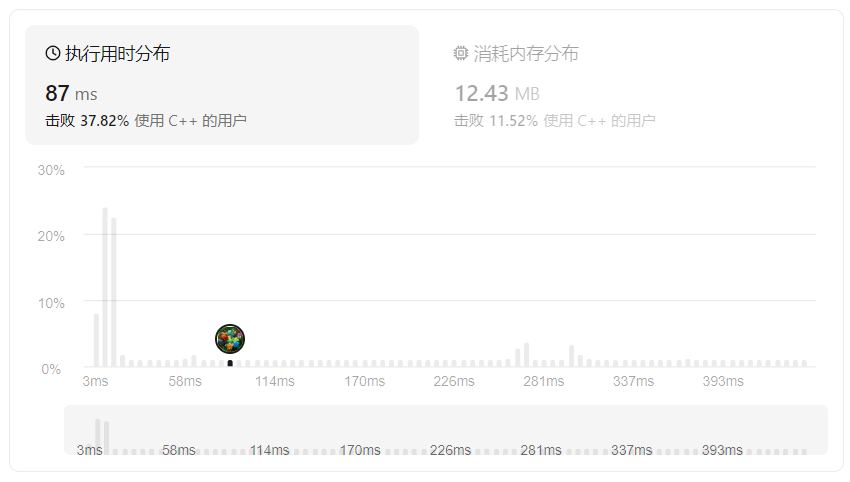
leetcode刷题-回忆法
1.两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
方法 1: 暴力解法
#include <vector>
using std::vector;
vector<int> twoSumBruteForce(const vector<int>& nums, int target) {
for (int i = 0; i < nums.size(); ++i) {
for (int j = i + 1; j < nums.size(); ++j) {
if (nums[i] + nums[j] == target) {
return {i, j};
}
}
}
return {}; // 如果没有答案,返回空数组
}
回忆法
第一遍回忆
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
int n=nums.len()
for(i=0;i<n;i++){
for(j=i;j<n;j++){
if(sums[i]+sums[j]==target)
return i,j;
}
}
return {};
};
错误
- 在C++中,获取vector大小的正确方法是调用.size()而不是.len()。
- 循环变量i和j应该在使用前声明。
- 应该检查nums[i] + nums[j]而不是sums[i] + sums[j],因为数组名是nums。
- return语句应该返回一个vector类型的对象,不能直接返回两个值。应该写成return {i, j};。
- 第二个for循环中的j应该从i+1开始,否则会重复比较相同的元素或者自己和自己比较。
GPT修改
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
int n = nums.size();
for(int i = 0; i < n; i++){
for(int j = i + 1; j < n; j++){
if(nums[i] + nums[j] == target)
return {i, j};
}
}
return {};
}
};
第二遍回忆
一开始报错了
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
for(int i=0;i<nums.size();i++){
for (int j=i+1;j<nums.size();j++){
if(nums[i]+nums[j]==target){
return{i,j};
}
}
}
}
return{};
};
原来是我把最后一个return{}的位置搞错了,return{}应该由twoSum()这个函数来返回。下面是修改之后的程序,终于没问题了!!!!!
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
for(int i=0;i<nums.size();i++){
for (int j=i+1;j<nums.size();j++){
if(nums[i]+nums[j]==target){
return{i,j};
}
}
}
return{};
}
};
方法 2: 两遍哈希表
- 初始化一个哈希表(
unordered_map),用于存储数组中每个元素的值和它们对应的索引。 - 第一遍循环:遍历数组,将数组中的每个元素及其索引加入到哈希表中。这样,我们就可以快速地通过元素值查找其索引。
- 第二遍循环:再次遍历数组,对于每个元素,计算它和目标值之间的差值(称为“补数”)。然后,在哈希表中查找这个补数。如果补数存在,并且补数的索引不是当前元素的索引(避免使用相同元素两次),则返回这两个索引作为答案。
- 如果遍历结束还没有找到符合条件的元素对,则返回一个空数组。
#include <vector>
#include <unordered_map>
using std::vector;
using std::unordered_map;
vector<int> twoSumTwoPassHashTable(const vector<int>& nums, int target) {
unordered_map<int, int> num_to_index;
for (int i = 0; i < nums.size(); ++i) {
num_to_index[nums[i]] = i;
}
for (int i = 0; i < nums.size(); ++i) {
int complement = target - nums[i];
if (num_to_index.find(complement) != num_to_index.end() && num_to_index[complement] != i) {
return {i, num_to_index[complement]};
}
}
return {}; // 如果没有答案,返回空数组
}
- 创建一个哈希表
num_to_index,用来存储数组中每个数值和对应索引的映射。- 第一遍遍历数组
nums,将数组中的每个数值和它的索引加入到哈希表中。num_to_index[nums[i]] = i;这一行将数值nums[i]作为键,将索引i作为值存入哈希表。- 第二遍遍历数组
nums,计算每个数值与目标值target之间的差值complement,这个差值就是我们需要在哈希表中寻找的另一个数值。- 使用
num_to_index.find(complement)来检查差值complement是否存在于哈希表中。如果存在,且找到的索引不是当前的数值i(因为每个元素不能使用两次),那么我们就找到了一对符合条件的数值,即nums[i]和nums[num_to_index[complement]]。- 如果找到了符合条件的一对数值,函数返回一个包含这两个索引的数组
