一、RDD入门
1.RDD是什么?
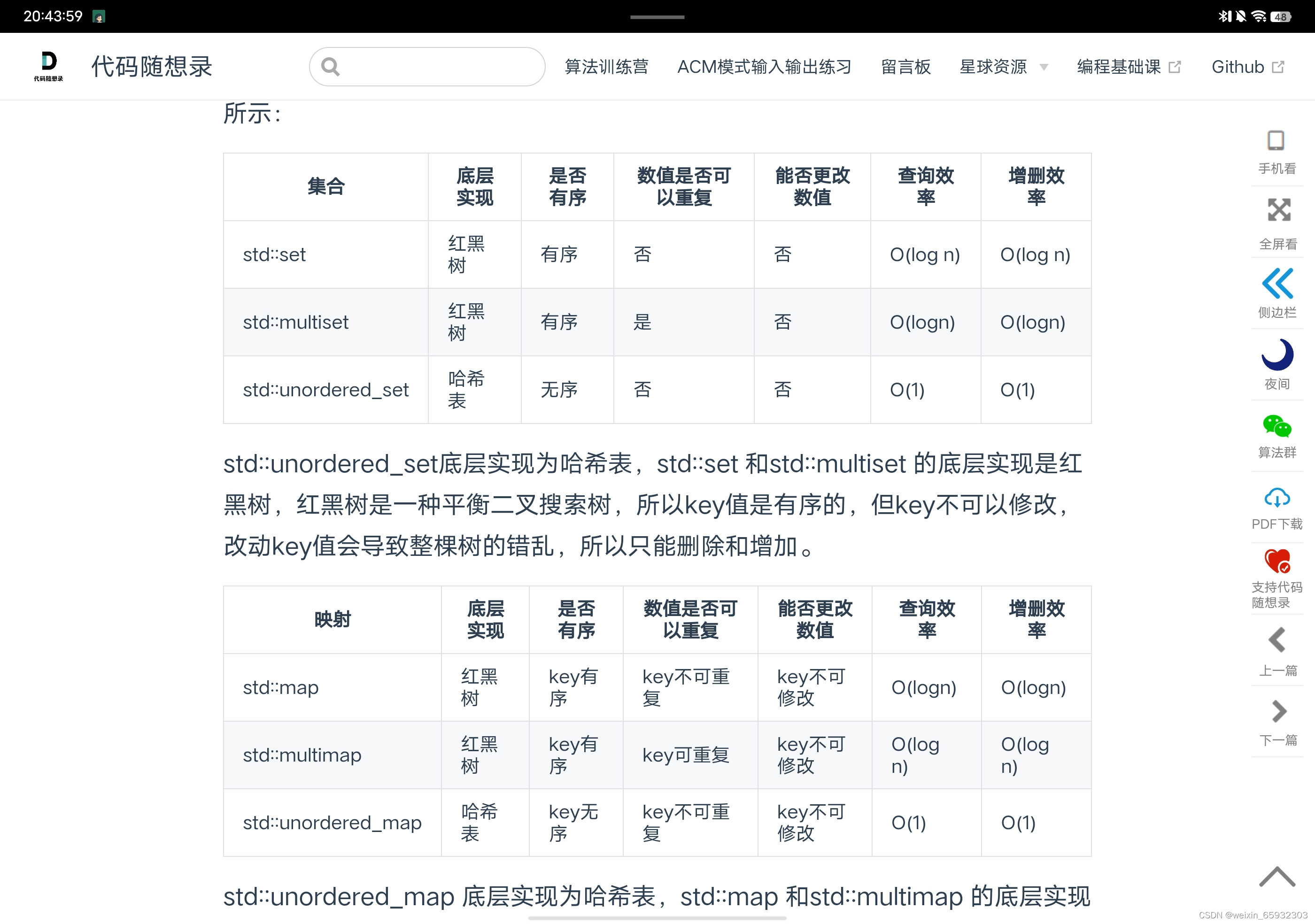
RDD是一个容错的、只读的、可进行并行操作的数据结构,是一个分布在集群各个节点中的存放元素的集合,即弹性分布式数据集。
2.RDD的三种创建方式
- 第一种是将程序中已存在的集合(如集合、列表、数组)转换成RDD。
- 第二种是读取外部数据集来创建RDD。
def main(args: Array[String]): Unit = {
//1.入口:创建SparkContext
val conf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(conf)
//2.1准备数据:将程序中已存在的集合(如集合、列表、数组)转换成RDD
val rdd1 = sc.parallelize(List(1,2,3,4))
val rdd2 = sc.makeRDD(List(1,2,3,4))
//2.2准备数据:读取外部数据集来创建RDD
val rdd3 = sc.textFile("dataset/words.txt")
//3.查看数据
rdd1.collect().foreach(println)
println("-------------------------")
rdd2.collect().foreach(println)
println("-------------------------")
rdd3.collect().foreach(println)
}- 第三种是对已有RDD进行转换得到新的RDD(在RDD的操作方法中讲解)。
二、单个RDD的转换操作
Spark RDD提供了丰富的操作方法(函数)用于操作分布式的数据集合,包括转换操作和行动操作两部分。
- 转换操作:可以将一个RDD转换为一个新的RDD,但是转换操作是懒操作,不会立刻执行计算;
- 行动操作:是用于触发转换操作的操作,这时才会真正开始进行计算。
1)map()方法
作用:把 RDD 中的数据 一对一 的转为另一种形式。
格式:def map[U: ClassTag](f: T ⇒ U): RDD[U]
Map 算子是 原RDD → 新RDD 的过程, 传入函数的参数是原 RDD 数据, 返回值是经过函数转换的新 RDD 的数据。
def main(args: Array[String]): Unit = {
//1.入口:创建SparkContext
val conf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(conf)
//2.准备数据
val rdd1 = sc.parallelize(List(1,2,3,4))
//3.RDD的转换操作map
var rdd2 = rdd1.map(x => x * 10)
//4.打印数据
rdd2.collect().foreach(println)//10 20 30 40
}2)flatMap()方法
作用:flatMap 算子和 Map 算子类似, 但是 flatMap 是一对多。
格式:def flatMap[U: ClassTag](f: T ⇒ List[U]): RDD[U]
参数是原 RDD 数据, 返回值是经过函数转换的新 RDD 的数据, 需要注意的是返回值是一个集合, 集合中的数据会被展平后再放入新的 RDD。
def main(args: Array[String]): Unit = {
//1.入口:创建SparkContext
val conf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(conf)
//2.准备数据
val rdd1 = sc.parallelize(List("How are you","I am fine","What about you"))
//3.RDD的转换操作flatMap
var rdd2 = rdd1.flatMap(x => x.split(" "))
//4.打印数据
rdd2.collect().foreach(println) //How are you I am fine What about you
}
3)sortBy()方法
作用:用于对标准RDD进行排序,有3个可输入参数。
格式:def sortBy(func, ascending, numPartitions)
参数:func指定按照哪个字段来排序,通过这个函数返回要排序的字段;scending 是否升序,默认是true,即升序排序,如果需要降序排序那么需要将参数的值设置为false。;numPartitions 分区数。
