什么时候使用哈希法:当我们需要查询一个元素是否出现过,或者一个元素是否在集合里的时候,就要第一时间想到哈希法
1 数组,适用于范围不大的情况,直接用下标存数据。
2 set,适用于范围很大的情况,比如就3个数,但是是0,5,100万,这种时候用数组显然太不合理。set详解
3 map目的用来存放我们访问过的元素,因为遍历数组的时候,需要记录我们之前遍历过哪些元素和对应的下标,一般是key为下标,value存值map<int,int>m(key,value)。map详解
***************************************************
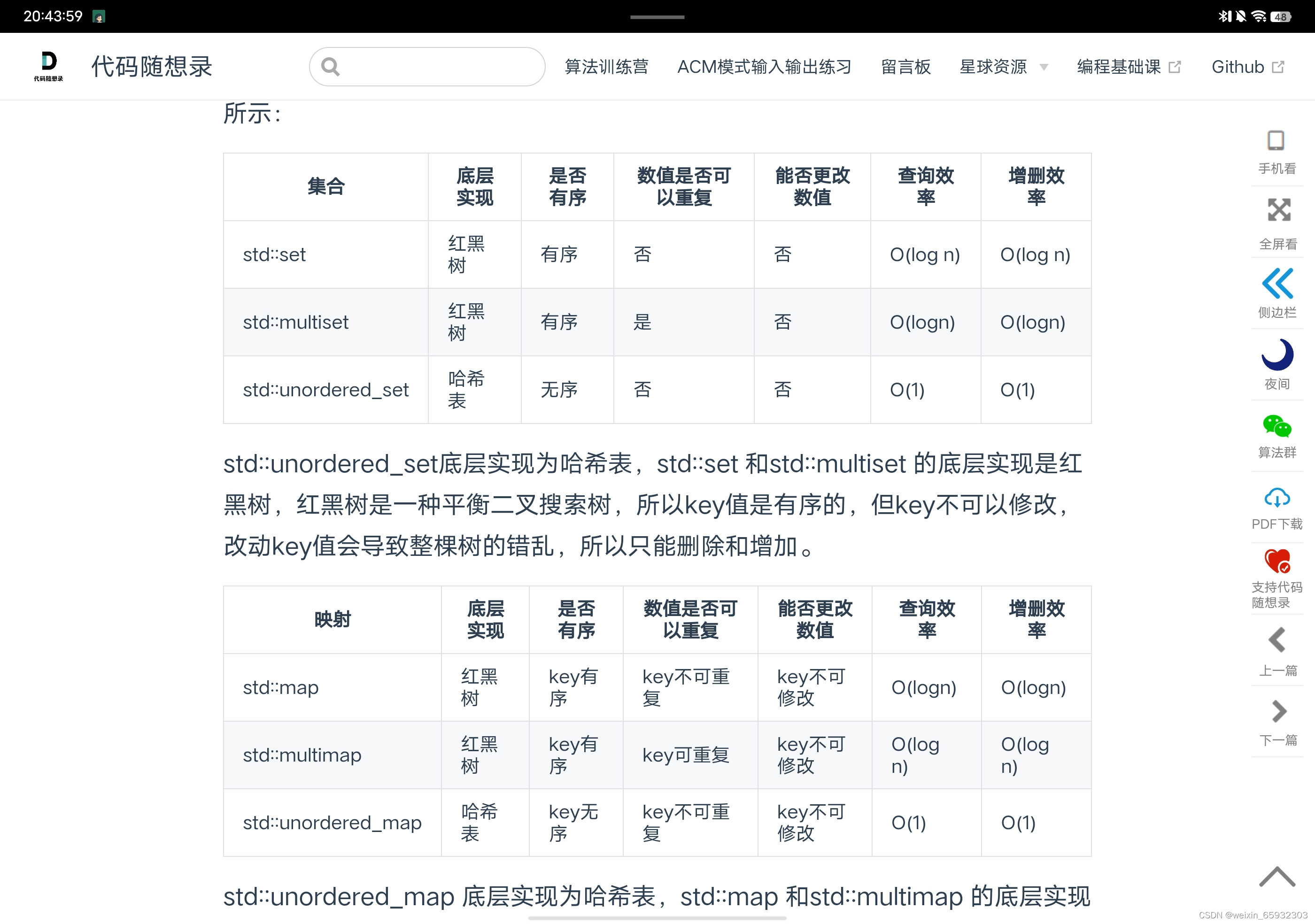
底层实现为红黑树时,当有新的数据插入数组时,会被自动排序,因为红黑树就是用来排序的。所以如果使用哈希表用不到排序时,选unordered即可,效率更高。
*********************************************************************
方法一:数组
class Solution {
public:
bool canConstruct(string ransomNote, string magazine) {
char mag[26]={0};
for(int i=0;i<magazine.size();i++){
mag[magazine[i]-'a']++;//将magazine中有的字母都存入mag中
}
for(int i=0;i<ransomNote.size();i++){
mag[ransomNote[i]-'a']--;//将mag中字母减去ransomNote中的字母
}
for(int i=0;i<26;i++){
if(mag[i]<0)
return false;
}
return true;
}
};方法二:map
map的key用来存放字母,value来存放字母出现次数
class Solution {
public:
bool canConstruct(string ransomNote, string magazine)
{
unordered_map<char,int>map;//key用来存放字母,value来存放字母出现次数
for(char a:magazine)
map[a]++;
for(char b:ransomNote)
{
if(map[b]==0)//map(key)没有找到和ransomNote相同的元素
return false;
else if(map[b]>0)//map(key)找到和ransomNote相同中的元素
map[b]--;
}
return true;
}
};*****************************************************************************
leetcode349. 两个数组的交集
方法一:数组
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> result_set; // 存放结果,之所以用set是为了给结果集去重
int hash[1005] = {0}; // 默认数值为0
for (int num : nums1) { // nums1中出现的字母在hash数组中做记录
hash[num] = 1;
}
for (int num : nums2) { // nums2中出现话,result记录
if (hash[num] == 1) {
result_set.insert(num);
}
}
return vector<int>(result_set.begin(), result_set.end());
}
};在函数的返回语句中,可以直接返回一个临时创建的vector容器,而不需要显式地定义一个变量来存储。这行代码的作用是将result_set中的元素复制到一个新的vector容器中,并将该容器作为函数的返回值返回。这种写法在需要快速返回一个临时vector容器时很常见。
return vector<int>(result_set.begin(), result_set.end());
/* 这两段代码意思相同 */
vector<int> vc (result_set.begin(), result_set.end());
return vc;方法二:set
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> result_set; // 存放结果,之所以用set是为了给结果集去重
unordered_set<int> nums_set(nums1.begin(), nums1.end());
for (int num : nums2) {//循环遍历nums2中的元素
// 如果发现nums2的元素 在nums_set里又出现过
if (nums_set.find(num) != nums_set.end()) {
result_set.insert(num);
}
}
return vector<int>(result_set.begin(), result_set.end());
//此函数是vector类型,所以需要将set容器转换成再返回
}
};
等价于:
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> result_set; // 存放结果,之所以用set是为了给结果集去重
for (int num : nums2) {
auto it=find(nums1.begin(),nums1.end(),num);
