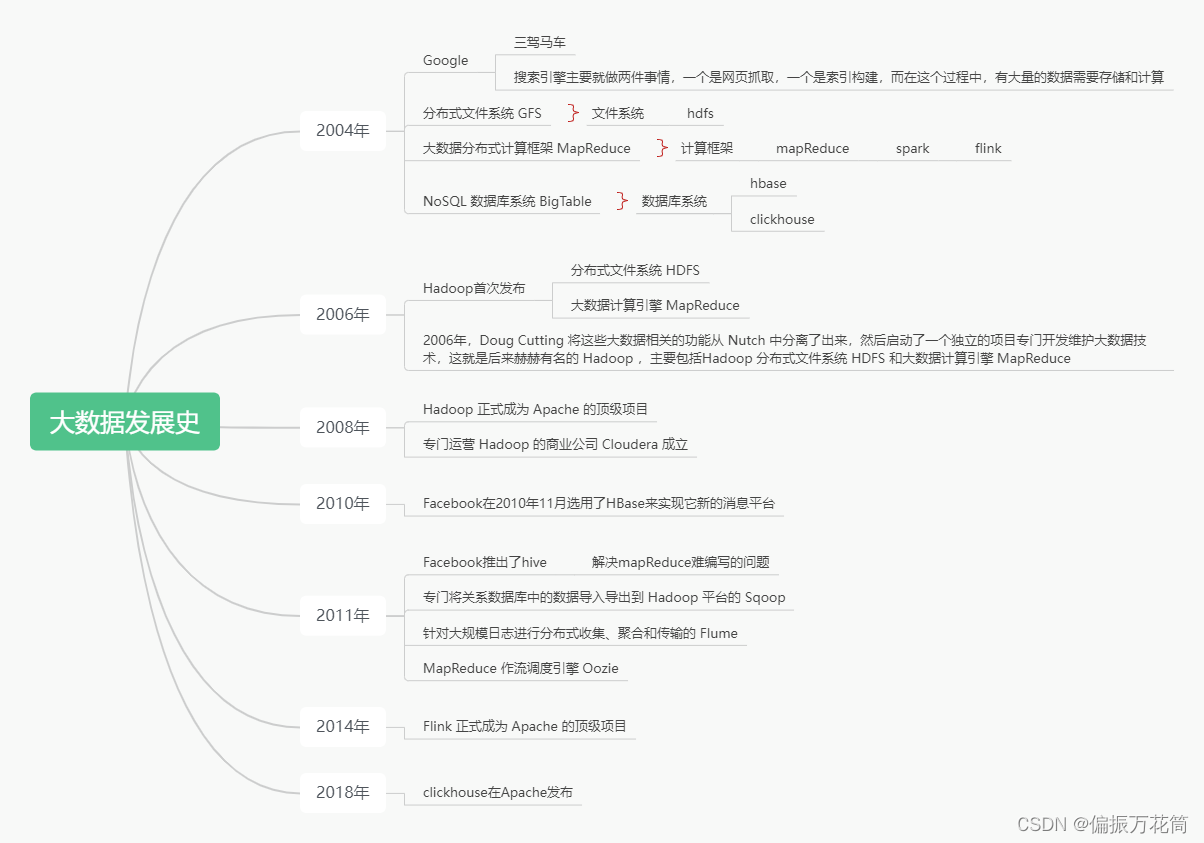
第一章 大数据行业与技术趋势
- 大数据4v特征:volume大量化、velocity快速化、variety多样化、value价值化
- Volume大量化指的是数据量的增加,特别是在大数据领域中,指的是海量的数据量。
- Velocity快速化指的是数据的产生、传输和处理速度的加快,特别是在实时数据处理和分析领域中。
- Variety多样化指的是数据的类型和格式的多样性,包括结构化数据、半结构化数据和非结构化数据等。
- Value价值化指的是通过对大数据的分析和挖掘,将数据转化为有用的信息和知识,为企业和组织创造价值。
- 大数据与云计算、物联网的关系
- 云计算、大数据和物联网代表了IT领域最新的技术发展趋势,三者相辅相成,既有联系又有区别。
- 云计算为大数据提供了技术基础;大数据为云计算提供用武之地。
- 云计算为物联网提供海量数据存储能力;物联网为云计算技术提供了广阔的应用空间。
- 物联网是大数据的重要来源;大数据技术为物联网数据分析提供支撑。
- 大数据的影响:
- 思维方式方面:大数据完全颠覆了传统的思维方式(全样而非抽样、效率而非精确、相关而非因果)。
- 社会发展方面:大数据决策逐渐成为一种新的决策方式,大数据应用有力促进了信息技术与各行业的深度融合,大数据开发大大推动了新技术和新应用的不断涌现。
- 就业市场方面:大数据的兴起使得数据科学家成为热门职业。
- 人才培养方面:大数据的兴起将在很大程度上改变中国高校信息技术相关专业的现有教学。
- 大数据的两大核心技术
- 分布式存储:GFS/HDFS、BigTable/HBase、NoSQL
- 分布式处理:MapReduce
- 大数据计算模式及代表产品
- 批处理计算:针对大规模数据的批量处理。MapReduce、Spark。
- 流计算:针对流数据的实时计算。Storm、S4、Flume、Streams、Puma、DStream、SuperMario、银河流数据处理平台。
- 图计算:针对大规模图结构数据的处理。Pregel、GraphX、Giraph、PowerGraph、Hama、GoldenOrb。
- 查询分析计算:大规模数据的存储管理和查询分析。Dremel、Hive、Cassandra、Impala。
第二章 分布式文件系统
一、Zookeeper
- zookeeper的定义:在Hadoop中,Zookeeper是一个开源的分布式协调服务,它提供了一个高可用的分布式环境,用于协调和管理Hadoop集群中的各种服务和组件。Zookeeper负责管理集群中各个节点的状态信息、配置信息、元数据等,以确保Hadoop集群的稳定性和一致性。它还可以用于协调Hadoop集群中不同组件之间的通信和同步操作。Zookeeper在Hadoop中扮演着非常重要的角色,帮助Hadoop集群实现高可用性、一致性和可靠性。
- zookeeper的特点:分布式协调服务、 高可用性、一致性、可靠性、用途广泛、等待无关性、顺序一致性、原子性、等待无关性。