def main(args: Array[String]): Unit = {
//1.入口:创建SparkContext
val conf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(conf)
//2.准备数据
val rdd1 = sc.parallelize(List((1,3),(45,2),(7,6)))
//3.RDD的转换操作sortBy,按照元组第二个值进行false降序
val rdd2 = rdd1.sortBy(x =>x._2,false,1)
//4.打印数据
rdd2.collect().foreach(println) //(7,6) (1,3) (45,2)
}4)mapPartitionsWithIndex()方法
作用:对RDD中的每个分区(带有下标)进行操作,通过自己定义的一个函数来处理。
格式:def mapPartitionsWithIndex[U](f: (Int, Iterator[T]) => Iterator[U])
参数:f 是函数参数,接收两个参数:
(1)Int:代表分区号
(2)Iterator[T]:分区中的元素
(3)返回:Iterator[U]:操作完后,返回的结果
def main(args: Array[String]): Unit = {
//1.入口:创建SparkContext
val conf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(conf)
//2.准备数据,并设置为2个分区
val rdd1 = sc.parallelize(List(1,2,3,4,5),2)
//3.RDD的转换操作mapPartionsWithIndex
val rdd2 = rdd1.mapPartitionsWithIndex(
(index,it)=>{
it.toList.map(x=>"["+index+","+x+"]").iterator
}
)
//4.打印数据:【分区编号,数据】
rdd2.collect().foreach(println) //[0,1] [0,2] [1,3] [1,4] [1,5]
}
5)filter()方法
作用:是一种转换操作,用于过滤RDD中的元素。
格式:def filter(f: T => Boolean): RDD[T]
将返回值为true的元素保留,将返回值为false的元素过滤掉,最后返回一个存储符合过滤条件的所有元素的新RDD。
def main(args: Array[String]): Unit = {
//1.入口:创建SparkContext
val conf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(conf)
//2.准备数据
val rdd1 = sc.parallelize(List(1,2,3,4))
//3.RDD的转换操作filter,过滤偶数
val rdd2 = rdd1.filter(x => x%2==0)
//4.打印数据
rdd2.collect().foreach(println) //2 4
}
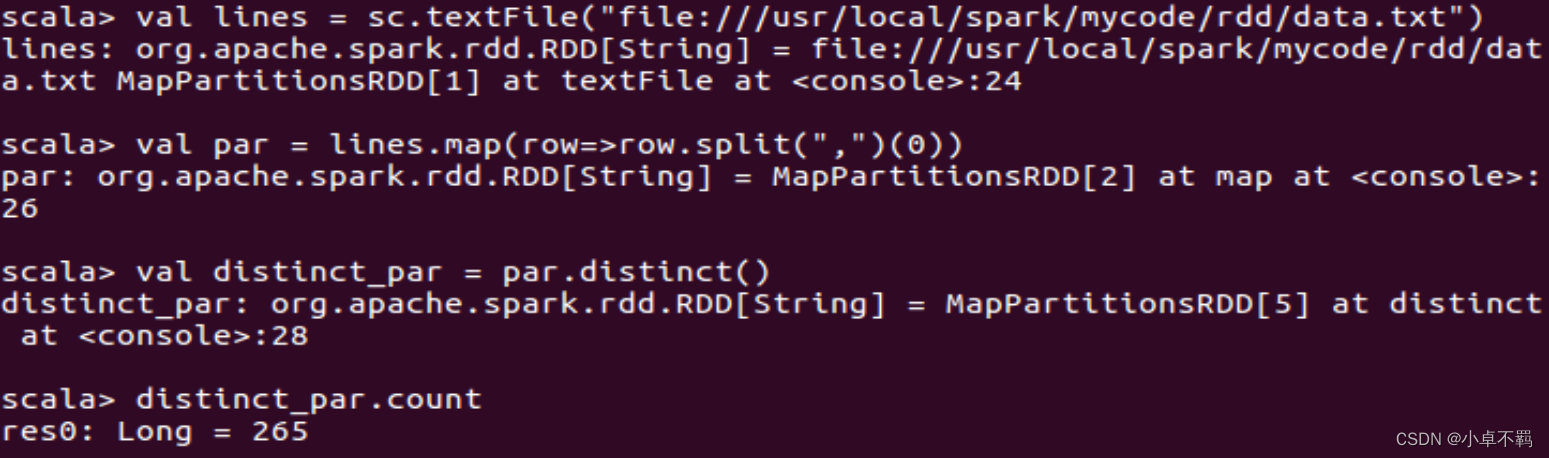
6)distinct()方法
作用:是一种转换操作,用于RDD的数据去重,去除两个完全相同的元素,没有参数。
格式:def distinct(): RDD[T]
将数据集中重复的数据去重,返回一个没有重复元素的新RDD。
def main(args: Array[String]): Unit = {
//1.入口:创建SparkContext
val conf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(conf)
//2.准备数据
val rdd1 = sc.parallelize(List(1,1,2,3,3))
//3.RDD的转换操作filter
val rdd2 = rdd1.distinct()
//4.打印数据
rdd2.collect().foreach(println) //1 2 3
}三、多个RDD的集合操作
1)union()方法
作用:是一种并集转换操作,用于将两个RDD合并成一个,不进行去重操作,而且两个RDD中每个元素中的值的数据类型需要保持一致。
格式:def union(other: RDD[T]): RDD[T]
