请解释TensorFlow中的自动微分(Automatic Differentiation)是如何工作的。
TensorFlow中的自动微分(Automatic Differentiation)是一个强大的工具,它使得计算和优化复杂函数的梯度变得简单而高效。自动微分是TensorFlow进行深度学习模型训练的核心部分,因为梯度下降等优化算法需要知道损失函数相对于模型参数的梯度。
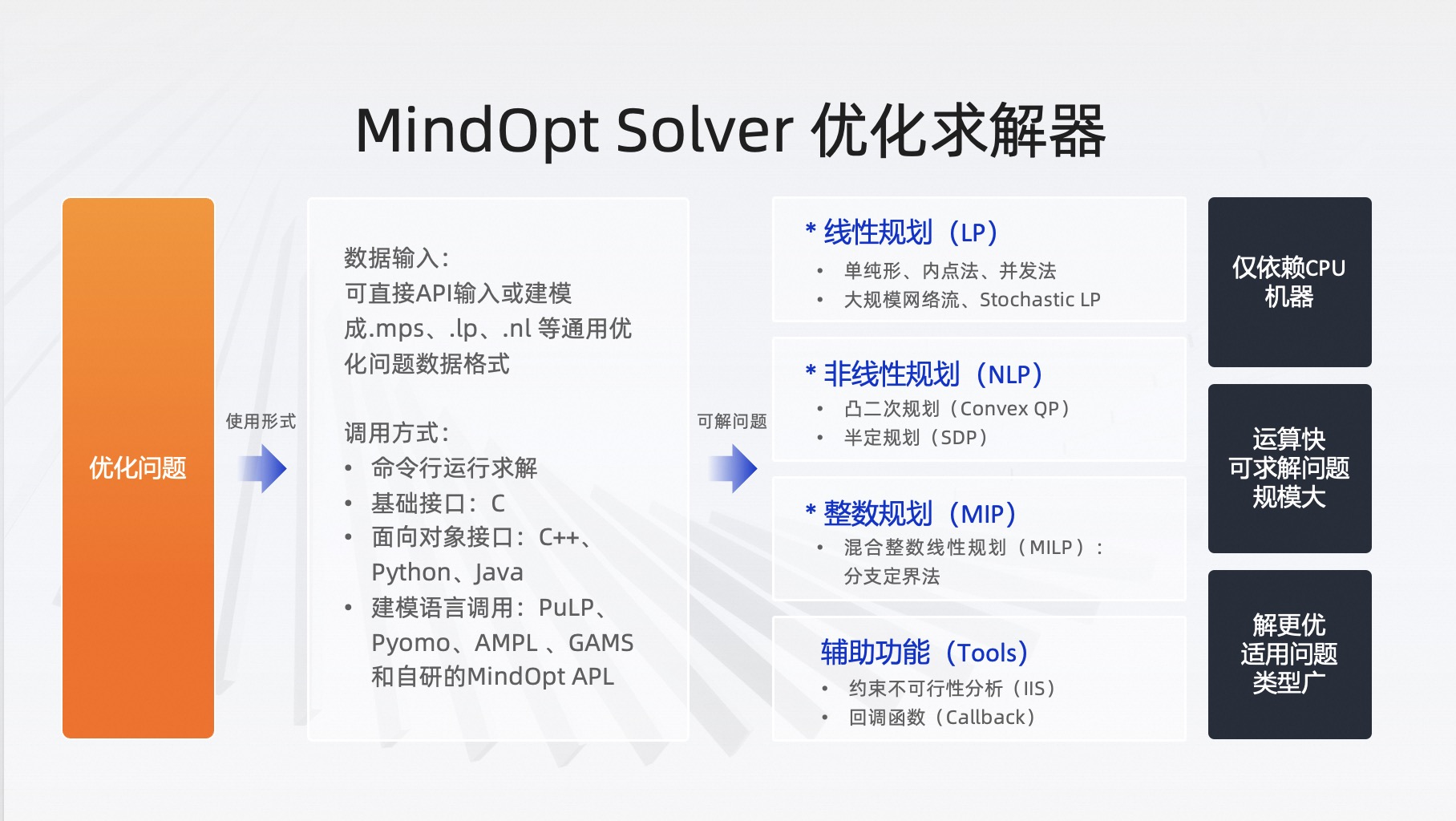
自动微分在TensorFlow中的工作原理主要基于以下两个关键概念:
计算图(Computational Graph):
TensorFlow通过构建一个计算图来表示和执行数学运算。计算图中的节点代表张量(多维数组),边代表操作(如加法、乘法等)。当我们在TensorFlow中定义一个计算时,我们实际上是在构建这个计算图。这个图不仅包含了前向传播的计算过程(从输入到输出的计算),还包含了必要的操作来反向传播梯度。
反向传播(Backpropagation):
一旦计算图被构建,TensorFlow就可以利用反向传播算法来计算梯度。反向传播是自动微分的一种形式,它基于链式法则来计算复合函数的导数。在TensorFlow中,我们不需要手动实现反向传播的细节;相反,我们只需要定义一个损失函数(即我们要优化的目标),然后调用优化器(如梯度下降优化器)来自动计算梯度并更新模型参数。
当TensorFlow执行反向传播时,它会从计算图的输出节点(损失函数)开始,沿着计算图的边反向遍历,计算每个节点相对于其输入的梯度。这些梯度最终被用来更新模型参数,以最小化损失函数。
需要注意的是,TensorFlow使用了一种称为“即时执行”(Eager Execution)或“图执行”(Graph Execution)的模式来执行计算。在即时执行模式下,TensorFlow会立即计算每个操作的结果,这使得调试和原型设计更加直观。而在图执行模式下,TensorFlow会首先构建一个完整的计算图,然后在一个单独的步骤中执行整个图。虽然图执行模式在某些情况下可能更高效,但即时执行模式通常更适合开发和调试。
总的来说,TensorFlow通过构建计算图并利用反向传播算法来实现自动微分,这使得深度学习模型的训练变得简单而高效。
如何使用TensorFlow进行分布式训练?
使用TensorFlow进行分布式训练是一个相对复杂的任务,但TensorFlow提供了各种工具和API来简化这个过程。分布式训练通常涉及多个计算节点,每个节点可以是一个或多个GPU或CPU,它们协同工作以加速训练过程。以下是一个简化的步骤说明,指导你如何使用TensorFlow进行分布式训练:
环境准备
确保你的环境中安装了适当版本的TensorFlow,并且所有的计算节点都能够相互通信。你可能需要配置网络以允许节点之间的数据传输。数据分布
