🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
印度,这个充满神秘色彩和多元文化的国度,历来以其丰富多彩的美食传统吸引着全球的目光。印度美食不仅仅是一种味觉的享受,更是一种文化的传承和展现。然而,由于印度地域辽阔、民族众多,各地的美食文化之间存在着显著的差异,这也使得游客和食客在探索印度美食时往往感到困惑和迷茫。
随着大数据时代的到来,数据可视化成为了一种有效的手段,能够帮助人们更加直观、清晰地理解复杂的数据和信息。通过将印度美食相关的数据进行可视化处理,我们可以更好地揭示印度美食的多样性、地域特色以及发展趋势,从而为游客和食客提供更加精准的美食推荐和旅游指南。
此外,印度美食在全球范围内的流行度不断上升,越来越多的人开始关注和喜爱印度美食。通过数据可视化分析,我们可以深入了解印度美食在全球范围内的传播和接受程度,以及不同地域和文化背景下人们对印度美食的偏好和态度。这不仅有助于推动印度美食的国际化进程,也为印度餐饮行业的发展提供了重要的参考依据。
因此,基于以上背景,我们开展了印度美食数据可视化分析实验。通过对印度美食相关数据的收集、整理和分析,结合数据可视化技术,我们旨在揭示印度美食的奥秘,为游客和食客提供更加深入、全面的了解和体验印度美食的机会。同时,我们也希望通过这项研究,为印度餐饮行业的发展和国际化进程提供有益的参考和启示。
2.数据集介绍
印度美食由印度次大陆本土的各种地区和传统美食组成。由于土壤、气候、文化、种族和职业的多样性,这些菜肴差异很大,并使用当地可用的香料、香草、蔬菜和水果。印度食物也深受宗教(特别是印度教)、文化选择和传统的影响。
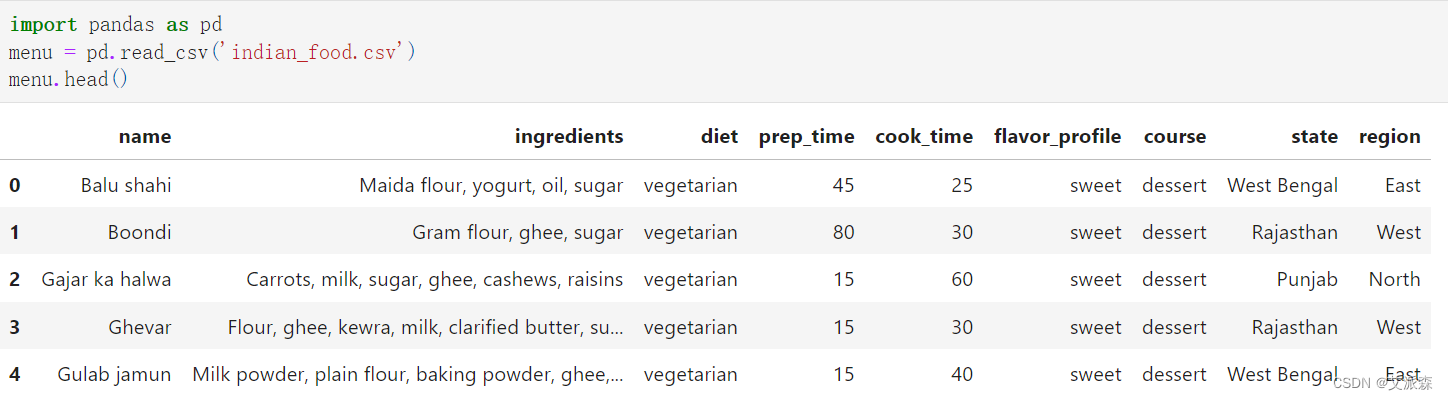
本数据集来源于Kaggle,原始数据集共有255条,8个变量,各变量含义解释如下:
name : 菜肴名称
ingredients:主要使用成分
diet:饮食类型 - 素食或非素食
prep_time : 准备时间
Cook_time : 烹饪时间
flavor_profile : 风味特征包括菜品是否辣、甜、苦等
course : 餐点 - 开胃菜、主菜、甜点等
state : 该菜肴著名或起源的州
Region : 国家所属地区
任何列中出现 -1 表示 NaN 值。
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.导入数据
使用Pandas加载数据集
查看数据大小

