🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
近年来,随着人们对健康饮食的关注度不断提高,牛油果作为一种营养丰富的食材逐渐受到消费者的青睐。然而,牛油果价格和销量的波动对生产者、零售商和消费者都产生了影响。为了更好地了解牛油果市场的变化趋势,本研究旨在通过可视化分析和预测牛油果价格和销量,为相关利益方提供决策支持。
本研究的重要意义在于:
- 帮助生产者合理规划生产和定价策略,提高市场竞争力;
- 协助零售商制定进货和销售计划,优化库存管理;
- 为消费者提供价格和销量信息,引导其合理购买决策;
- 推动牛油果产业的可持续发展,增加经济效益。
通过可视化分析和预测牛油果价格和销量,本研究将为相关利益方提供有价值的市场信息,促进牛油果市场的健康发展。同时,本研究还将为其他农产品市场的分析和预测提供借鉴,推动农业产业的可持续发展。
2.数据集介绍
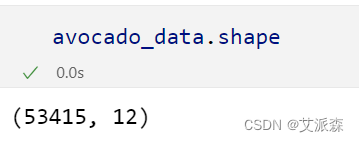
本数据集来源于Kaggle,数据集为2015-2023 年牛油果价格和销量,原始数据集共有53415条,12个变量。

3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.导入数据
首先导入第三方库并加载数据集
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
import warnings
warnings.filterwarnings('ignore')
sns.set_style('darkgrid')
plt.style.use('ggplot')
avocado_data = pd.read_csv('Avocado_HassAvocadoBoard_20152023.csv')
avocado_data.head()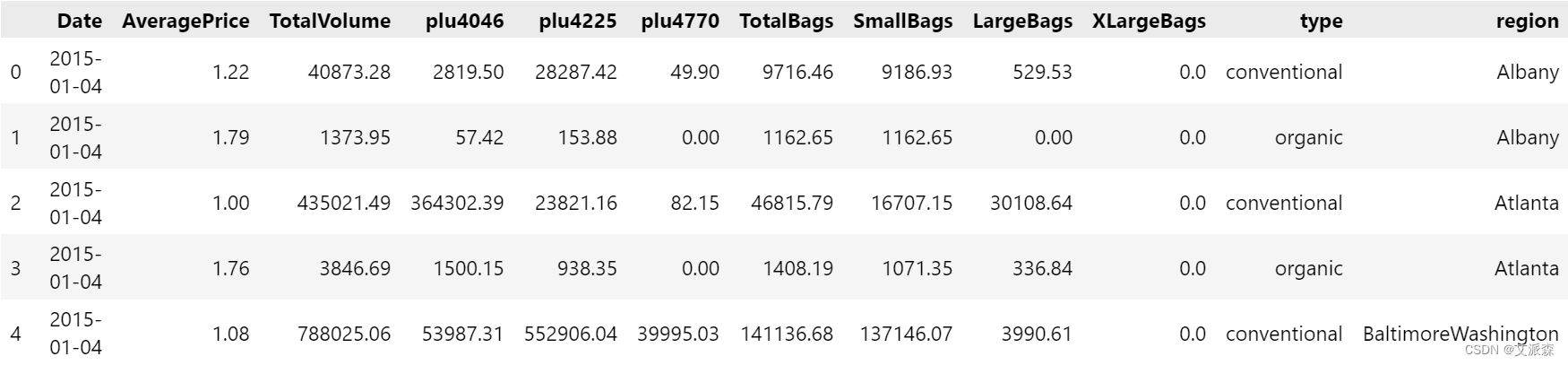
查看数据大小
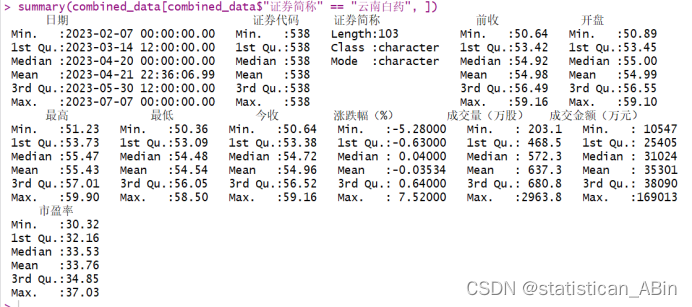
查看数据基本信息
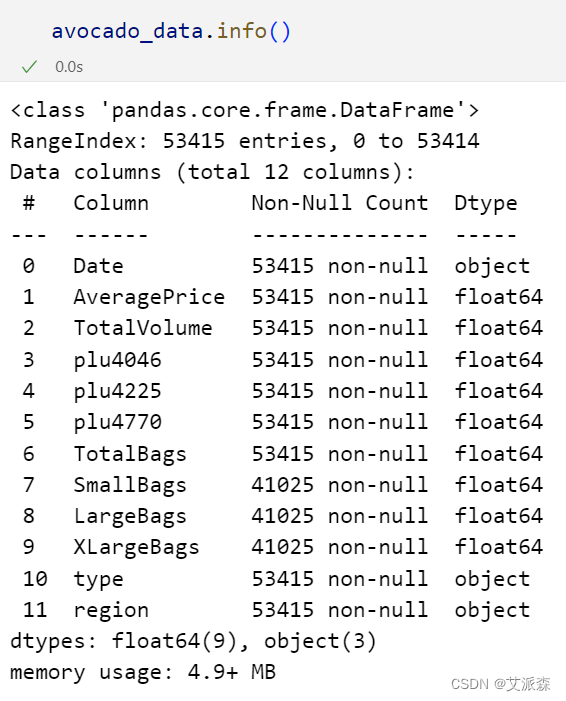
查看描述性统计
统计缺失值情况

检查并计数重复的行
# 检查并计数重复的行
duplicate_count = avocado_data.duplicated().sum()
print(f"Number of duplicated rows: {duplicate_count}")
检测异常值
# 根据“平均价格”列中的IQR识别异常值
Q1 = avocado_data['AveragePrice'].quantile(0.25)
Q3 = avocado_data['AveragePrice'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers_price = (avocado_data['AveragePrice'] < lower_bound) | (avocado_data['AveragePrice'] > upper_bound)