对源 RDD 和参数 RDD 求并集后返回一个新的 RDD。
def main(args: Array[String]): Unit = {
//1.入口:创建SparkContext
val conf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(conf)
//2.准备数据
val rdd1 = sc.parallelize(List(1,2,3,4))
val rdd2 = sc.parallelize(List(1,3,5,6))
//3.RDD的转换操作union
val rdd3 = rdd1.union(rdd2)
//4.打印数据
rdd3.collect().foreach(println) //1,2,3,4,1,3,5,6
}2)intersection()方法
作用:是一种交集转换操作,用于将求出两个RDD的共同元素。
格式:def intersection(other: RDD[T]): RDD[T]
对源 RDD 和参数 RDD 求交集后返回一个新的 RDD,两个RDD的顺序不会影响结果。
def main(args: Array[String]): Unit = {
//1.入口:创建SparkContext
val conf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(conf)
//2.准备数据
val rdd1 = sc.parallelize(List(1,2,3,4))
val rdd2 = sc.parallelize(List(1,2))
//3.RDD的转换操作intersection
val rdd3 = rdd1.intersection(rdd2)
//4.打印数据
rdd3.collect().foreach(println) //1,2
}3)subtract()方法
作用:是一种补集转换操作,用于将前一个RDD中在后一个RDD出现的元素删除,返回值为前一个RDD去除与后一个RDD相同元素后的剩余值所组成的新的RDD。
格式:def subtract(other: RDD[T]): RDD[T]
将原RDD里和参数RDD里相同的元素去掉后返回一个新的 RDD,两个RDD的顺序会影响结果。
def main(args: Array[String]): Unit = {
//1.入口:创建SparkContext
val conf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(conf)
//2.准备数据
val rdd1 = sc.parallelize(List(1,2,3,4))
val rdd2 = sc.parallelize(List(1,2,5))
//3.RDD的转换操作subtract
val rdd3 = rdd1.subtract(rdd2)
val rdd4 = rdd2.subtract(rdd1)
//4.打印数据
rdd3.collect().foreach(println) //3,4
println("----------------------")
rdd4.collect().foreach(println) //5
}4)cartesian()方法
作用:是一种求笛卡儿积操作,用于将两个集合的元素两两组合成一组。
格式:def cartesian(other: RDD[T]): RDD[T]
将原RDD里的每个元素都和参数RDD里的每个组合成一组,返回一个新的RDD。两个RDD的顺序会影响结果。
def main(args: Array[String]): Unit = {
//1.入口:创建SparkContext
val conf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(conf)
//2.准备数据
val rdd1 = sc.parallelize(List(1,3,4))
val rdd2 = sc.parallelize(List(1,2))
//3.RDD的转换操作cartesian
val rdd3 = rdd1.cartesian(rdd2)
val rdd4 = rdd2.cartesian(rdd1)
//4.打印数据
rdd3.collect().foreach(println) //(1,1) (1,2) (3,1) (3,2) (4,1) (4,2)
println("----------------------")