{i, num_to_index[complement]}。- 如果遍历完整个数组也没有找到符合条件的数值对,则函数返回一个空数组
{}。
假设我们有一个 std::unordered_map<int, int>,这个哈希表映射一些整数到其他整数,如下所示:
std::unordered_map<int, int> num_to_index = {{2, 0}, {7, 1}, {11, 2}, {15, 3}};
这个哈希表表示数字 2 在索引 0,数字 7 在索引 1,依此类推。
找到元素的情况
如果我们要查找数字 11 的索引,我们可以这样使用 find 方法:
auto it = num_to_index.find(11);
在这个例子中,因为数字 11 存在于哈希表中,find 方法会返回一个指向 {11, 2} 这个键值对的迭代器 it。这个迭代器可以用来访问键和值,例如 it->first 会得到 11,it->second 会得到 2。
没有找到元素的情况
现在,如果我们尝试查找一个不存在的数字,比如 3:
auto it = num_to_index.find(3);
在这种情况下,因为数字 3 不在哈希表中,find 方法会返回 end() 迭代器。这个迭代器表示哈希表的结束,并不指向任何有效的键值对。我们通常会这样检查 find 方法的结果:
if (it != num_to_index.end()) {
// 找到了元素,可以使用 it 访问
} else {
// 没找到元素
}
总结一下,find 方法在找到元素时返回指向该元素的迭代器,在没有找到元素时返回 end() 迭代器。通过比较返回的迭代器是否等于 end() 迭代器,我们可以判断是否成功找到了目标元素。
第一遍做回忆
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
std::unordered_map<std::int, std::int> hash_table;
for(int i=0;i<nums.size();i++){
//加入到哈希表
}
for(int i=0;i<nums.size();i++ )
{
if(补数在哈希表中有,并且不是自己)
return {两个索引}
}
}
return{};
};
GPT修正
class Solution {
public:
std::vector<int> twoSum(std::vector<int>& nums, int target) {
// 使用一个哈希表来存储每个数字及其对应的索引
std::unordered_map<int, int> hash_table;
// 第一次循环:加入所有元素到哈希表
for (int i = 0; i < nums.size(); i++) {
hash_table[nums[i]] = i;
}
// 第二次循环:查找每个元素的补数是否存在于哈希表中
for (int i = 0; i < nums.size(); i++) {
int complement = target - nums[i];
// 检查补数是否存在于哈希表中,并且补数的索引不是当前数字的索引
if (hash_table.find(complement) != hash_table.end() && hash_table[complement] != i) {
// 如果找到了补数,返回当前索引和补数的索引
return {i, hash_table[complement]};
}
}
// 如果没有找到任何符合条件的两个数,返回空数组
return {};
}
};
第二遍做回忆
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int, int> hash_table;
int n = nums.size();
for(int i = 0; i < n; i++){
hash_table[nums[i]]=i;
}
for(int i=0;i<n;i++){
int c=target-nums[i];
if(hash_table.find(c)!=hash_table.end()&&hash_table(c)!=i)
return {i,hash_table(c)};
}
return {};
}
};
结果报错,原因是:不是hash_table(c)而是hash_table[c]
GPT修改
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int, int> hash_table;
int n = nums.size();
for(int i = 0; i < n; i++){
hash_table[nums[i]]=i;
}
for(int i=0;i<n;i++){
int c=target-nums[i];
if(hash_table.find(c)!=hash_table.end()&&hash_table[c]!=i)
return {i,hash_table[c]};
}
return {};
}
};
在C++中,++i 和 i++ 都是增加变量i的值,但是它们在表达式中的行为有所不同,这种区别称为前置(prefix)和后置(postfix)增量操作。
++i(前置增量):首先增加i的值,然后返回增加后的值。
i++(后置增量):首先返回i的当前值,然后再增加i的值。
在“两数之和”的问题中,你通常在循环中使用这些操作来递增索引。无论是++i还是i++,在循环的每次迭代之后,i的值都会增加1。但是,由于这些操作在循环中用作独立的语句而不是表达式的一部分,所以它们的前置和后置形式在这里实际上没有区别——它们都会在下一次迭代之前递增i的值。