# 打印异常值的数量
print(f"Number of outliers in AveragePrice: {outliers_price.sum()}")
删除异常值

缺失值处理
# 识别有缺失值的行
missing_rows = avocado_data[avocado_data[['SmallBags', 'LargeBags', 'XLargeBags']].isnull().any(axis=1)]
# 遍历缺失的行
for index, row in missing_rows.iterrows():
# 生成总和为1的随机百分比
random_percentages = np.random.dirichlet(np.ones(3), size=1)[0]
# 计算使总和等于TotalBags所需的剩余值
remaining_value = row['TotalBags'] - row[['SmallBags', 'LargeBags', 'XLargeBags']].sum()
# 用随机百分比填充缺失值
avocado_data.at[index, 'SmallBags'] = remaining_value * random_percentages[0]
avocado_data.at[index, 'LargeBags'] = remaining_value * random_percentages[1]
avocado_data.at[index, 'XLargeBags'] = remaining_value * random_percentages[2]
# 验证是否没有其他缺失的值
print(avocado_data[['TotalBags', 'SmallBags', 'LargeBags', 'XLargeBags']].isnull().sum())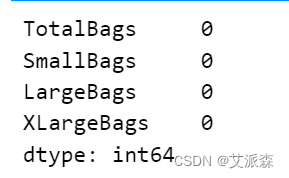
数据类型转换
avocado_data[['plu4046', 'plu4225', 'plu4770']] = avocado_data[['plu4046', 'plu4225', 'plu4770']].astype(str)
avocado_data[['TotalBags', 'SmallBags', 'LargeBags', 'XLargeBags']] = avocado_data[['TotalBags', 'SmallBags', 'LargeBags', 'XLargeBags']].astype(int)5.数据可视化
# 每个PLU代码的唯一值的数量
unique_counts = [avocado_data['plu4046'].nunique(), avocado_data['plu4225'].nunique(), avocado_data['plu4770'].nunique()]
plu_codes = ['PLU 4046', 'PLU 4225', 'PLU 4770']
barplot = sns.barplot(x=plu_codes, y=unique_counts, palette='viridis')
