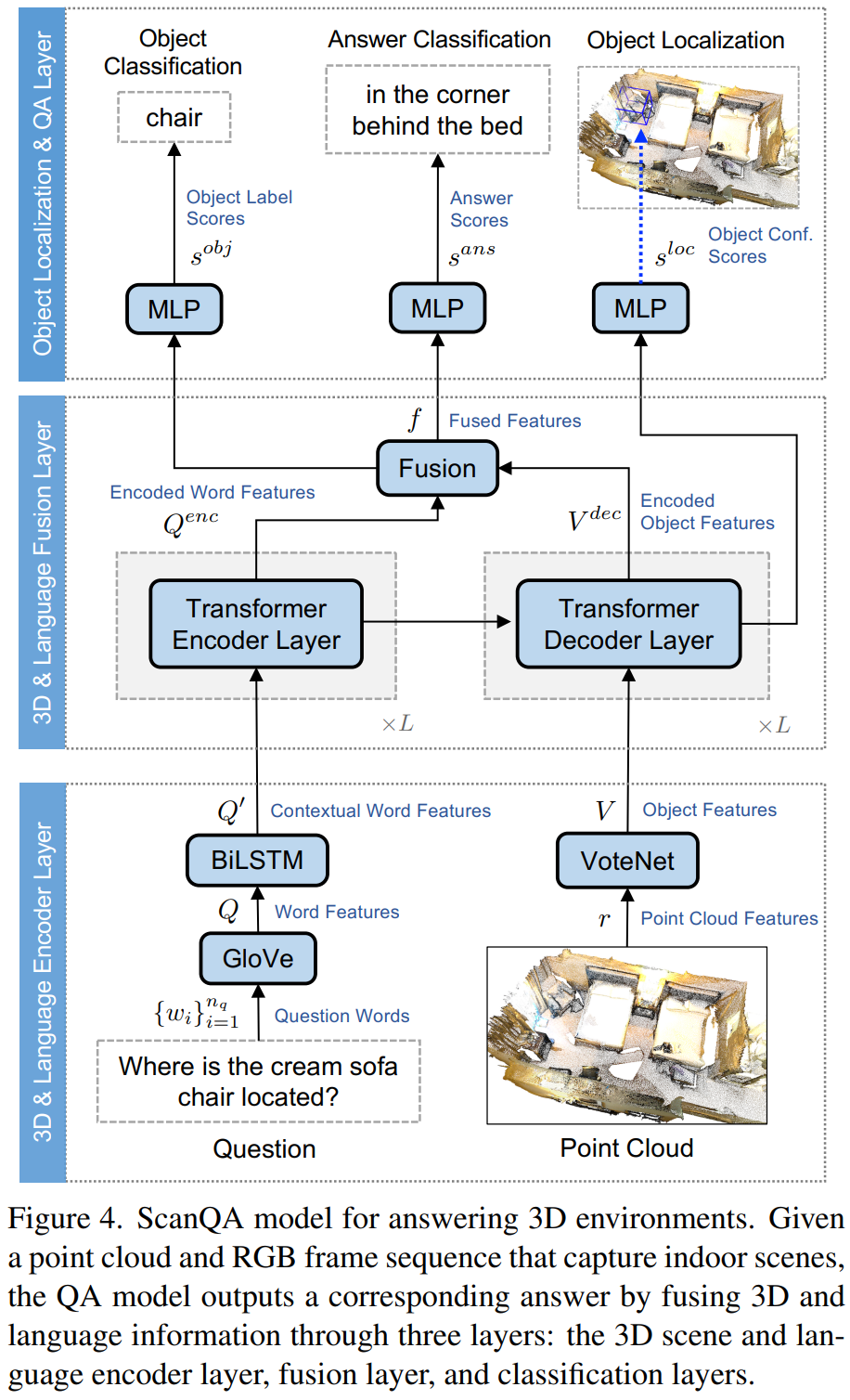
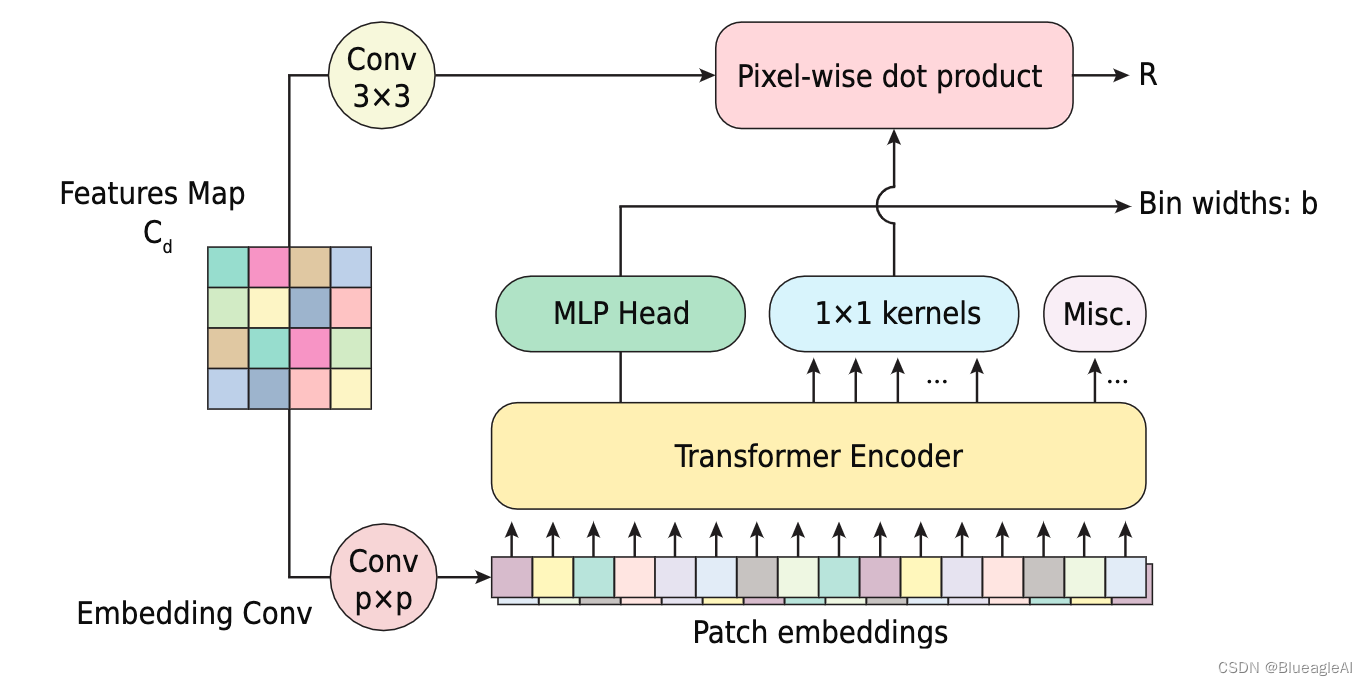
AdaBins的第一个模块是miniViT.输出:1) 向量 b , 定义了它如何将深度区间D划分为输入图像。2)Range-Attention 图 R \mathcal{R} R,形状是 h × w × C h \times w \times C h×w×C, 包含了像素级深度计算信息。
Bin-widths: 使用MLP头和ReLU层输出N维(bin的数量)向量b’。最后通过Softmax归一化b‘。 b i = b i ′ + ϵ ∑ j = 1 N ( b j ′ + ϵ ) b_i = \frac{b'_i + \epsilon}{\sum^N_{j=1}(b'_j + \epsilon)} bi=∑j=1N(bj′+ϵ)bi′+ϵ
Range attention maps: Transformer中包含了更多的全局信息。来自转换器的output embedding (2,C+1)作用一组1x1的卷积核,并与解码器的特征卷积获得 R \mathcal{R} R。这相当于将pixel-wise 特征视为’keys’, transformer output embedding相当于’queries’。
Hybrid regression: R \mathcal{R} R 通过 1 × 1 卷积层获得 N 个通道,然后通过 Softmax。每个像素每个通道的数值作为这个bin的概率,每个depth-bin-centers可以算为: c ( b i ) = d ( m i n ) + ( d m a x − d m i n ) ( b i / 2 + ∑ j = 1 i + 1 b j ) c(b_i) = d_(min) + (d_{max} - d_{min})(b_i/2 + \sum^{i+1}_{j=1}b_j) c(bi)=d(min)+(dmax−dmin)(bi/2+∑j=1i+1bj) 最后,对于每一个pixel, 最终的 d ~ \tilde{d} d~计算为线性组合 c ( b i ) c(b_i) c(bi), d ~ = ∑ k = 1 N c ( b k ) p k \tilde{d}= \sum^N_{k=1}c(b_k)p_k d~=∑k=1Nc(bk)pk。
