HDFS是经典的Master和Slave架构,每一个HDFS集群包括一个NameNode和多个DataNode。
NameNode管理所有文件的元数据信息,并且负责与客户端交互。DataNode负责管理存储在该节点上的文件。每一个上传到HDFS的文件都会被划分为一个或多个数据块,这些数据块根据HDFS集群的数据备份策略被分配到不同的DataNode上,位置信息交由NameNode统一管理。

NameNode
用于管理文件系统的命名空间、维护文件系统的目录结构树以及元数据信息,记录写入的每个数据块(Block)与其归属文件的对应关系。
此信息以命名空间镜像(FSImage)和编辑日志(EditsLog)两种形式持久化在本地磁盘中。
DataNode
DataNode是文件的实际存放位置。
DataNode会根据NameNode或Client的指令来存储或者提供数据块,并且定期的向NameNode汇报该DataNode存储的数据块信息。
Blocks
HDFS将文件拆分成128 MB大小的数据块进行存储,这些Block可能存储在不同的节点上。HDFS可以存储更大的单个文件,甚至超过任何一个磁盘所能容纳的大小。一个Block默认存储3个副本(EMR Core节点如果使用云盘,则为2副本),以Block为粒度将副本存储在多个节点上。此方式不仅提高了数据的安全性,而且对于分布式作业可以更好地利用本地的数据进行计算,减少网络传输。
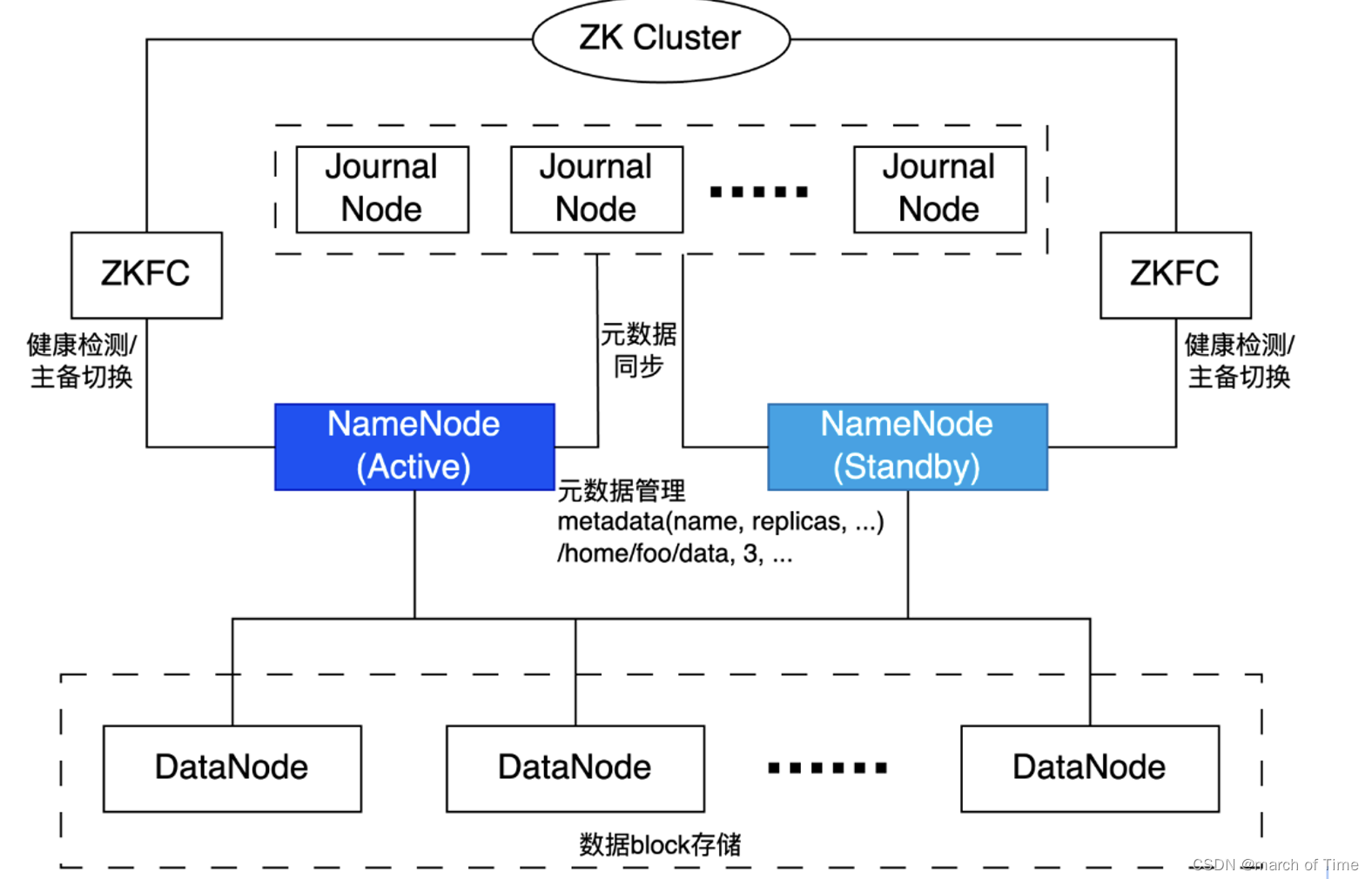
高可用
对于高可用集群,默认会启动两个NameNode,一个是Active NameNode,另一个是Standby NameNode,两个NameNode承担不同角色。
Active NameNode负责处理DataNode和Client的请求,Standby NameNode跟Active NameNode一样拥有最新的元数据信息,随时准备在Active NameNode出现异常时接管其服务。如果Active NameNode异常,Standby NameNode会感知到并切换成Active NameNode的角色处理DataNode和Client请求。
参考文档
什么是HDFS_开源大数据平台E-MapReduce-阿里云帮助中心
大数据技术之Hadoop(HDFS)第1章 HDFS概述-腾讯云开发者社区-腾讯云
![[AIGC <span style='color:red;'>大</span><span style='color:red;'>数据</span><span style='color:red;'>基础</span>] 浅谈<span style='color:red;'>hdfs</span>](https://img-blog.csdnimg.cn/img_convert/19fb698dcd7bf051b8d1a057ce063c81.jpeg)




















![[linux]进程间通信-管道pipe的实际用法(写入/读取)](https://img-blog.csdnimg.cn/direct/71bce5e1d2ec4f5cb4ec67fc9020fb74.png)