plt.title('Number of Unique Values for PLU Codes')
plt.xlabel('PLU Codes')
plt.ylabel('Number of Unique Values')
#在条形图的顶部添加数据值
for i, count in enumerate(unique_counts):
barplot.text(i, count + 0.1, str(count), ha='center', va='bottom')
plt.show()
# 计算所有行中每种包类型的和
total_small_bags = avocado_data['SmallBags'].sum()
total_large_bags = avocado_data['LargeBags'].sum()
total_xlarge_bags = avocado_data['XLargeBags'].sum()
# 为饼图创建数据
sizes = [total_small_bags, total_large_bags, total_xlarge_bags]
labels = ['SmallBags', 'LargeBags', 'XLargeBags']
colors = ['lightcoral', 'lightskyblue', 'lightgreen']
# 绘制饼状图
plt.figure(figsize=(4, 4))
plt.pie(sizes, labels=labels, colors=colors, autopct='%1.1f%%', startangle=140)
plt.title('Distribution of Bag Types')
plt.show()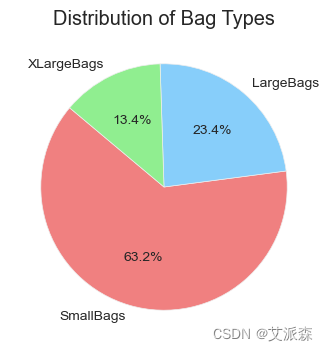
# 计算“type”的分布
type_distribution = avocado_data['type'].value_counts()
# 为饼状图创建数据
sizes = type_distribution.values
labels = type_distribution.index
colors = ['lightcoral', 'lightskyblue']
# 绘制饼状图
plt.figure(figsize=(4, 4))
plt.pie(sizes, labels=labels, colors=colors, autopct='%1.1f%%', startangle=140)
plt.title('Distribution of Avocado Types')
plt.show()
# 按“地区”分组,并计算每个地区的平均“平均价格”
avg_price_by_region = avocado_data.groupby('region')['AveragePrice'].mean()
sorted_avg_price_by_region = avg_price_by_region.sort_values(ascending=False)
top_regions = sorted_avg_price_by_region.head(10)