将你的训练数据分布到不同的计算节点上。这可以通过使用tf.data.Dataset API来实现,该API允许你创建分布式的数据输入管道。选择分布式策略
TensorFlow提供了几种分布式策略,你可以根据你的需求选择适合的策略。这些策略包括:
tf.distribute.MirroredStrategy:适用于同步分布式训练,其中所有变量都在所有设备上镜像。
tf.distribute.ParameterServerStrategy:适用于大型集群的异步或同步训练。
tf.distribute.experimental.CentralStorageStrategy:适用于少量GPU的同步训练。
tf.distribute.experimental.TPUStrategy:专门用于TPU硬件的分布式训练。
4. 创建分布式策略作用域
在你的代码中,使用选定的分布式策略创建一个作用域。在这个作用域内,TensorFlow将自动处理变量的复制和操作的分布。
python
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
# 在这里定义你的模型、优化器等
model = …
optimizer = …
5. 定义模型和优化器
在分布式策略的作用域内定义你的模型和优化器。TensorFlow将自动处理这些对象在多个设备上的复制。
编译模型
使用适当的损失函数和评估指标编译你的模型。分布式训练循环
使用TensorFlow的分布式API来编写你的训练循环。这通常涉及使用strategy.run方法来在多个设备上并行执行操作。
python
@tf.function
def distributed_train_step(dist_inputs):
with tf.GradientTape() as tape:
logits = model(dist_inputs, training=True)
loss_value = loss_obj(y_true, logits)
grads = tape.gradient(loss_value, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
训练循环
for epoch in range(num_epochs):
for batch in train_dataset:
strategy.run(distributed_train_step, args=(batch,))
8. 分布式评估
你也可以使用分布式策略来评估模型的性能。这可以通过在分布式策略作用域内调用模型的evaluate方法来实现。
注意事项:
确保所有计算节点都有相同的TensorFlow版本和依赖项。
根据你的硬件和网络配置调整分布式策略的参数。
分布式训练可能需要更多的内存和计算资源,因此请确保你的系统有足够的资源来处理分布式工作负载。
监控和调试分布式训练可能比单机训练更复杂,因此请确保你有适当的工具和策略来诊断和解决问题。