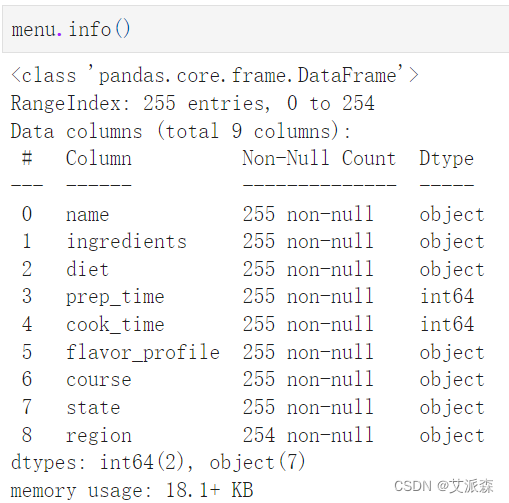
查看数据基本信息
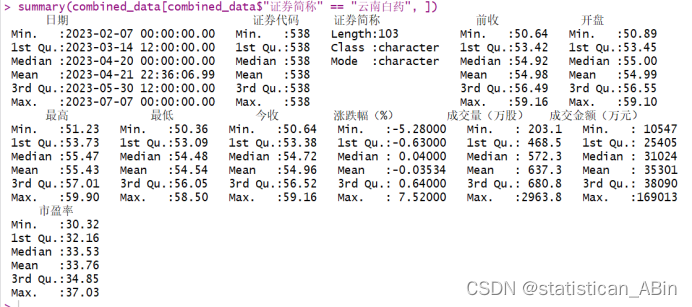
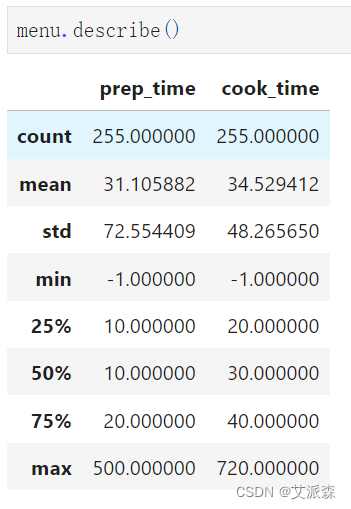
查看数值型变量的描述性统计
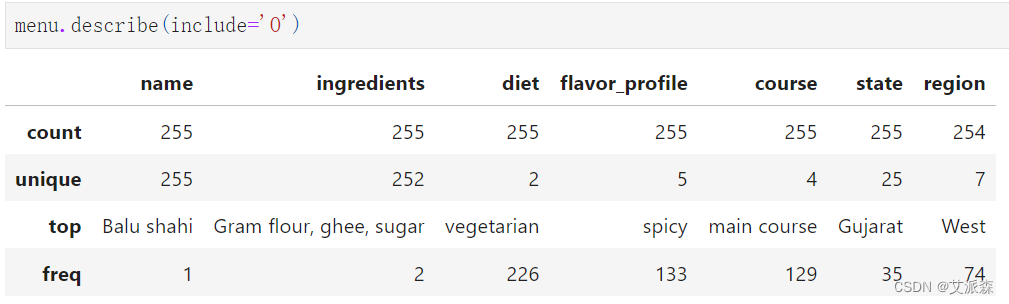
查看非数值型变量的描述性统计
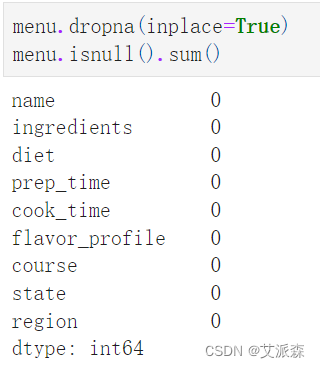
统计缺失值情况
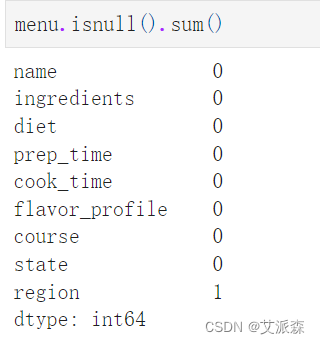
发现region有一个缺失值
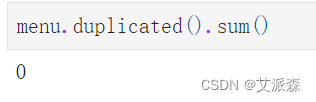
统计重复值情况
删除缺失值
5.数据可视化
5.1条形图
经典的条形图很容易阅读,也是一个很好的起点——让我们想象一下烹饪每道菜需要多长时间。
Pandas依赖于Matplotlib引擎来显示生成的图。因此,我们必须导入Matplotlib的PyPlot模块,以便在生成图形后调用plt.show()。
首先,让我们导入数据。在我们的数据集中有很多盘子——确切地说是255个。在保持可读性的情况下,这并不适合一个数字。我们将使用head()方法提取前10道菜,并提取与我们的图相关的变量。也就是说,我们希望将每个菜肴的名称和cook_time提取到一个名为name_and_time的新DataFrame中,并将其截断为前10个菜肴。