# 使用Plotly创建交互式水平条形图
fig = px.bar(x=top_regions.values, y=top_regions.index, orientation='h', color=top_regions.values,
labels={'x': 'Average Price', 'y': 'Region'}, title='Top Regions by Average Price',
color_continuous_scale='Plasma')
fig.show()
# 按“区域”分组,并计算每个区域的平均“TotalVolume”
avg_volume_by_region = avocado_data.groupby('region')['TotalVolume'].mean()
sorted_avg_volume_by_region = avg_volume_by_region.sort_values(ascending=False)
top_regions_volume = sorted_avg_volume_by_region.head(10)
# 使用Plotly创建交互式水平条形图
fig = px.bar(x=top_regions_volume.values, y=top_regions_volume.index, orientation='h', color=top_regions_volume.values,
labels={'x': 'Average Total Volume', 'y': 'Region'}, title='Top Regions by Average Total Volume',
color_continuous_scale='Jet')
fig.show()
# 过滤“TotalUS”区域的数据
total_us_data = avocado_data[avocado_data['region'] == 'TotalUS']
# 过滤其他区域的数据
other_regions_data = avocado_data[avocado_data['region'] != 'TotalUS']
# 计算“TotalUS”区域的“TotalVolume”之和
total_us_volume = total_us_data['TotalVolume'].sum()
# 计算其他区域的“TotalVolume”之和
other_regions_volume = other_regions_data.groupby('region')['TotalVolume'].sum().sum()
# 创建一个条形图来比较“TotalVolume”与“TotalUS”和其他
sns.barplot(x=['TotalUS', 'Other Regions'], y=[total_us_volume, other_regions_volume], palette='viridis')
plt.xlabel('Region')
plt.ylabel('Total Volume')