rdd4.collect().foreach(println) //(1,1) (1,3) (1,4) (2,1) (2,3) (2,4)
}四、单个键值对RDD的转换操作
Spark的大部分RDD操作都支持所有种类的单值RDD,但是有少部分特殊的操作只能作用于键值对类型的RDD。键值对RDD由一组组的键值对组成,这些RDD被称为PairRDD。PairRDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口。
1)创建键值对RDD
1.将一个普通RDD通过map转化为Pair RDD。当需要将一个普通的RDD转化为一个PairRDD时可以使用map函数来进行操作,传递的函数需要返回键值对。
2.通过List直接创建Pair RDD。
3.使用zip()方法用于将两个RDD组成Pair RDD。要求两个及元素数量相同,否则会抛出异常。
def main(args: Array[String]): Unit = {
//1.入口:创建SparkContext
val conf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(conf)
//2.准备数据
val rdd1 = sc.parallelize(List("I like spark","He likes spark"))
//3.1 通过flatMap和map方法将一个普通的RDD转化为一个键值对RDD
val rdd2 = rdd1.flatMap(x => x.split(" "))
val rdd3 = rdd2.map(x => (x,1))
//3.2 通过List直接创建Pair RDD
val rdd4 = sc.parallelize(List(("张三",100),("李四",90),("王五",80)))
//3.3 使用zip()方法用于将两个RDD组成Pair RDD
val dataRdd1 = sc.parallelize(List(1,2,3),2)
val dataRdd2 = sc.parallelize(List("A","B","C"),2)
val dataRdd3 = dataRdd1.zip(dataRdd2)
//4.打印数据
rdd2.collect().foreach(println) //(I,like,spark,He,likes,spark)
println("---------------------")
rdd3.collect().foreach(println) //(I,1) (like,1) (spark,1) (He,1) (likes,1) (spark,1)
println("---------------------")
rdd4.collect().foreach(println) //(张三,100) (李四,90) (王五,80)
println("---------------------")
dataRdd3.collect().foreach(println) //(1,A) (2,B) (3,C)
}2)键值对RDD的keys和values方法
键值对RDD,包含键和值两个部分。 Spark提供了两种方法,分别获取键值对RDD的键和值。
- keys方法返回一个仅包含键的RDD。
- values方法返回一个仅包含值的RDD。
def main(args: Array[String]): Unit = {
//1.入口:创建SparkContext
val conf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(conf)
//2.准备数据
val rdd1 = sc.parallelize(List(("张三",100),("李四",90),("王五",80)))
//3.1 获取keys
val rdd2 = rdd1.keys
//3.2 获取values
val rdd3 = rdd1.values
//3.打印数据
rdd2.collect().foreach(println) //张三 李四 王五
println("---------------------")
rdd3.collect().foreach(println) //100 90 80
}3)键值对RDD的reduceByKey()
作用:将相同键的前两个值传给输入函数,产生一个新的返回值,新产生的返回值与RDD中相同键的下一个值组成两个元素,再传给输入函数,直到最后每个键只有一个对应的值为止。
格式:def reduceByKey(func: (V, V) => V): RDD[(K, V)]
