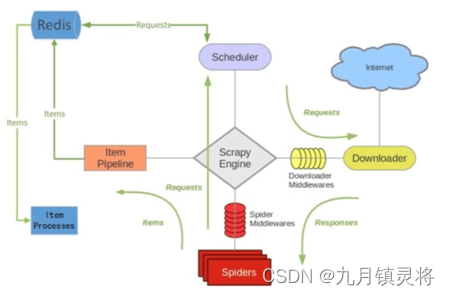
创建Scrapy项目:测试项目为lufei小说

创建爬虫模版:要先切换到刚刚创建的lufei路径下面,名称为lufeishuo,域名为b.faloo.com

模版创建好之后修改stat_url为自己要爬取的url
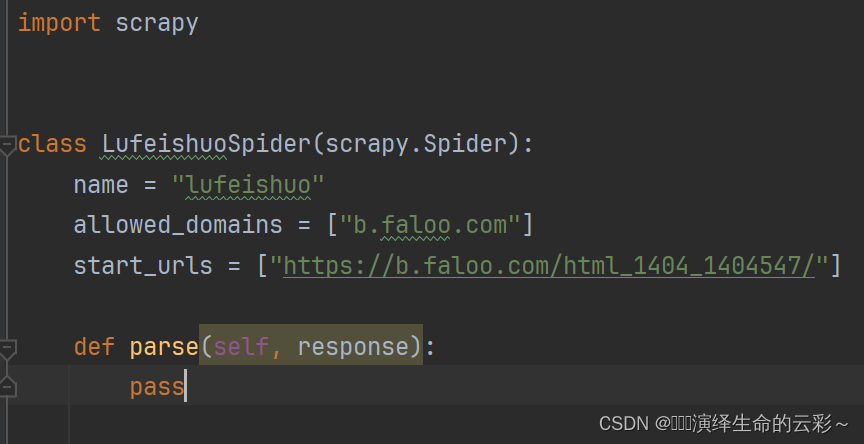
import scrapy
class LufeishuoSpider(scrapy.Spider):
name = "lufeishuo"
allowed_domains = ["b.faloo.com"]
start_urls = ["https://b.faloo.com/html_1404_1404547/"]
def parse(self, response):
print(response.text)
然后修改设置settings.py,改成不接受协议False

解开注释并添加自己的User_Agent伪装一下

在scrapy.cfg的同级目录下面创建start.py文件

在start文件中写入启动程序

右键运行至此结束