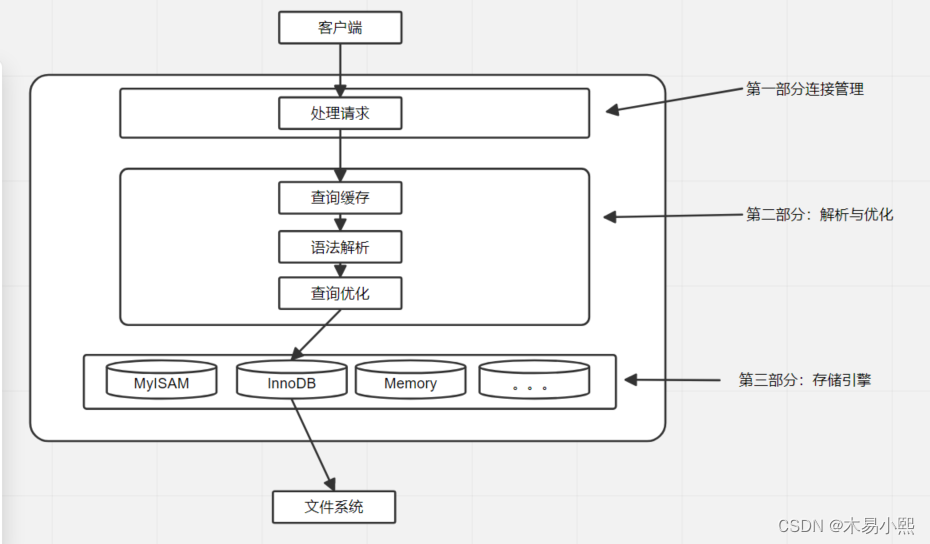
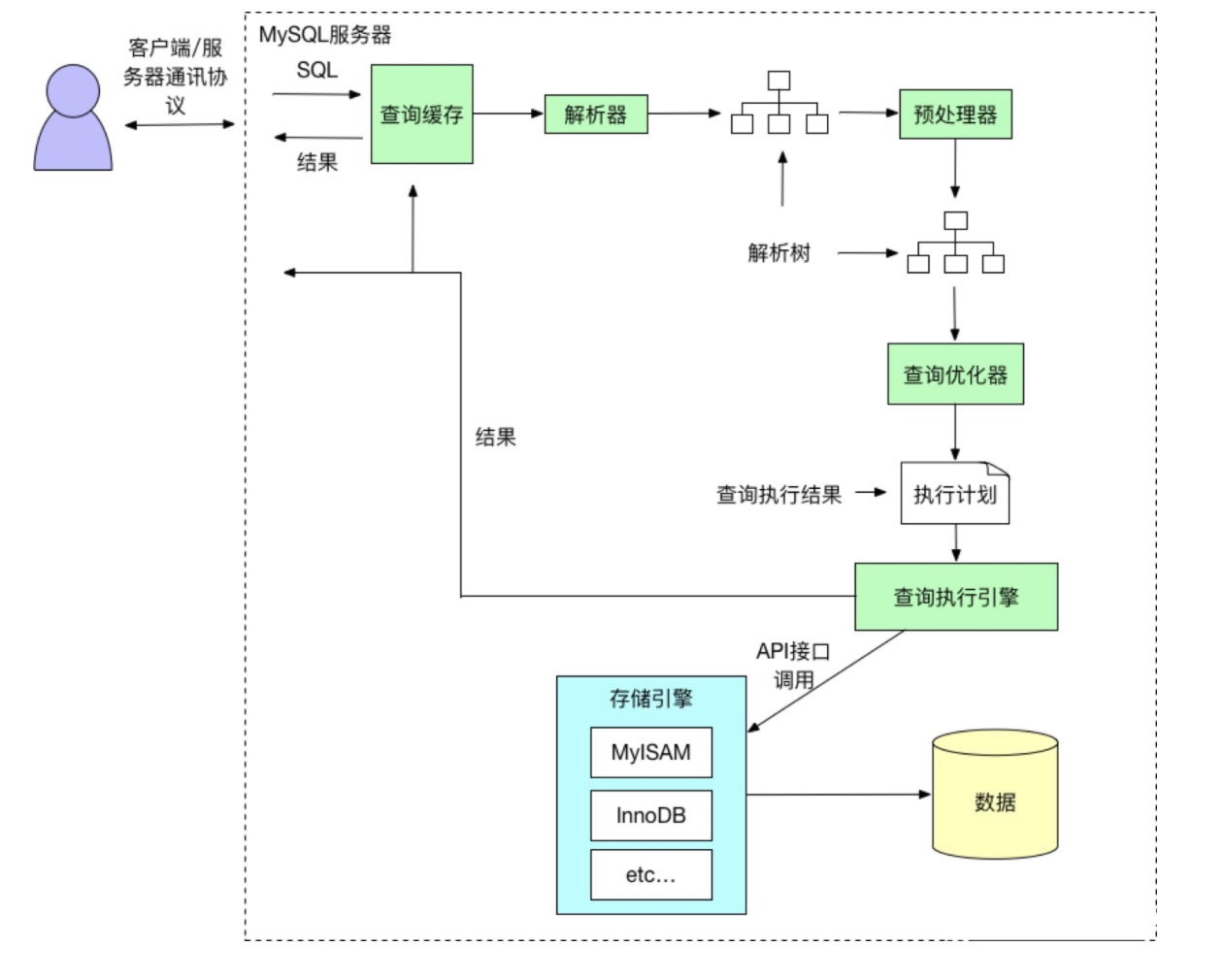
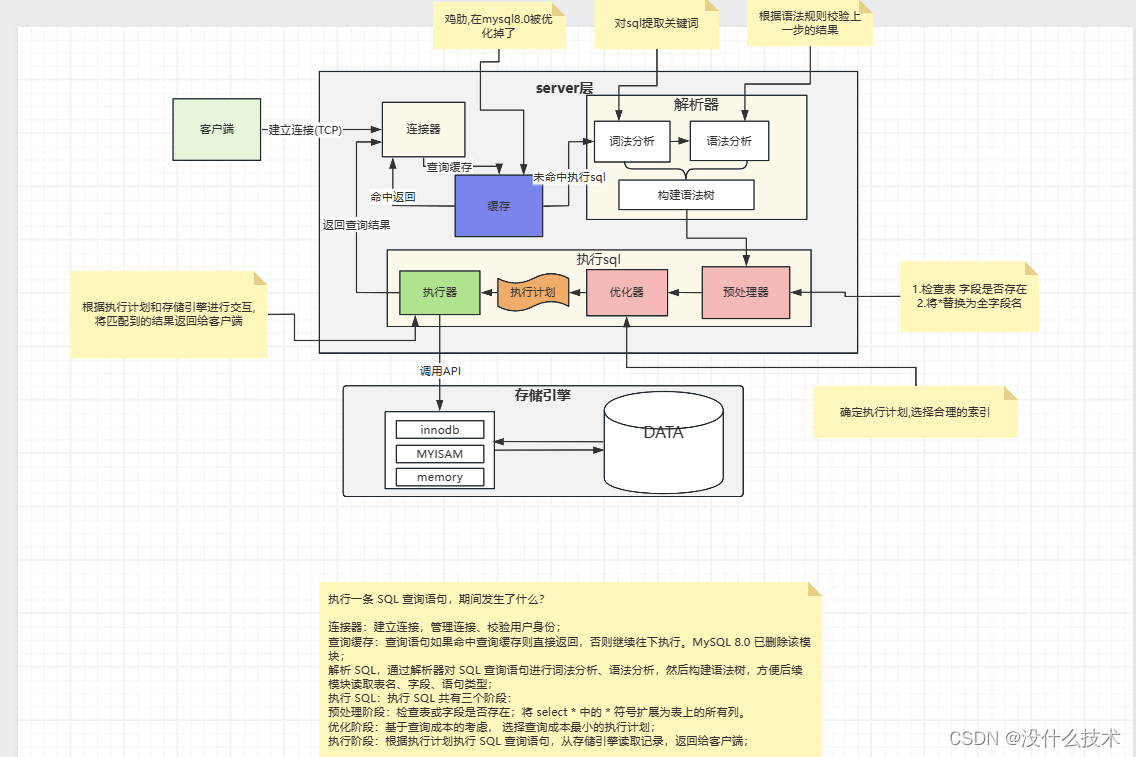
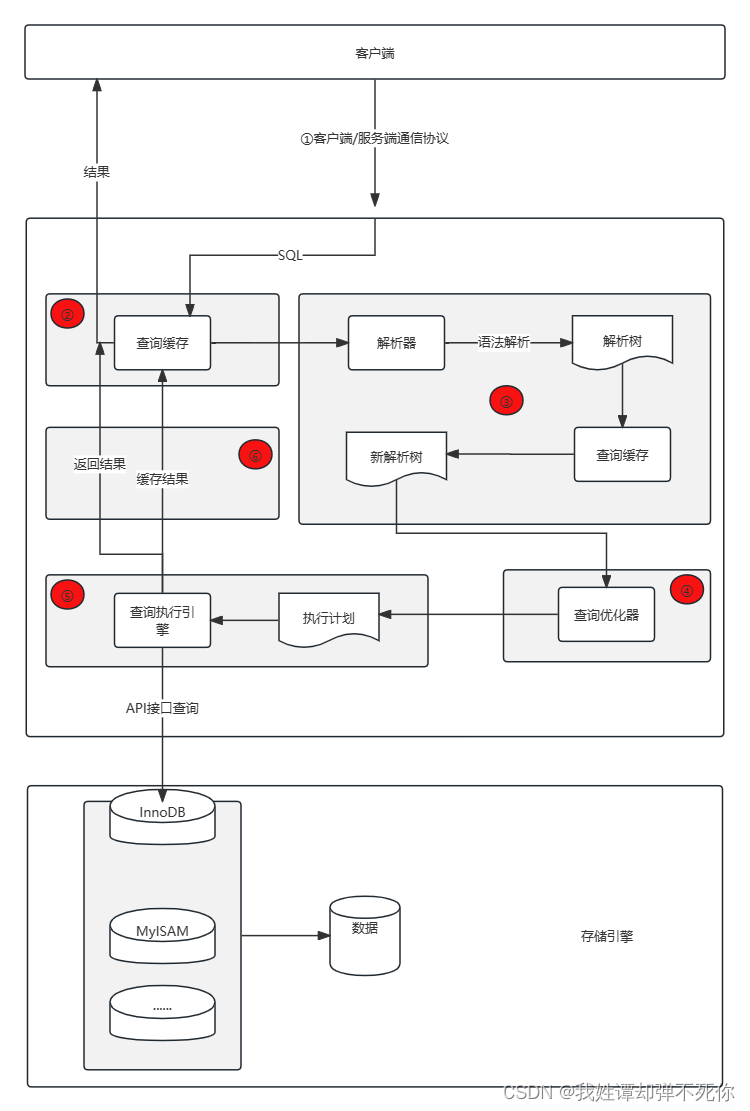
连接器 —> 查缓存 —> 解析SQL —> 执行SQL
连接器:
建立连接(TCP三次握手)相当于
mysql -h$ip -u$user -p、管理连接、检验用户身份(给予相应的权限)
查询缓存:
每当执行查询语句时,会从查询缓存中查找缓存数据,这个查询缓存是以 key-value 形式保存在内存中的,key 为 SQL 查询语句,value 为 SQL 语句查询的结果。
如果查询缓存中有数据就会返回value给客户端
如果没有就继续往下执行,执行完查询语句,以key-value形式存储到查询缓存中
注意:对于更新操作比较频繁的表,查询缓存是很鸡肋的。因为每更新一次,被更新表的查询缓存会直接清空,那你查询大概率是查不到查询缓存的。
解析SQL:
词法分析:解析出关键字和非关键字。(比如