if (it != nums1.end()) {//如果发现nums2的元素 在nums_set里又出现过
result_set.insert(num);
}
}
return vector<int>(result_set.begin(), result_set.end());
}
};对于vector容器,可以使用find()算法来在容器中线性查找特定元素,find()返回一个迭代器指向找到的元素,如果没找到则返回容器末尾的迭代器。vector容器的find()用法
而对于set容器,它是一种关联容器,内部使用红黑树实现,元素是有序的并且唯一的。因此,set提供了自己的成员函数find()用于在集合中查找元素,find()函数返回一个迭代器指向找到的元素,如果没找到则返回set.end()。
所以在使用vector时,建议使用find()算法进行元素查找;而在使用set时,直接使用find()成员函数是更高效和便捷的方式。
比如:在vector中
#include<vector>
#include<algorithm>
vector<int> v1;
if(find(v1.begin(),v1.end(),5)!=v.end())//查找v1中是否存在5
而在set中
#include<set>
unordered_set<int>s1;
if (s1.find(5) != s1.end())//查找s1中是否存在5
*/*************************************************************************
set
class Solution {
public:
int getsum(int num){
int sum=0;
while(num>0){
sum+=(num%10)*(num%10);
num/=10;
}
return sum;//返回每个位置上的数字的平方和
}
bool isHappy(int n) {
unordered_set<int>s;
while(1){
int sum=getsum(n);
if(sum==1){
return true;
}
else if(s.find(sum)!=s.end()){//如果此处成立,则说明遇到了重复的sum
return false;
}
s.insert(sum);
n=sum;
}
}
};*****************************************************************************
map:
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target)
{
//一般是key为下标,value存值,本题之所以反过来,是因为调用find(key)即find(nums[i]),
//这样才能判断查找是否是想要的值
unordered_map<int,int>map;
for(int i=0;i<nums.size();i++)//i代表下标,即value
{
//unordered_map<int,int>::interator it;
auto it=map.find(target-nums[i]);
//查找key值,因为target=当前循环nums【i】+target-当前循环nums【i】
if(it!=map.end())//如果it存在
return {it->second,i};
//it->second表示map(key,value)中的value值,由于本题将key与value的顺序交换,
//所以返回的时key值,即数组下标;i表示以及当前循环到的另一个数组的下标
map.insert(pair<int,int>(nums[i],i));
//pair是结构体,有first和second,分别对应nums[i]和i
}
return {};
}
};
/* 在map容器中,当使用insert()函数插入数据
1: myMap.insert(std::pair<int, std::string>(1, "apple"));
2: myMap.insert(std::make_pair(2, "banana"));
*/************************************************************************************
tips:
for (int num : nums1) {
cout << num << " ";
}
在这个示例中,循环会遍历nums1中的每个元素,并将元素的值打印输。与下面的代码效果相同
for(int i=0;i<nums1.size();i++){
num=nums1[i];
cout<<num<<" ";
}*******************************************************************
vector<int>::iterator it与auto it效果一样



![<span style='color:red;'>代码</span>随想录算法训练营第五天:<span style='color:red;'>哈</span><span style='color:red;'>希</span><span style='color:red;'>表</span><span style='color:red;'>的</span>初步认识[1]](https://img-blog.csdnimg.cn/img_convert/5ef59ee727c11507da78c5fb19fdc2a4.gif)