可以将数据按照相同的 Key 对 Value 进行聚合。
def main(args: Array[String]): Unit = {
//1.入口:创建SparkContext
val conf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(conf)
//2.准备数据
val rdd1 = sc.parallelize(List("I like spark","He likes spark"))
//3.1 通过flatMap和map方法将一个普通的RDD转化为一个键值对RDD
val rdd2 = rdd1.flatMap(x => x.split(" "))
val rdd3 = rdd2.map(x => (x,1)) // (I,1) (like,1) (spark,1) (He,1) (likes,1) (spark,1)
//3.2 使用reduceByKey将相同键的值进行相加,统计词频
val rdd4 = rdd3.reduceByKey((a,b) => a+b)
//4.打印数据
rdd4.collect().foreach(println) //(I,1) (He,1) (spark,2) (like,1) (likes,1)
}3)键值对RDD的groupByKey()
作用:按照 Key 分组, 和 reduceByKey 有点类似, 但是 groupByKey 并不求聚合,只是列举 Key 对应的所有 Value。
格式:def groupByKey(): RDD[(K, Iterable[V])]
对于一个由类型K的键和类型V的值组成的RDD,通过groupByKey()方法得到的RDD类型是[K,Iterable[V]],可以将数据源的数据根据 key 对 value 进行分组。
def main(args: Array[String]): Unit = {
//1.入口:创建SparkContext
val conf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(conf)
//2.准备数据
val rdd1 = sc.parallelize(List(("a",1),("a",2),("b",1),("c",1),("c",1)))
//3.使用groupByKey进行分组
val rdd2 = rdd1.groupByKey()
//4.使用map方法查看分组后每个分组中的值的数量
val rdd3 = rdd2.map(x => (x._1,x._2.size))
//5.打印数据
rdd2.collect().foreach(println) //(a,CompactBuffer(1, 2)) (b,CompactBuffer(1)) (c,CompactBuffer(1, 1))
rdd3.collect().foreach(println) //(a,2) (b,1) (c,2)
}五、多个键值对RDD的转换操作
在Spark中,键值对RDD提供了很多基于多个RDD的键进行操作的方法。
1)join()方法
作用:用于根据键,对两个RDD进行内连接,将两个RDD中键相同的数据的值存放在一个元组中,最后只返回两个RDD中都存在的键的连接结果。
格式:def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
在类型为(K,V)和(K,W)的 RDD 上调用,返回一个相同 key 对应的所有元素连接在一起的。
def main(args: Array[String]): Unit = {
//1.入口:创建SparkContext
val conf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(conf)
//2.准备数据
val rdd1 = sc.parallelize(List(("a",1),("b",2),("c",3)))
val rdd2 = sc.parallelize(List(("a",2),("b",4),("e",5)))
//3.使用join进行内连接
val rdd3 = rdd1.join(rdd2)
//4.打印数据
rdd3.collect().foreach(println) //(a,(1,2)) (b,(2,4))
}2)rightOuterJoin()方法
作用:用于根据键,对两个RDD进行右外连接,连接结果是右边RDD的所有键的连接结果,不管这些键在左边RDD中是否存在。
