参考自:
- 参考配置:FunASR/runtime/docs/SDK_advanced_guide_offline_zh.md at main · alibaba-damo-academy/FunASR (github.com)
- 参考配置:FunASR/runtime/quick_start_zh.md at 861147c7308b91068ffa02724fdf74ee623a909e · alibaba-damo-academy/FunASR (github.com)
- 参考运行命令:FunASR/runtime/python/websocket/README.md at 861147c7308b91068ffa02724fdf74ee623a909e · alibaba-damo-academy/FunASR (github.com)
阿里达摩院
服务端
安装 Docker
(过程省略)
下面步骤如果是在 Linux 需要以管理员方式执行命令,开头添加
sudo
docker 拉取镜像
docker pull registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-cpu-0.4.4
创建模型目录
mkdir -p ./funasr-runtime-resources/models
运行 docker 镜像
docker run -p 10095:10095 -it --privileged=true -v $PWD/funasr-runtime-resources/models:/workspace/models registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-cpu-0.4.4
启动服务
cd FunASR/runtime
nohup bash run_server.sh \
--download-model-dir /workspace/models \
--vad-dir damo/speech_fsmn_vad_zh-cn-16k-common-onnx \
--model-dir damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-onnx \
--punc-dir damo/punc_ct-transformer_cn-en-common-vocab471067-large-onnx \
--lm-dir damo/speech_ngram_lm_zh-cn-ai-wesp-fst \
--itn-dir thuduj12/fst_itn_zh \
--hotword /workspace/models/hotwords.txt > log.txt 2>&1 &
# 如果您想关闭ssl,增加参数:--certfile 0
# 如果您想使用时间戳或者nn热词模型进行部署,请设置--model-dir为对应模型:
# damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-onnx(时间戳)
# damo/speech_paraformer-large-contextual_asr_nat-zh-cn-16k-common-vocab8404-onnx(nn热词)
# 如果您想在服务端加载热词,请在宿主机文件./funasr-runtime-resources/models/hotwords.txt配置热词(docker映射地址为/workspace/models/hotwords.txt):
# 每行一个热词,格式(热词 权重):阿里巴巴 20(注:热词理论上无限制,但为了兼顾性能和效果,建议热词长度不超过10,个数不超过1k,权重1~100)
客户端
下载客户端测试工具
wget https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/sample/funasr_samples.tar.gz
解压上面链接下载的文件。比如我解压到目录 C:\Users\z\Documents\FunASR
解压所在目录下的 funasr_samples\samples 目录为不同类型的语言相关的使用文件
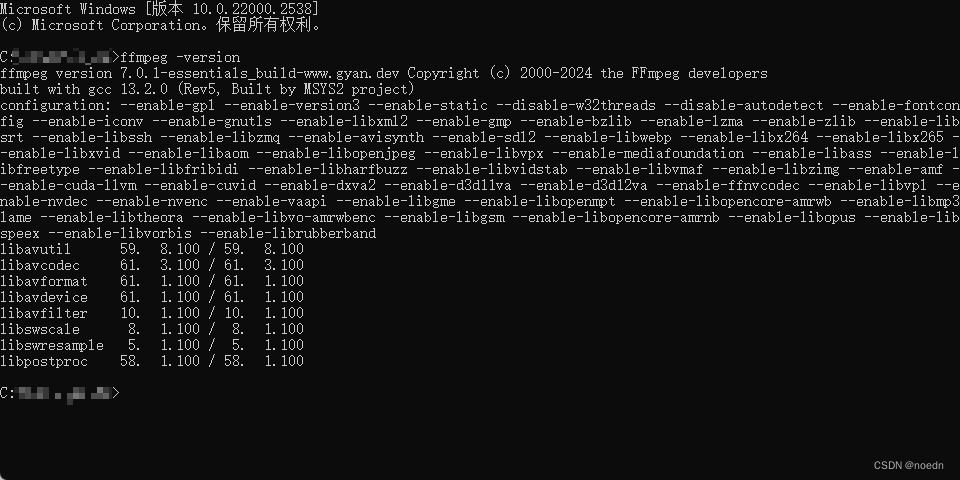
安装 FFMpeg
apt-get install -y ffmpeg # ubuntu
# yum install -y ffmpeg # centos
# brew install ffmpeg # mac
# winget install ffmpeg # wins
HTML
解压进入目录:C:\Users\z\Documents\FunASR\funasr_samples\samples\html\static
打开 index.html 使用网页的形式进行操作
Python
下载 python
https://www.python.org/ftp/python/3.11.8/python-3.11.8-amd64.exe
pip 安装依赖库
pip install -U modelscope funasr -i https://mirror.sjtu.edu.cn/pypi/web/simple
pip install -U torchaudio websockets pyaudio ffmpeg-python -i https://mirror.sjtu.edu.cn/pypi/web/simple
运行客户端
# 这个目录取决于上面你解压的文件所在的目录
cd C:\Users\z\Documents\FunASR\runtime\python\websocket
# 识别本地文件
python funasr_wss_client.py --host "127.0.0.1" --port 10095 --mode offline --audio_in "C:\Users\z\Videos\02d0b6703d9b5d6bc05a46548a938826_new.mp3"