plt.title('Comparison of Total Volume for TotalUS and Other Regions')
plt.show()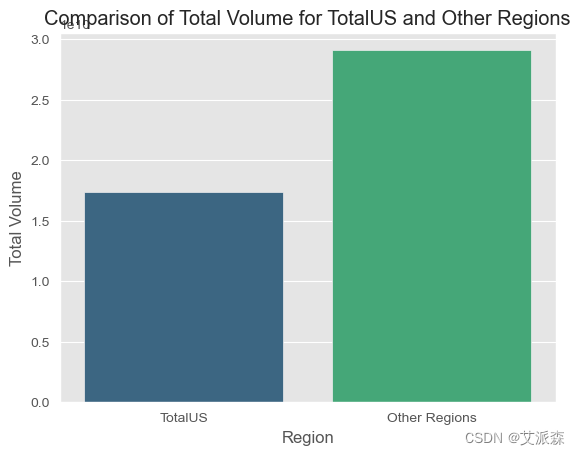
# 可视化AveragePrice的分布
plt.figure(figsize=(6, 4))
sns.histplot(avocado_data['AveragePrice'], bins=30, kde=True, color='blue')
plt.title('Distribution of Average Price')
plt.show()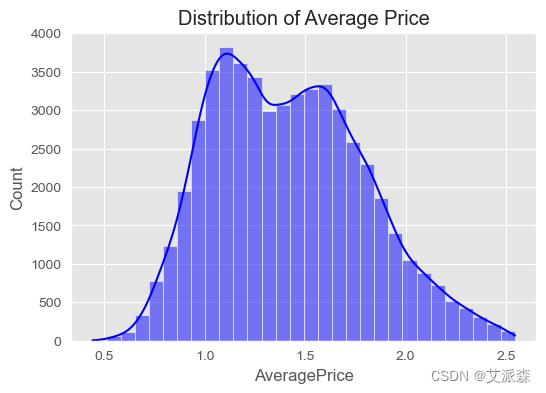
# 可视化TotalVolume的分布
plt.figure(figsize=(6, 4))
sns.histplot(avocado_data['TotalVolume'], bins=30, kde=True, color='green')
plt.title('Distribution of Total Volume')
plt.show()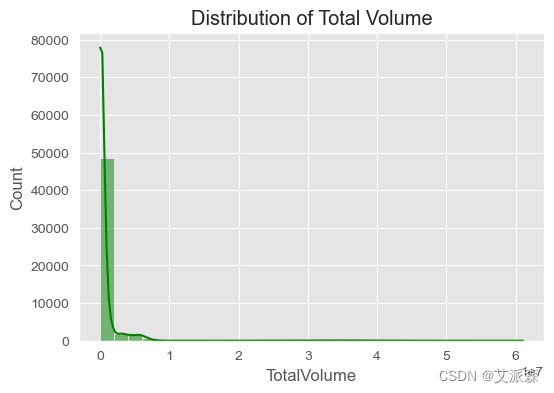
# 将“日期”列转换为日期时间格式
avocado_data['Date'] = pd.to_datetime(avocado_data['Date'])
# 随时间变化的平均价格
plt.figure(figsize=(14, 6))
sns.lineplot(x='Date', y='AveragePrice', data=avocado_data, color='orange')
plt.title('Average Avocado Price Over Time')
plt.show()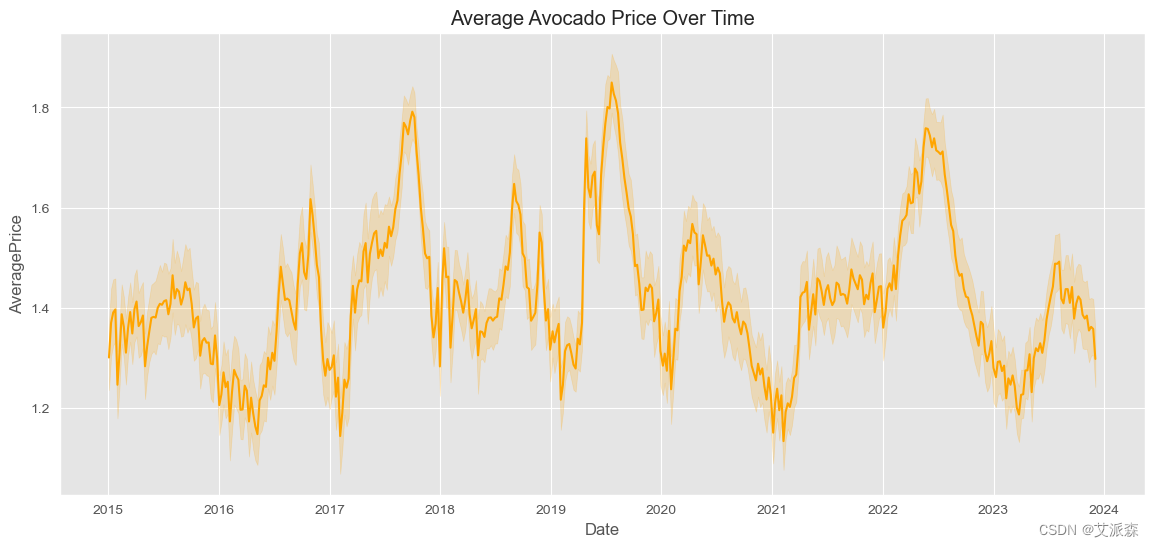
# 交互式绘制平均价格随时间的变化
fig = px.line(avocado_data, x='Date', y='AveragePrice', title='Average Avocado Price Over Time', markers=True)
fig.update_layout(xaxis_title='Date', yaxis_title='Average Price')
fig.show()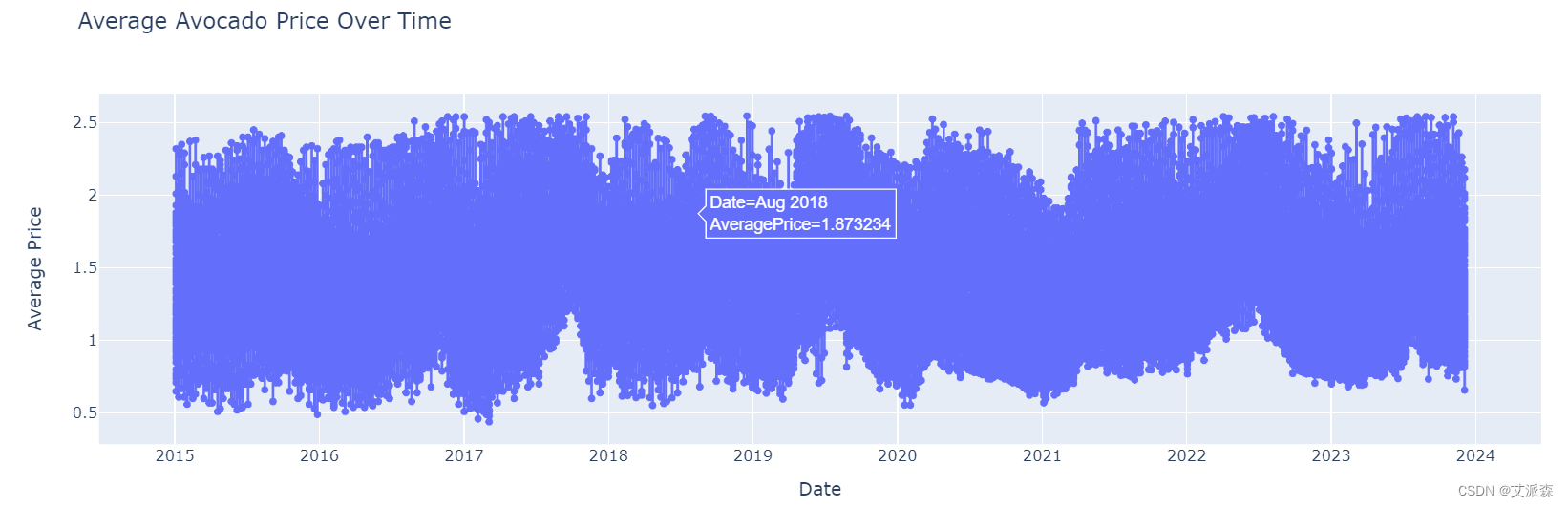
# 绘制总体积随时间的变化
plt.figure(figsize=(14, 6))
sns.lineplot(x='Date', y='TotalVolume', data=avocado_data, color='purple')
plt.title('Total Avocado Volume Over Time')
plt.show()
# 交互式绘制平均价格随时间的变化
fig = px.line(avocado_data, x='Date', y='TotalVolume', title='Total Avocado Volume Over Time', markers=True)