Loss function
Pixel-wise depth loss. 使用一个尺度不变损失 (SI) 的缩放版本:
g i = l o g d ~ i − l o g d i g_i = log \tilde{d}_i - log d_i gi=logd~i−logdi。
Bin-center density loss: 鼓励bin centers的分布与真实标签相同。我们将 bin 中心的集合表示为 c(b),将地面实况图像中所有深度值的集合表示为 X,并使用双向倒角损失 [9] 作为正则化器:
Reference
[1]FU H, GONG M, WANG C, et al. Deep Ordinal Regression Network for Monocular Depth Estimation[C/OL]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT. 2018. http://dx.doi.org/10.1109/cvpr.2018.00214. DOI:10.1109/cvpr.2018.00214.
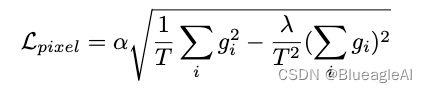
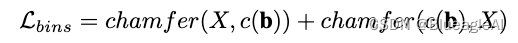



![[<span style='color:red;'>论文</span><span style='color:red;'>阅读</span>]DETR](https://img-blog.csdnimg.cn/direct/e8df1ed8695749d1b661ff6ad6833838.png)
![[<span style='color:red;'>论文</span><span style='color:red;'>阅读</span>]BEVFusion](https://img-blog.csdnimg.cn/direct/65697d2df3dc47d2a67baf3c2e53c330.png)