- 分布式协调服务:Zookeeper提供了一个分布式环境,用于协调和管理Hadoop集群中的各种服务和组件,确保集群中各个节点的状态信息、配置信息、元数据等的一致性和稳定性。
- 高可用性:Zookeeper设计为能够在集群中容忍节点的故障,保证服务的高可用性,即使部分节点出现故障,集群依然可以正常运行。
- 一致性:(无论哪个sercer,对外展示的均是同一视图 )Zookeeper采用了分布式一致性协议,确保在分布式环境下各个节点之间的数据一致性,能够提供强一致性的服务。
- 可靠性:(一条消息被一个server接收,将被所有的server接受)Zookeeper具有较高的可靠性,能够处理各种复杂的分布式系统中的问题,确保集群的稳定性和可靠性。
- 用途广泛:除了在Hadoop中用于协调和管理集群,Zookeeper还可以用于其他分布式系统中,如Kafka、HBase等,具有较强的通用性和灵活性。
- 等待无关性:慢的或者失效的client不会干预快速的client的请求,使得每个client都能有效等待。
- 原子性:只有两种状态,成功或者失败,没有中间状态
- 顺序一致性:客户端发送的更新会按照他们被发送的顺序进行应用,先写的先读
- 分布式协调服务:Zookeeper提供了一个分布式环境,用于协调和管理Hadoop集群中的各种服务和组件,确保集群中各个节点的状态信息、配置信息、元数据等的一致性和稳定性。
- zookeeper的应用:协调和管理Hadoop集群、高可用性的选举机制、分布式配置管理、分布式锁服务、监控和通知。
- 体系架构
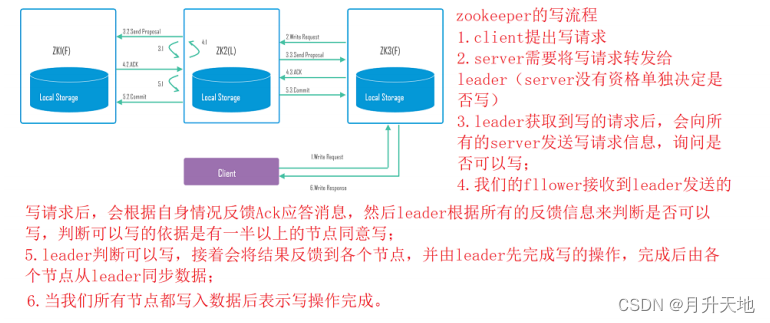
- Leader节点在接收到数据变更请求后,先写磁盘再写内存。
- zookeeper读特性:由ZooKeeper的一致性可知,客户端无论连接哪个server,获取的均是同一个视图。所以,读操作可以在客户端与任意节点间完成
- 容灾能力
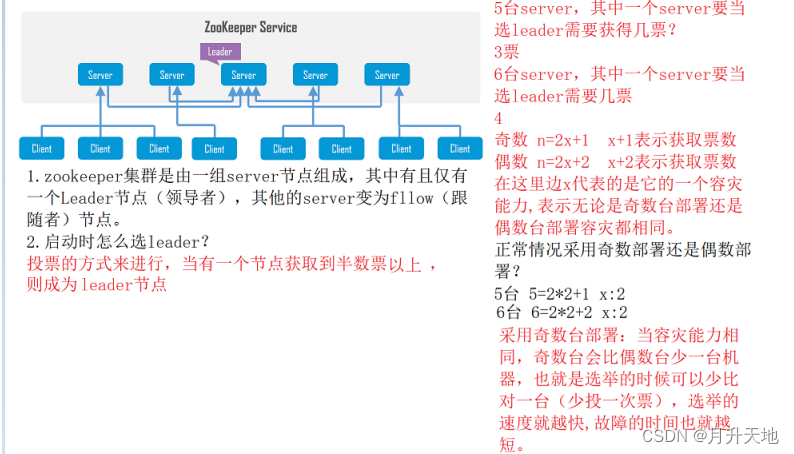
- zookeeper选举,当某一个节点获得半数票以上则变更为主leader
- ZXID:启动顺序
- z1 z2 z3 z4 z5
- MXID:事务状态值
- 最新的数据状态的节点作为主,谁权重高投给谁
- ZXID:启动顺序
- zookeeper选举,当某一个节点获得半数票以上则变更为主leader
- 部署要求
- 三个以上奇数部署
- 半数个以上节点存货时才认为zookeeper集群可用
- 对于n个实例部署
- 当n为奇数,假定n =2x+1,称为leader需要获得x+1票,容灾能力为x
- 当n为偶数,假定n =2x+2,称为leader需要获得x+2票(大于一半),容灾能力为x
- zookeeper写特性
二、Hadoop
- Hadoop的定义:Hadoop是一个开源的分布式计算框架,它能够在集群环境下高效地存储、处理、分析大规模数据。其核心组件是Hadoop分布式文件系统(HDFS)和MapReduce计算框架,它们都是为了应对处理PB级别以上的数据规模而设计的。Hadoop不仅支持海量数据的存储和处理,还能通过扩展的方式支持各种数据格式和编程语言。Hadoop的应用范围广泛,包括搜索引擎、社交网络、电子商务、金融等领域。