fig.update_layout(xaxis_title='Date', yaxis_title='Total Volume')
fig.show()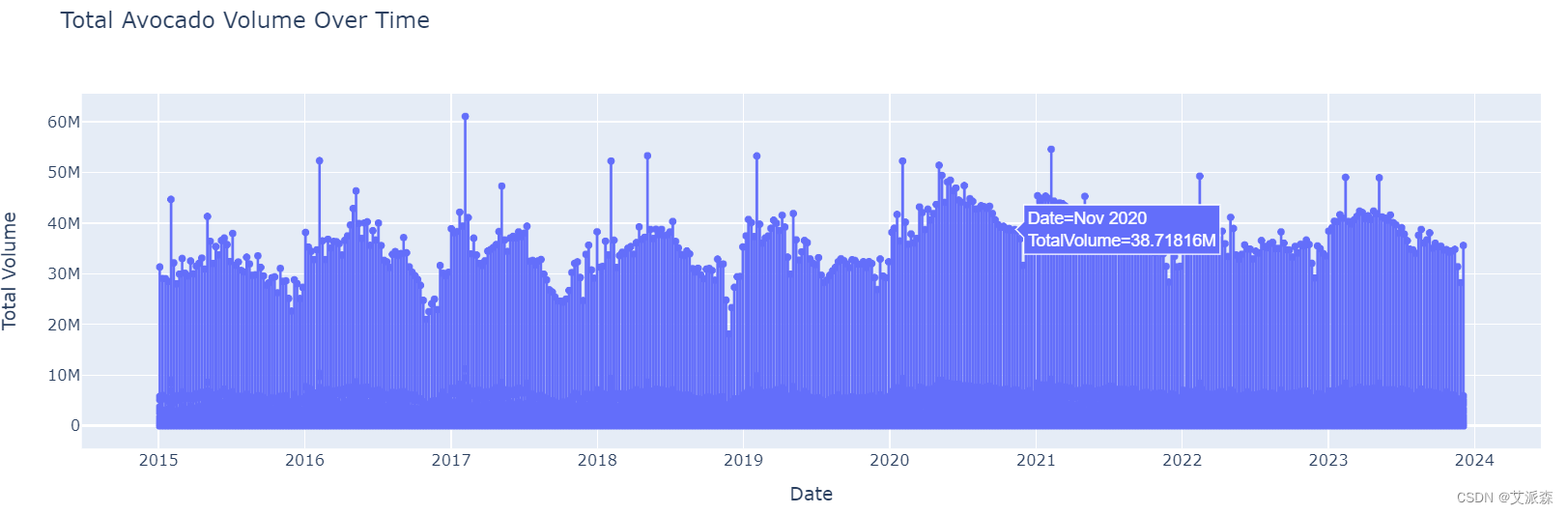
# 设置自定义箱边
custom_bin_edges = [0, 50000, 100000, 150000, np.inf]
# 为TotalVolume创建箱子
avocado_data['VolumeCategory'] = pd.cut(avocado_data['TotalVolume'], bins=custom_bin_edges, labels=['Low', 'Medium', 'High', 'Very High'])
# 为“TotalBags”创建箱子
avocado_data['BagsCategory'] = pd.cut(avocado_data['TotalBags'], bins=custom_bin_edges, labels=['Low', 'Medium', 'High', 'Very High'])
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
# “TotalVolume”的子图
ax1 = sns.countplot(x='VolumeCategory', data=avocado_data, palette='viridis', ax=axes[0])
ax1.set_title('Distribution of TotalVolume Categories')
ax1.set_xlabel('TotalVolume Category')
ax1.set_ylabel('Count')
# 为“TotalVolume”添加数据标签
for p in ax1.patches:
ax1.annotate(f'{int(p.get_height())}', (p.get_x() + p.get_width() / 2., p.get_height()), ha='center', va='baseline', fontsize=10, color='black')
# “TotalBags”的子图
ax2 = sns.countplot(x='BagsCategory', data=avocado_data, palette='viridis', ax=axes[1])
ax2.set_title('Distribution of TotalBags Categories')
ax2.set_xlabel('TotalBags Category')
ax2.set_ylabel('Count')
# 为“TotalBags”添加数据标签
for p in ax2.patches:
ax2.annotate(f'{int(p.get_height())}', (p.get_x() + p.get_width() / 2., p.get_height()), ha='center', va='baseline', fontsize=10, color='black')
