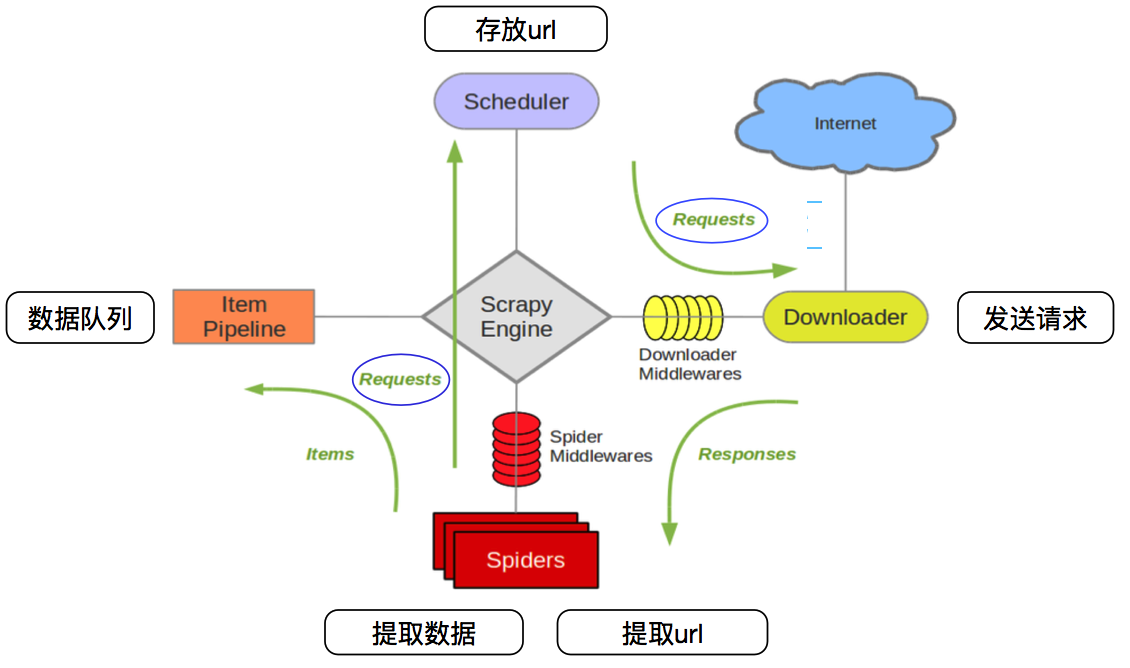
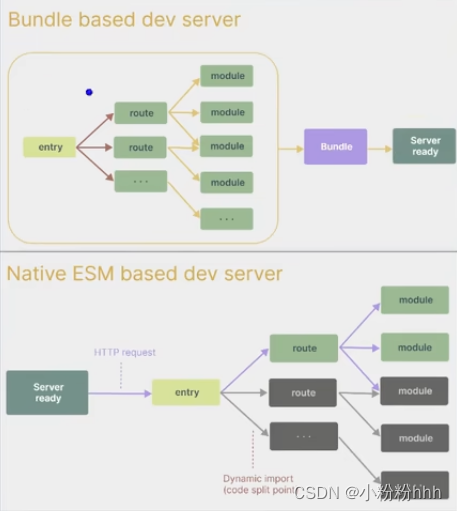
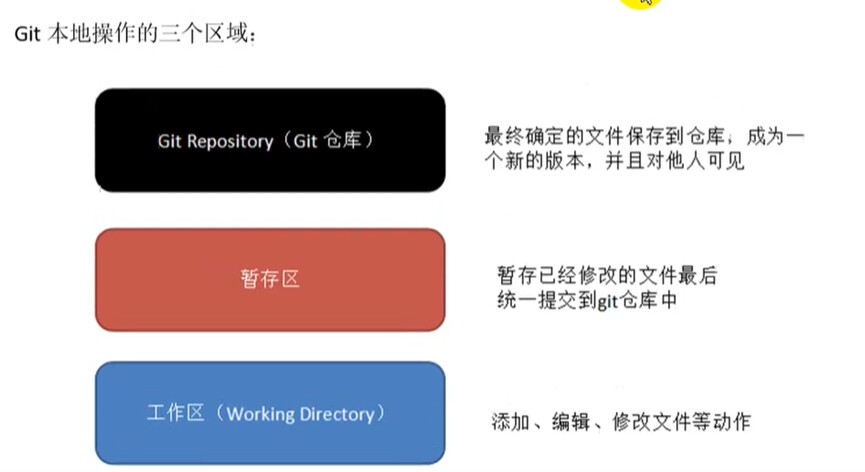
1、安装scrapy
2、使用scrapy创建项目,在终端命令行 执行如下命令,会创建一个myproject项目
scrapy startproject myproject
3、创建完成后,目录结构如下
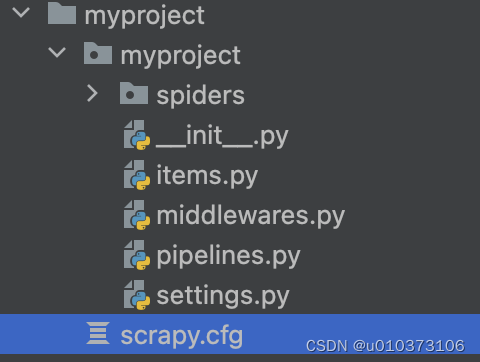
4、cd myproject进入项目 ,执行scrapy genspider weather ******,会在spiders下创建一个ptyhon文件
scrapy genspider weather weather*****
5、这个文件里面就可以写具体的爬虫逻辑了,
import scrapy
import re
from myproject.items import MyprojectItem
class WeatherSpider(scrapy.Spider):
# 名称
name = "weather"
# 爬取域名的范围
allowed_domains = ["******"]
# 爬取的网址
start_urls = ["********"]
#start_urls = ["********"]
def parse(self, response, **kwargs):
data = response.xpath("//div[@class='content_l']/dl")
for each in data:
# 图片
img = each.xpath("./dt/a/img/@src").get()
# 标题
title = each.xpath("./dd/h3/a/text()").get()
# 时间
create_time = each.xpath("./dd/h3/span/text()").get()
# 简介
description = each.xpath("./dd/p/text()").get()
content_href = each.xpath("./dd/h3/a/@href").get()
# # 内容链接
# item = MyprojectItem(
# img=img,
# title=title,
# create_time=create_time,
# description=description,
# content_href=content_href
# )
#
# yield item
# 定义一个回调函数来处理每个链接的响应
yield scrapy.Request(url=content_href, callback=self.parse_content_page,
meta={'item': {'img': img, 'title': title, 'create_time': create_time,
'description': description}})
def parse_content_page(self, response):
# print(response.url)
# response.meta['item'].copy()
element = response.xpath('//div[@class="articleBody"]').get()
content = re.search(r'<div class="articleBody">(.*?)</div>', element, re.DOTALL).group(1)
# 使用正则表达式去除注释内容
content = re.sub(r'<!--.*?-->', '', content)
item_data = response.meta['item']
# print(item_data)
# 创建item并填充数据
item = MyprojectItem(
img=item_data['img'],
title=item_data['title'],
create_time=item_data['create_time'],
description=item_data['description'],
content=content # 假设这里添加了从页面中提取的内容
)
# Yield填充完毕的item
yield item