- Hadoop特点:分布式存储和处理、可伸缩性、 容错性高、适应多种数据类型和处理方式、 开放的生态系统。
- 分布式存储和处理:Hadoop采用分布式存储和处理的方式,即数据和计算任务都分布在集群的多个节点上。这种方式可以实现磁盘空间和处理能力的横向扩展,从而有效地应对海量数据的存储和计算。
- 可伸缩性:由于Hadoop采用分布式架构,因此可以随着数据量的增长而线性地扩展集群规模,从而提高处理性能和完成任务的速度。
- 容错性高:Hadoop在设计之初就考虑到了节点故障的问题,并采用了多层次的容错策略,如数据的备份和任务重试等,保证数据的可靠性和计算的正确性。
- 适应多种数据类型和处理方式:Hadoop不仅支持处理结构化数据,还可以处理半结构化和非结构化数据。同时,Hadoop也支持多种处理方式,如MapReduce、SQL查询、流处理等。
- 开放的生态系统:Hadoop拥有一个庞大的生态系统,包含了丰富的数据存储和数据处理工具。同时,Hadoop也支持集成其他开源工具和框架,如Spark、Hive、Pig等。
- Hadoop的应用:大数据处理、日志分析、社交网络分析、生物信息学、金融分析。
- 大数据处理:Hadoop最初设计的目的是为了解决大规模数据的存储和计算问题,因此它在大数据处理方面有着得天独厚的优势。例如,Hadoop可以用于海量数据的ETL(抽取、转换、加载)、数据仓库、数据挖掘等方面。
- 日志分析:随着互联网技术的发展,数据产生的速度越来越快,各种应用系统产生的日志数据也越来越多。Hadoop可以对这些日志数据进行采集、处理和分析,从而为系统管理、运营优化和安全监控提供支持。
- 社交网络分析:社交网络平台如Facebook、Twitter等都会产生大量的用户数据,Hadoop可以用来对这些数据进行处理和分析,例如用户行为分析、社交网络的建模、推荐算法等。
- 生物信息学:生物信息学是一个复杂的领域,需要对大量的基因组和序列数据进行分析。Hadoop可以用来加速这个过程,例如基因组比对、序列建模、药物研究等。
- 金融分析:银行、保险公司等金融机构每天生成海量的数据,这些数据可以用来进行风险评估、货币政策的制定、信用评估等方面的分析。Hadoop可以帮助金融机构快速处理这些数据,并提供准确的预测和建议。
三、hdfs
- hdfs定义:HDFS(Hadoop Distributed File System)是Hadoop生态系统中的一部分,是一种分布式文件系统,主要用于存储大规模数据集的文件。它被设计成能够运行在大量的廉价硬件上,并且具有高可靠性、高容错性和高吞吐量等特点。 HDFS适用于海量数据的批量读写,不适用与低延迟数据操作。