plt.tight_layout()
plt.show()
6.建模预测
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error
# 创建DataFrame的副本
X = avocado_data[['Date', 'type', 'region', 'VolumeCategory', 'BagsCategory']].copy()
y = avocado_data['AveragePrice']
# 提取年、月、日
X['Year'] = X['Date'].dt.year
X['Month'] = X['Date'].dt.month
X['Day'] = X['Date'].dt.day
# 删除原来的“Date”列
X = X.drop('Date', axis=1)
# 初始化LabelEncoder
label_encoder = LabelEncoder()
# 对分类列应用标签编码
X['type'] = label_encoder.fit_transform(X['type'])
X['region'] = label_encoder.fit_transform(X['region'])
X['VolumeCategory'] = label_encoder.fit_transform(X['VolumeCategory'])
X['BagsCategory'] = label_encoder.fit_transform(X['BagsCategory'])
# 将数据分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化和训练线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 对测试集进行预测
predictions = model.predict(X_test)
# 评估模型
mae = mean_absolute_error(y_test, predictions)
print(f'Mean Absolute Error: {mae}')
# 创建1行2列的子图
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(15, 6))
# 带图例的实际价格与预测价格的散点图
sns.scatterplot(x=y_test, y=predictions, label='Actual Prices', alpha=0.7, ax=axes[0])
sns.scatterplot(x=y_test, y=y_test, label='Predicted Prices', alpha=0.7, ax=axes[0])
axes[0].set_title('Actual vs. Predicted Prices with Legends')
axes[0].set_xlabel('Actual Prices')
axes[0].set_ylabel('Predicted Prices')
axes[0].legend()
# 带有图例的残差图
residuals = y_test - predictions