格式:def rightOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
类似于 SQL 语句的右外连接。如果在左边RDD中有对应的键,那么连接结果中值显示为Some类型值;如果没有,那么显示为None值。
3)leftOuterJoin()方法
作用:用于根据键,对两个RDD进行左外连接,连接结果是左边RDD的所有键的连接结果,不管这些键在右边RDD中是否存在。
格式:def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
类似于 SQL 语句的右外连接。如果在右边RDD中有对应的键,那么连接结果中值显示为Some类型值;如果没有,那么显示为None值。
4)fullOuterJoin()方法
作用:用于对两个RDD进行全外连接,保留两个RDD中所有键的连接结果。
格式:def fullOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
类似于 SQL 语句的全外连接。
def main(args: Array[String]): Unit = {
//1.入口:创建SparkContext
val conf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(conf)
//2.准备数据
val rdd1 = sc.parallelize(List(("a",1),("b",2),("c",3)))
val rdd2 = sc.parallelize(List(("a",2),("b",4),("e",5)))
//3.使用rightOuterJoin进行右外连接
val rdd3 = rdd1.rightOuterJoin(rdd2)
//4.使用leftOuterJoin进行左外连接
val rdd4 = rdd1.leftOuterJoin(rdd2)
//5.使用fullOuterJoin进行全外连接
val rdd5 = rdd1.fullOuterJoin(rdd2)
//6.打印数据
rdd3.collect().foreach(println) //(a,(Some(1),2)) (b,(Some(2),4)) (e,(None,5))
println("--------------------")
rdd4.collect().foreach(println) //(a,(1,Some(2))) (b,(2,Some(4))) (c,(3,None))
println("--------------------")
rdd5.collect().foreach(println) //(a,(Some(1),Some(2))) (b,(Some(2),Some(4))) (c,(Some(3),None)) (e,(None,Some(5)))
}5)sortByKey()方法
作用:作用于Key-Value形式的RDD,并对Key进行排序。
格式:def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
: RDD[(K, V)]
参数:scending 是否升序,默认是true,即升序排序,如果需要降序排序那么需要将参数的值设置为false。numPartitions 为分区数。
def main(args: Array[String]): Unit = {
//1.入口:创建SparkContext
val conf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(conf)
//2.准备数据
val rdd1 = sc.parallelize(List((1,3),(45,2),(7,6)))
//3.RDD的转换操作sortByKey
val rdd2 = rdd1.sortByKey(true) //按key进行升序
val rdd3 = rdd1.sortByKey(false) //按key进行降序
//4.打印数据
rdd2.collect().foreach(println)
println("---------------------")
rdd3.collect().foreach(println)
}6)lookup()方法
作用:作用于键值对RDD,返回指定键的所有值。
格式:def lookup(key : K) : scala.Seq[V]
作用于K-V类型的RDD上,返回指定K的所有V值