HDFS是一个主次架构(Master/Slave Architecture),由一个主节点(NameNode)和多个从节点(DataNode)组成。NameNode负责管理文件系统的命名空间和控制数据块的复制,DataNode负责实际存储文件数据块。HDFS默认情况下会将一个文件的数据块拆分成多个块,然后存储在不同的DataNode上。HDFS还支持多种文件操作,如读、写、列出目录内容和删除文件等。
- hdfs特点:大规模数据存储、高容错性、高吞吐量、维护成本低、开放源代码。
- hdfs用途:HDFS广泛应用于数据存储和分析领域,其用途包括但不限于以下几个方面:
- 大数据存储(海量数据储存):HDFS适用于存储海量的数据,例如Web应用的访问日志、传感器数据、机器学习模型数据等等。
- 分布式计算:HDFS作为Hadoop分布式计算框架的文件系统,可以存储和管理需要大规模计算的数据,例如MapReduce计算、Spark计算等。
- 数据备份:由于数据在HDFS中自动进行备份,可以保证数据的安全性和可靠性,在负载均衡和节点故障时也能够进行数据恢复。
- 数据清洗和转换:HDFS可以作为存储原始数据的数据仓库,对数据进行清洗和转换,例如将文本文件转换为序列文件、将非结构化数据转换为结构化数据等。
- 流式数据的访问(对文件进行访问的时候从文件的开头读到结尾)
- 存储方式:采用分布式存储,一份数据被存储到多个服务器。
- 元数据:通过元数据记录文件被拆分成了多个个块,每一个块存储在哪个服务器上,以及块的 排列顺序,固定大小150k,不可更改,每一个数据块都有一个元数据,在内存中。
- 数据块与元数据:
- 数据块:实际存放数据的地方,因为在文件系统中一个大的文件被拆分成了若干个小的块,数 据块在1.0数据块大小是64M,在2.0后都是默认值是128M(,默认值支持更改)
- 不适合做:大量的小文件(存个几k的文件也会生成一个150k的元数据)、进行低延迟读取(速度不会很快)、随机插入(加1M的东西需要去进行大量的分块的操作),支持追加写,写入到文 件末尾 、多用户(一次只有一个write)支持并发读
- 数据块与元数据的区别:在Hadoop中,数据块是用于存储和传输数据的单位,而元数据是描述和提供关于数据的元信息。简而言之,数据块是实际的数据存储单位,而元数据则包含有关这些数据块的元信息。
- 什么是数据的元信息:数据的元信息是关于数据本身的信息,包括数据的类型、长度、编码方式、存储位置、时间戳等。它提供了关于数据的重要元数据,如数据的来源、数据的时间戳、数据的存储位置、数据的校验和等。元信息对于数据的读取、写入、删除等操作非常重要,可以帮助用户理解数据的内容和属性,以及如何使用和操作这些数据。在Hadoop等分布式系统中,元信息对于数据的存储、复制、传输和检索等方面也起着至关重要的作用。
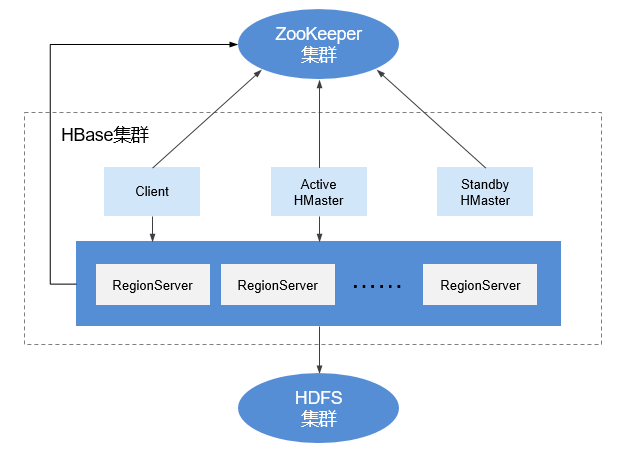
- hdfs架构

- hdfs高可用

- 联邦机制

- 副本存放策略






























![[ C++ ] STL---map与set的使用指南](https://img-blog.csdnimg.cn/direct/01d37971f50f47e09c5abbc76130f7e7.png)