sns.scatterplot(x=predictions, y=residuals, label='Residuals', alpha=0.7, ax=axes[1])
axes[1].axhline(y=0, color='black', linestyle='--', label='Zero Residual Line')
axes[1].set_title('Residual Plot with Legends')
axes[1].set_xlabel('Predicted Prices')
axes[1].set_ylabel('Residuals')
axes[1].legend()
plt.tight_layout()
plt.show()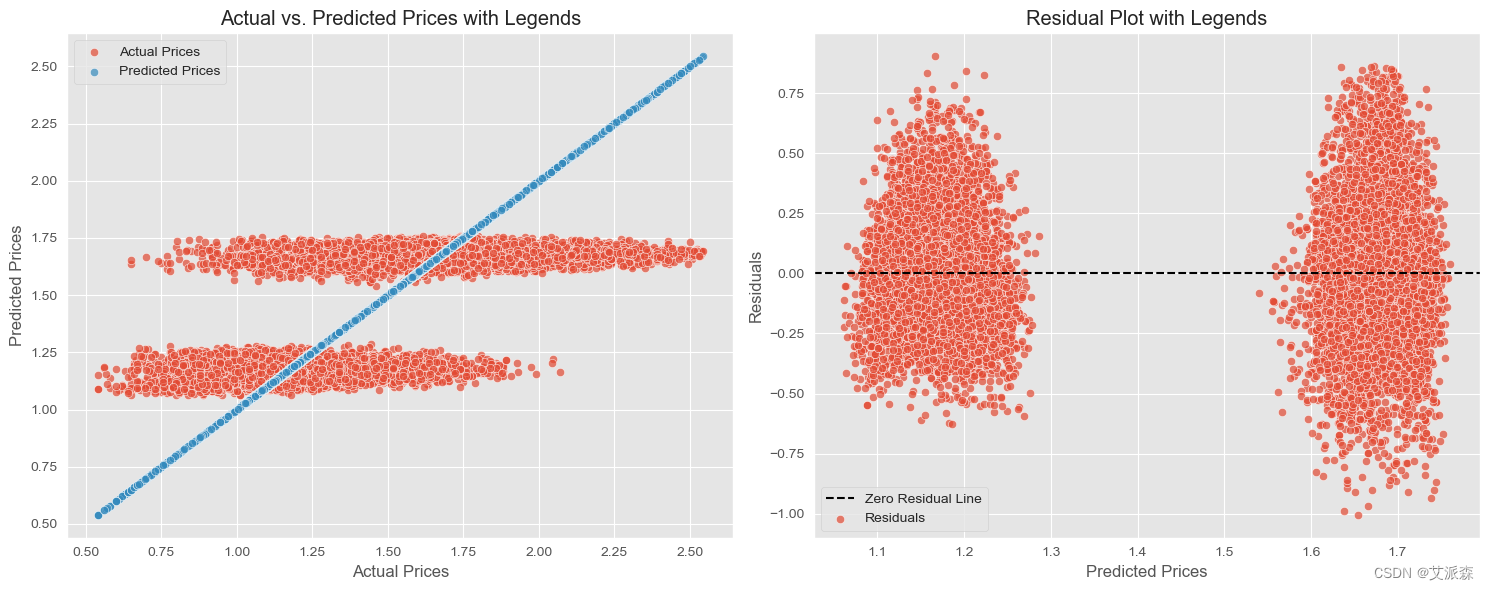 总结:
总结:
本次分析为牛油果数据集提供了有价值的见解,有助于更好地理解影响牛油果价格和数量的因素。
- 经过训练的线性回归模型在预测牛油果价格方面表现出了良好的性能,这一点可以通过评估指标和预测实际价值的可视化来证明。
- 进一步的调查、特征工程和对其他模型的探索可以增强预测能力和分析的深度。
这一分析为继续探索和改进模型奠定了基础,可能有助于更准确的预测和更深入地了解牛油果市场动态。
文末推荐与福利
《向AI提问的艺术:提示工程入门与应用》免费包邮送出3本!

内容简介:
本书从ChatGPT基本原理及提示工程的基本概念讲起,重点介绍了提示工程的各种技巧,不仅通过实例生动地展示了如何运用这些技巧,还深度解析了各种技巧的使用场景及其潜在局限 性。进一步地,本书结合多个行业背景,系统地阐述了ChatGPT和提示工程的具体应用,帮助读者理解和应用提示工程。
本书分为11章,主要包含四部分:第1章解读ChatGPT的基础原理及提示工程的基本概念;第2~5章详细介绍提示工程技巧,涵盖有效提示编写、针对复杂任务的提示设计技巧、对话中的提示设计技巧,以及提示的优化与迭代;第6章主要介绍当前ChatGPT推出的进阶功能;第7~11章结合教育领域、市场营销、新媒体运营、软件开发和数据分析等用实战展示提示工程技巧的应用。
本书语言通俗易懂、内容实用,并且结合丰富案例,非常适合开发人员、产品经理、创业者、学生及其他对新兴技术感兴趣的读者。鉴于书中提供了大量行业应用实例,教育工作者、市场营销专家、新媒体从业者和数据分析师也可从中获得实用方法,从而提高工作效率。
编辑推荐:
1.力求实用和好用,帮助读者将AI转化成生产力。
2.从ChatGPT原理到应用,从本质上理解AI模型应用。
3.从简单任务逐步到复杂任务,理解提示任务和目的。
4.提示设计循序渐进,掌握各种场景的提示设计方法。
5.五大常用领域案例讲解,有效提高学习和工作效率。
6.结合插件实现高级功能,实现与AI的高效交互应用。
- 抽奖方式:评论区随机抽取3位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2024-4-11 20:00:00
名单公布时间:2024-4-11 21:00:00
资料获取,更多粉丝福利,关注下方公众号获取