然而,如果这些操作是表达式的一部分,那么选择哪一种形式就会影响到表达式的结果。在大多数现代编译器中,如果不需要使用i++的返回值,推荐使用++i,因为它可能稍微高效一点,尤其是在处理非内置类型的对象时(尽管对于基本类型,编译器通常会优化这两种形式,使它们的性能相同)。
方法 3: 一遍哈希表
- 同样,初始化一个哈希表用于存储元素值与索引的映射。
- 单次遍历
在遍历数组的同时,对于每个元素,先计算它和目标值之间的差值(补数)。然后,尝试在哈希表中查找这个补数。- 如果补数已存在于哈希表中,说明我们找到了一对符合条件的元素,即当前元素和哈希表中存储的补数。此时直接返回它们的索引。
- 如果补数不存在,则将当前元素及其索引加入到哈希表中,继续遍历。
- 如果遍历结束还没有找到符合条件的元素对,同样返回一个空数组。
#include <vector>
#include <unordered_map>
using std::vector;
using std::unordered_map;
vector<int> twoSumOnePassHashTable(const vector<int>& nums, int target) {
unordered_map<int, int> num_to_index;
for (int i = 0; i < nums.size(); ++i) {
int complement = target - nums[i];
if (num_to_index.find(complement) != num_to_index.end()) {
return {num_to_index[complement], i};
}
num_to_index[nums[i]] = i;
}
return {}; // 如果没有答案,返回空数组
}
- 创建一个
unordered_map<int, int>哈希表num_to_index,用来存储数值到索引的映射。- 遍历输入数组
nums的每个元素,索引为i,值为nums[i]。- 计算目标值
target与当前元素nums[i]的差值complement。这个差值是为了找到一个数,加上nums[i]后等于target。- 在哈希表中查找这个差值
complement。如果complement已经存在于哈希表中(即num_to_index.find(complement) != num_to_index.end()为真),说明我们找到了两个数的和等于target:complement和nums[i]。- 如果找到了这样的一个数,则函数返回一个包含两个数索引的数组。由于哈希表存储的是之前遍历过的数的索引,所以先返回
num_to_index[complement],即之前数的索引,再返回当前数的索引i。- 如果差值
complement不在哈希表中,将当前的数值和索引对nums[i]和i存入哈希表。这样做是为了在后续的迭代中能够找到与后来的元素配对。- 如果数组中没有两个数的和等于
target,则在遍历结束后返回一个空数组{}。
第一遍回忆
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int, int> hash_table;
int n = nums.size();
for(int i=0;i<n;i++){
int c=target-nums[i];
if(hash_table.find(c)!=hash_table.end())
return {i,hash_table[c]};
else
hash_table[nums[i]]=i;
}
return {};
}
};
GPT修正
你的代码逻辑本身是正确的,用于解决“两数之和”问题,即在数组nums中找到两个数使得它们的和等于给定的target,然后返回这两个数的索引。使用哈希表hash_table来存储已经遍历过的数字及其索引,以便快速查找target - nums[i]是否已经存在于之前的数字中。
这段代码是一个高效的实现,时间复杂度为O(n),因为它只需要遍历数组一次。每次迭代,它都会检查当前元素nums[i]所需的配对元素c = target - nums[i]是否已经存在于哈希表中。如果存在,就意味着找到了一个解,函数将返回这两个元素的索引。如果不存在,当前元素及其索引会被添加到哈希表中,以供后续查找使用。
代码没有语法错误,但我会稍微调整代码风格,以提高其可读性:
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int, int> hash_table; // 存储值到索引的映射
int n = nums.size();
for (int i = 0; i < n; ++i) {
int complement = target - nums[i]; // 需要找的另一个数
// 如果complement在哈希表中,返回当前索引和complement的索引
if (hash_table.find(complement) != hash_table.end()) {
return {i, hash_table[complement]};
}
// 否则,将当前数及其索引加入哈希表
hash_table[nums[i]] = i;
}
return {}; // 如果没有解,返回空数组
}
};
这段代码的修改仅仅是为了提高可读性,没有改变原本的逻辑。使用complement来明确表示我们在查找的是哪一个数,以及使用空格和注释来提高代码的清晰度。
总结
主要区别:
- 第二段代码使用了两遍遍历的方法:第一遍用于构建哈希表,第二遍用于查找补数。
- 第三段代码通过只遍历一遍数组,在遍历过程中同时构建哈希表和查找补数,提高了效率。
两者都利用了哈希表(unordered_map)来提高查找速度,差别主要在于遍历的次数。一遍哈希表法更加高效,因为它将问题解决在一个循环中。