def main(args: Array[String]): Unit = {
//1.入口:创建SparkContext
val conf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(conf)
//2.准备数据
val rdd1 = sc.parallelize(List(("张三",100),("李四",90),("王五",80)))
//3.使用lookup()方法查找指定键的值
val result = rdd1.lookup("李四")
//4.打印数据
println(result) //WrappedArray(90)
}7)combineByKey()方法
作用:用于将键相同的数据聚合,并且允许返回,类型与输入数据的类型不同的返回值。
格式:def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C): RDD[(K, C)]
combineByKey()方法接收3个重要的参数,具体说明如下:
- createCombiner:V=>C,V是键值对RDD中的值部分,将该值转换为另一种类型的值C,C会作为每一个键的累加器的初始值。
- mergeValue:(C,V)=>C,该函数将元素V聚合到之前的元素C(createCombiner)上(这个操作在每个分区内进行)。
- mergeCombiners:(C,C)=>C,该函数将两个元素C进行合并(这个操作在不同分区间进行)。
小练习:将数据 List(("zhangsan", 99.0), ("zhangsan", 96.0), ("lisi", 97.0), ("lisi", 98.0), ("zhangsan", 97.0)),求每个 key的平均值。
def main(args: Array[String]): Unit = {
//1.入口:创建SparkContext
val conf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(conf)
//需求:将数据 List(("zhangsan", 99.0), ("zhangsan", 96.0), ("lisi", 97.0), ("lisi", 98.0), ("zhangsan", 97.0)),求每个 key的平均值
//2.准备数据
val rdd1 = sc.parallelize(List(("zhangsan", 99.0), ("zhangsan", 96.0), ("lisi", 97.0), ("lisi", 98.0), ("zhangsan", 97.0)))
//3.1 通过combineByKey方法将RDD安装key进行聚合,返回值形式:(key,(值总和,key个数))
val rdd2 = rdd1.combineByKey(
score => (score,1),
(scoreCount:(Double,Int),newScore:Double) => (scoreCount._1+newScore,scoreCount._2+1),
(scoreCount1:(Double,Int),scoreCount2:(Double,Int)) => (scoreCount1._1+scoreCount2._1,scoreCount1._2+scoreCount2._2)
)
//打印combineByKey聚合之后的数据,形式:(key,(值总和,key个数))
rdd2.collect().foreach(println) //(zhangsan,(292.0,3)) (lisi,(195.0,2))
//3.2 将按值聚合相加后的结果(zhangsan,(292.0,3)) (lisi,(195.0,2)),求每个人的平均值,返回值形式:(key,平均值)
val result = rdd2.map(item =>(item._1,item._2._1/item._2._2))
//4 打印数据
println("------------------")
result.collect().foreach(println)
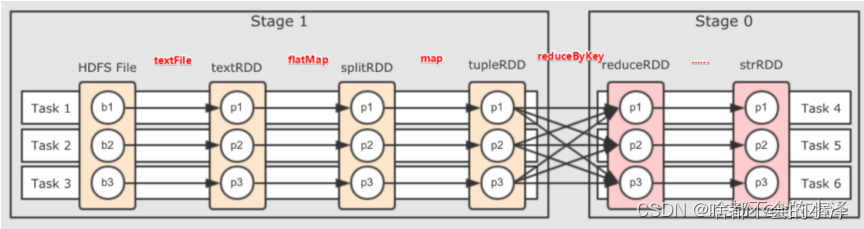
}combineByKey()方法执行过程的图解:


































![[react] useState的一些小细节](https://img-blog.csdnimg.cn/direct/7b52213b542148e3af114c73b05da338.png)