一. 特殊符号的含义
量词
*:表示前面的模式零次或多次+:表示前面的模式一次或多次?:表示前面的模式零次或一次{n}:表示前面的模式恰好 n 次{n,}:表示前面的模式至少 n 次{n,m}:表示前面的模式至少 n 次且不超过 m 次
分组和捕获
( ):用于分组和捕获子表达式(?: ):用于分组但不捕获子表达式
特殊字符
\:转义字符,用于表示特殊字符本身.:表示任意字符(除了换行符\r\n)|:用于指定多个模式的选择
锚点
^表示字串开头$表示字串结尾\b表示一个单词的边界,即字与空格间的位置\B表示非单词的边界
字符类
[ ]:表示括号内的任意一个字符。例如,`[abc]`` 表示字符 “a”、“b” 或 “c”[^ ]:表示除了括号内的字符以外的任意一个字符。例如,[^abc]表示除了字符 “a”、“b” 或 “c” 以外的任意字符\w:表示一个字符,该字符是字母,数字,下划线. 等价于[A-Za-z0-9_]\d:表示一个阿拉伯数字. 等价于[0-9]
eg: ^[0-9].*[abc]$ 表示"以数字开头,以a或b或c结尾的字串"
[^aeiou]表示字串中,所有不是aeiou的字符
([1-9])([a-z])
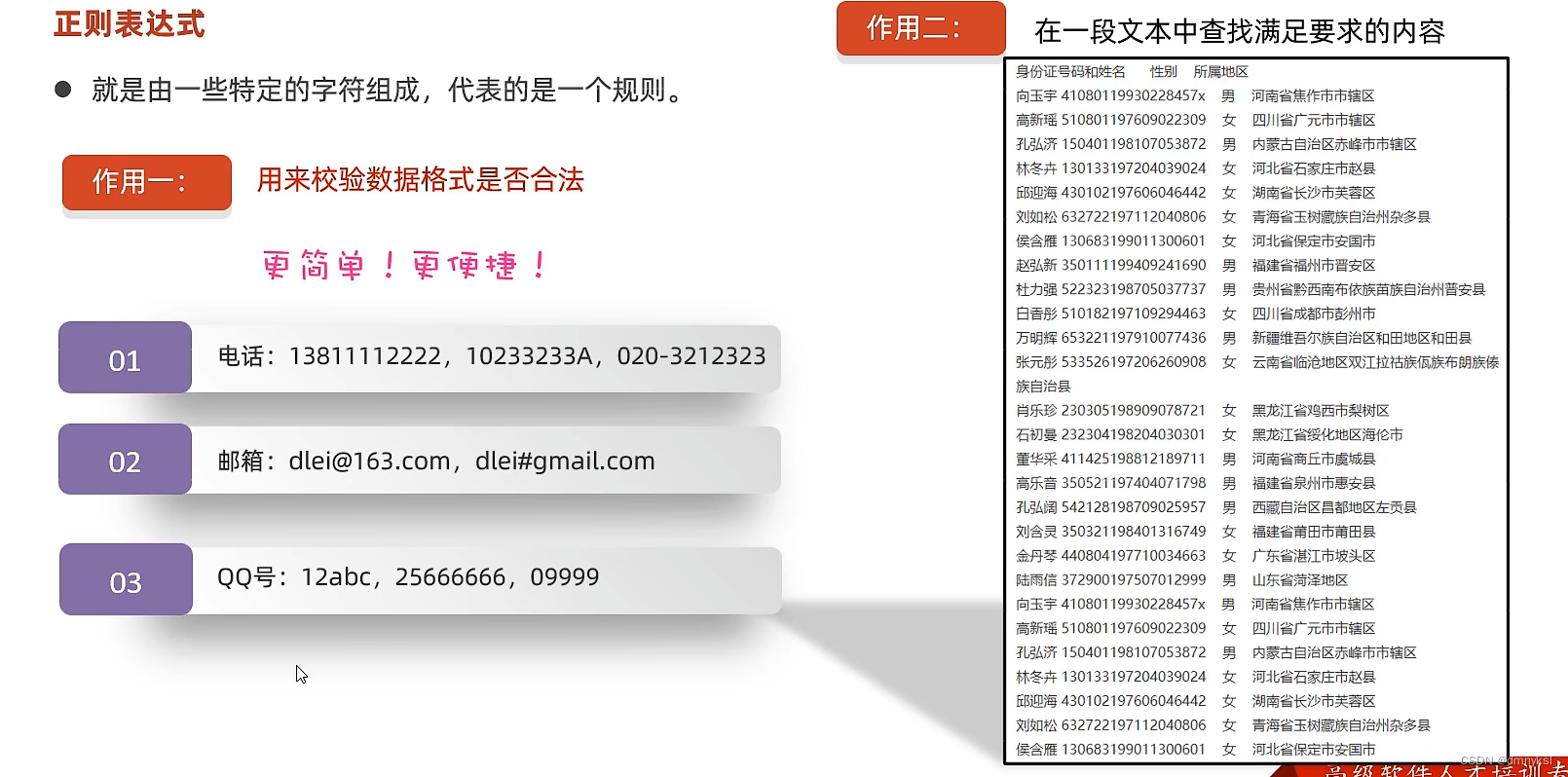
二. 正则表达式可以干什么
- 测试字符串是否满足正则表达的某个格式
- 替换正则表示到的文本
- 从字串中提取正则表示的子字符串
三. 定位查询
前面讲了, ( )用于匹配后捕获字串的. 但如果( )里是以下面这4个符号?=、?!、?<=、?<!开头,则表示以括号内的内容作为定位
exp1(?=exp2): 以 exp2 为定位, 匹配 exp2 前面的 exp1
runoob(?=[\d]+): 匹配后面是数字的 runoobexp1(?!exp2): 匹配 exp1, 但不要在 exp2 之前
runoob(?![\d]+): 匹配后面不是数字的 runoob(?<=exp2)exp1: 匹配 exp2 后面的 exp1
(?<=[\d]+)runoob: 匹配前面是数字的 runoob(?<!exp2)exp1: 匹配 exp1, 但不要在 exp2 后面
(?<![\d]+)runoob: p匹配前面不是数字的 runoob
四. 反向引用
()匹配到的内容,会被正则引擎放到缓冲区中.缓冲区编号从1开始,最大到99.如果想引用前面缓冲区匹配到的内容, 用 \n 表示即可. 比如 \1 表示第一个缓冲区匹配到的内容.反向引用的最简单的、最有用的应用之一,是匹配出文本中两个相同的相邻单词字串.
eg: 匹配 ‘Is is the cost of of gasoline going up up’ 字串中相同的连续字串.
eg: 用这则表达式判断一个数是否是素数
因为1+表示至少一个1,所以11+表示2个以上的1. \1表示(11+)匹配到的串,这样(11+)\1表示能被2整除. 后面加上’+'就能表示能被3以上整除了

























![[HDFS 相关Shell命令]](https://img-blog.csdnimg.cn/direct/cff8b72a5e0b4e61964091a636cf86b5.png)
![[Python图像识别] 五十二.水书图像识别 (2)基于机器学习的濒危水书古文字识别研究](https://img-blog.csdnimg.cn/direct/0ae62eb576ad40efabf84a0ac24a3e2c.png#pic_center)