 个样本点。
而每次推理输入的时间范围是