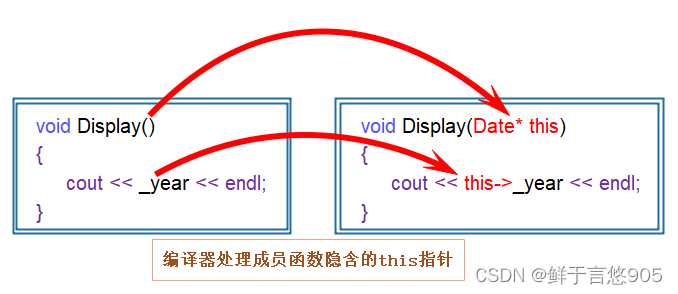
在 PyTorch 中,Tensor 对象是库的核心,用于存储数据和梯度,同时支持自动求导。
当我们讨论 PyTorch Tensor 和它的 .data 属性时,我们涉及到 PyTorch 的早期版本(特别是在 0.4.0 版本之前),那时自动求导机制和 Tensor 的表示方式与现在有所不同。
Tensor 变量
在 PyTorch 1.0 及以后的版本中,
Tensor是一个多维数组,它自带了自动求导的功能。这意味着 PyTorch 可以自动跟踪、计算和更新Tensor的梯度,这对于深度学习模型的训练是非常重要的。你可以通过设置
requires_grad标志来指定是否需要对某个Tensor求导。import torch x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)当进行操作(如加、减、乘、除等)产生新的
Tensor时,PyTorch 会自动构造计算图,这样就可以利用链式法则进行梯度的反向传播。
Tensor.data
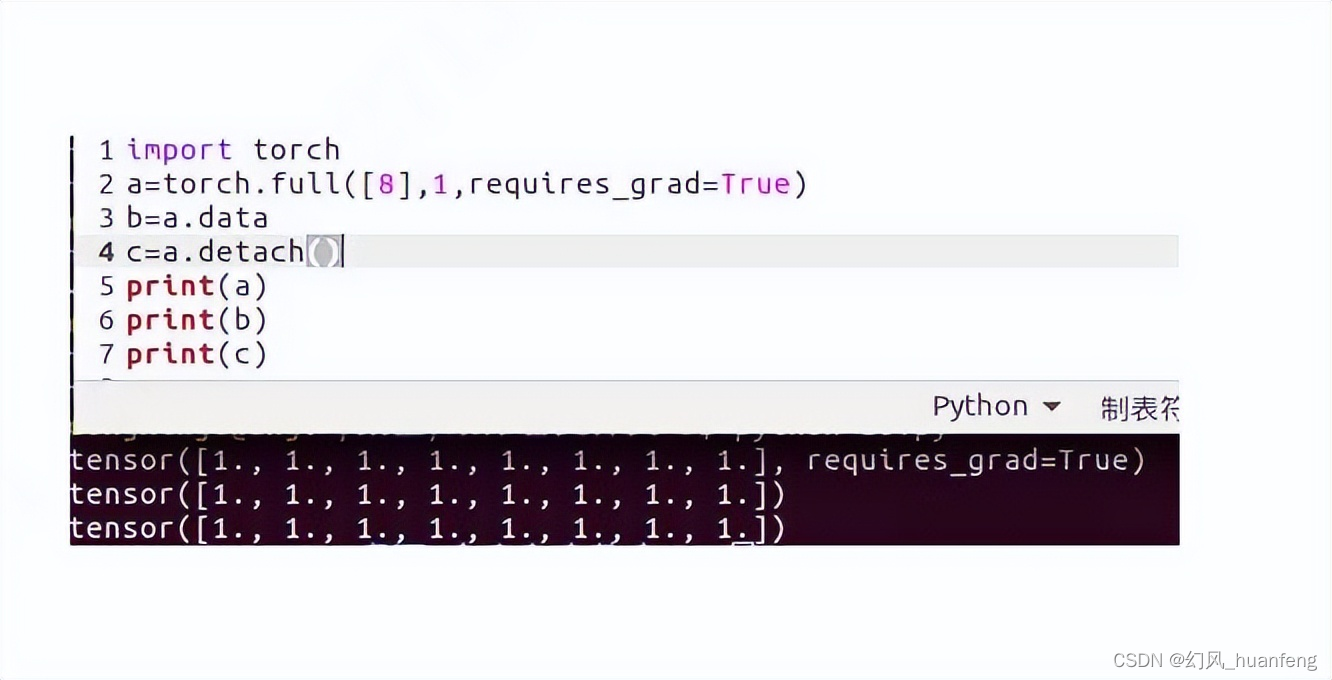
.data是一个历史遗留属性,它返回与当前Tensor相同数据的Tensor,但不会被自动求导系统追踪。这意味着,对.data的操作不会被记录在计算图中,因此不会影响梯度计算。- 在早期的 PyTorch 版本中,
.data被用来访问 Tensor 的原始数据,同时绕过自动求导,但这样做容易导致难以追踪的错误,因为计算图被“短路”了。
当前建议
避免使用
.data:从 PyTorch 0.4.0 开始,强烈建议不要再使用.data属性,因为它可能导致计算图的不正确构建,从而影响梯度的计算和模型的训练。如果你需要修改Tensor而不影响梯度计算,可以使用.detach()方法,这样可以安全地获取不需要梯度的新Tensor。y = x.detach().detach()用法:.detach()创建了一个新的Tensor,它与原始Tensor共享数据但不需要梯度。这对于实现一些需要操作梯度的Tensor但又不希望这些操作被记录(例如,权重更新)的算法非常有用。
应避免使用 .data,因为这可能会导致计算图不正确,而应该使用 .detach() 来获取不追踪梯度的 Tensor 副本,这是一种更安全和更符合当前 PyTorch 设计的做法。























![[计算机效率] 鼠标手势工具:WGestures(解放键盘的超级效率工具)](https://img-blog.csdnimg.cn/direct/363c69cac71d4a6b9b6a1dfaf80589e9.png)