select id from user;select和from是关键字,id和user是非关键字)语法分析:用 关键字 来通过 语法树 来判断sql语句是否合法。
执行SQL:
预处理阶段:
判断 表 和 字段 是否存在。(这是mysql8的,mysql5.7是在预处理阶段之前判断)
将 * 号替换成 表的所有列字段
优化阶段:
基于查询成本的考虑, 选择查询成本最小的执行计划;
比如:
select id from user where id>1 and age=16(id是主键索引,age是二级索引)。这可以用主键索引也可以使用二级索引。
但很显然这条查询语句是覆盖索引,直接在二级索引就能查找到结果(因为二级索引的 B+ 树的叶子节点的数据存储的是主键值),就没必要在主键索引查找了,因为查询主键索引的 B+ 树的成本会比查询二级索引的 B+ 的成本大,优化器基于查询成本的考虑,会选择查询代价小的普通索引。
执行阶段:
三个模式:
主键索引查询:
select * from product where id = 1;利用主键索引的b+树查找。全表扫描:查询语句的查询条件没有用到索引
索引下推:联合索引的情况会有。
比如:
select * from t_user where age > 20 and reward = 100000;联合索引当遇到范围查询就会停止匹配,也就是 age 字段能用到联合索引,但是 reward 字段则无法利用到索引。在MySQL 5.6之前的版本中,没有使用索引下推时,执行器与存储引擎的查询流程如下:
Server层调用存储引擎接口找到满足age > 20的第一条二级索引记录。
存储引擎通过B+树找到记录,获取主键,回表操作,返回完整记录给Server层。
Server层判断记录的reward是否等于100000,满足则发送给客户端,否则跳过。
Server层继续请求下一条记录,存储引擎重复步骤2和3。
重复步骤3-4,直至读取完表中所有记录。
使用索引下推后,存储引擎层负责判断record的reward是否等于100000,流程如下:
Server层调用存储引擎接口找到满足age > 20的第一条二级索引记录。
存储引擎找到二级索引记录,先判断包含的列(reward列)条件(reward是否等于100000)。
如果条件满足,则回表操作,返回完整记录给Server层;否则跳过。
Server层判断其他条件(本次无其他条件),满足则发送给客户端;否则跳过,请求下一条记录。
重复步骤3-4,直至读取完表中所有记录。