DDPG
Deep Deterministic Policy Gradient,基于actor-critic模型提出了一个有效的value based连续型空间的RL算法,引入了一些帮助训练稳定的技术。
基础:DQN,Batchnormm,Discretize,微积分
background
DQN改进的推广
Policy based方法(TRPO)已经在action space取得突破
传统discretize action space无法拓展到高维空间,阻碍了value based在连续型空间发展
Ornstein-Uhhlenbeck process(OUN),是一种回归均值的随机过程

η(t)是白噪声white noise
核心
推广了DQN到连续action space
使用同样的网络结构和超参数,这个agent能robust的学习解决20多个环境
该算法学习到的策略接近甚至超过知道物理模型的planing算法
DDPG and DQN
DDPG:replay buffer,critic Q网络(s,a|θ^Q) and actor μ(s|θ^μ) 参数: θ^Q and θ^μ、目标Q网络
DQN:replay buffer 、Q function with random weights θ、目标Q网络
DDPG:在连续性action space上均匀抽样,初始化一个随机过程N,收到初始观察状态S1
DQN:初始化序列s1和过程序列
action根据current policy和exploration noise,而不是Epsilon greedy(Qsa)
先将下一个state带入actor得到At+1的估计,在带入Q网络得到估计,即选择action
DDPG:求导增长Qsi,μsi的值:调整actor,使critic给出更高评分,直接朝高reward的actor移动
DQN:增加reward更高的action的概率
soft updata 目标Q网络
如果把 μ(s|θ^μ)看成action,DQN和DDPG基本相似
- 都可以认为有一个Actor和一个Critic
- 更新Critic(Q-value)时,计算target value都用到了Actor
- 都有replay buiffer,target network
主要区别
- 可处理连续action空间
- 有一个显示的Actor,而不是直接greedy原则选择action
- 有一个显示的Exploration Noise 而不是ε-greedy
- 有一个显示更新Actor的过程
网络结构
在不同环境下,观察可能有不同的physical units,使得网络有效学习和在不同状态价值的scale下发现超参数十分困难。可能在不同环境下需要调整参数才能使训练稳定进行。
解决:batch normalization。可以控制某一层输出在某种尺寸,不同scale的输入得到相同scale的输出。
核心思想
假如Qsa已得到一定训练,调整actor参数,使Qsa达到greedy
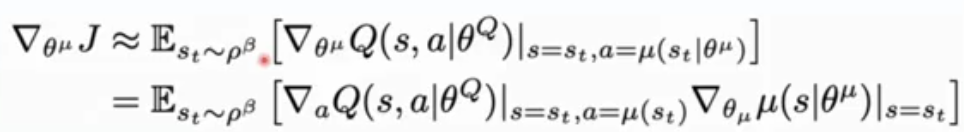
细节
- Exploration Noise使用OSN:探索和学习算法相互独立,可以选择在noise process N采样的noise
- Actor和Critic都有target network,都用了soft update
- Agent的每个动作实际重复执行了三次
- 图像输入也有预处理
- 对ACtor和和Critic不同的学习率,不同weights decay
- 全连接层特殊的初始化方法
- 过去的valuebased方法主要集中discrete的action apace,所以本文没有比较其他DRL算法,二十选取了一个planning的baseline,理解为用物理方法去“估计”一个最好的行动来作为策略,并与其在大量环境种比较,来衡量算法表现。
网络结构
Actor
BarchNorm应该在全连接层之后,activation之前。
每一层应该有对应自己的batchNorm,不能一个BatchNorm作用在多个地方
Critic
torch.cat连接action和上一层的输出。
BatchNorm
数学公式

实际使用有train()和eval()俩种模式的区别。
softupadata( actor , critic ,1)当tau=1时,俩个网络结构应当输出完全一样;然而实际上有细微的差别,原因:barchNorm层有不是Rarameter但是对结构有影响的量running_mean和running_var,在train()mode中,running_mean和running_var不参与计算,只会进行更新,而eval() mode中,这俩个量会参与计算。→在俩个网络中,running_mean和running_var并不相同,所以结果不同。
修改soft_updata(),使这些参数也能拷贝过去即可。
Updata Critic AND Actor
Update Critic
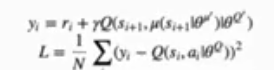
value method算法中,离散型action看见的Q函数更新:
使用target network计算出需要的action;将target network得到的action带入target network得到next state-action value;计算local network的更新目标,并使用MSE loss更新。
连续型action的应用步骤思想与此相同。
Update Actor
标准公式及其化简
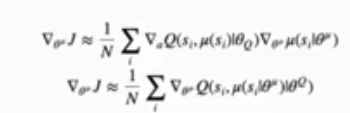
Actor的更新,就是选择Critic中state-action value更好的action
和policy methonds 不同,不是计算action的acvantage如何决定增大或减少其概率来改变分布,而是直接寻找最好的action。
具体寻找方法是:将Actor得到的action直接带入Critic,通过优化Critic的输出值,得到action的导数,然后进一步使用这个导数更新Actor的参数
代码
DDPG_Agent
actor学习率,critic学习率,softupdate参数, 每step更新一次,每个action作learning_time次更新,hidden为神经网络hidden liner宽度后期逐渐降低noise的影响,使训练更平稳























![[数据结构初阶]二叉树](https://img-blog.csdnimg.cn/direct/887335f592bc4747a4cf4a5fbe434b68.png)



![P8786 [蓝桥杯 2022 省 B] 李白打酒加强版](https://img-blog.csdnimg.cn/direct/23ce5a564fcf4c298a52a6fa9e4b3477.png)