我们将使用bar()方法来绘制数据:bar(x=None, y=None, **kwargs)
x和y参数对应于x和y轴,kwargs对应于datafframe .plot()中记录的其他关键字参数。可以传递许多附加参数来进一步自定义绘图,例如用于标签旋转的rot,用于添加图例的legend,样式等……
这些参数中的许多都有默认值,其中大多数都是关闭的。由于rot参数默认为90,因此我们的标签将旋转90度。让我们在构建情节时将其改为30。

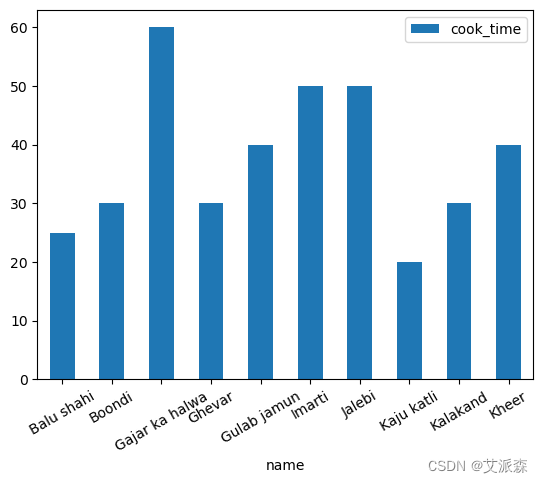
与其他菜肴相比,Gajak ka halwa需要更多的烹饪时间。
在Pandas的条形图的x轴上绘制多列
通常,我们可能希望比较条形图中的两个变量,例如cook_time和prep_time。这些都是对应于每道菜的变量,可以直接比较。让我们改变name_and_time DataFrame,使其也包括prep_time:

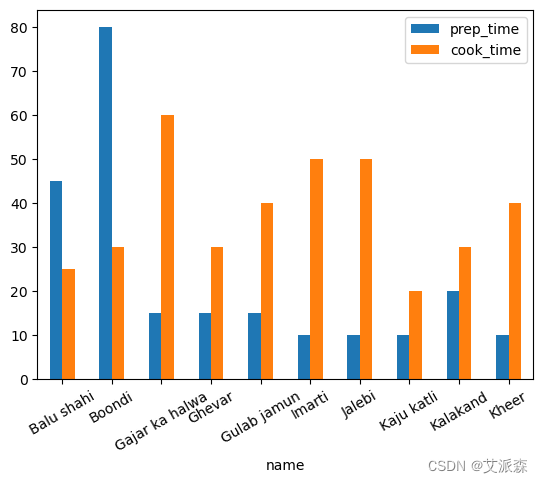
似乎煮得快的食物需要更多的准备时间,反之亦然。不过,这确实来自一个相当有限的数据子集,对于其他子集来说,这个假设可能是错误的。
堆叠柱形
让我们来看看哪道菜做起来耗时最长。因为我们想把准备时间和烹饪时间都考虑进去,所以我们会把它们叠在一起。为此,我们将stacked参数设置为True。

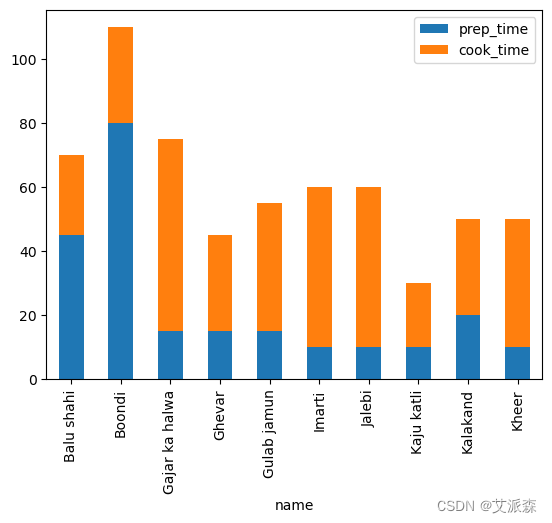
现在,考虑到准备时间和烹饪时间,我们可以很容易地看到哪些菜需要最长的准备时间。
在Pandas中自定义条形图,如果我们想让图形看起来更好一点,我们可以向bar()方法传递一些额外的参数,例如:
color:为每个DataFrame的属性定义颜色。它可以是一个字符串,如'orange', rgb或rgb代码,如#faa005。
title:表示情节标题的字符串或列表。
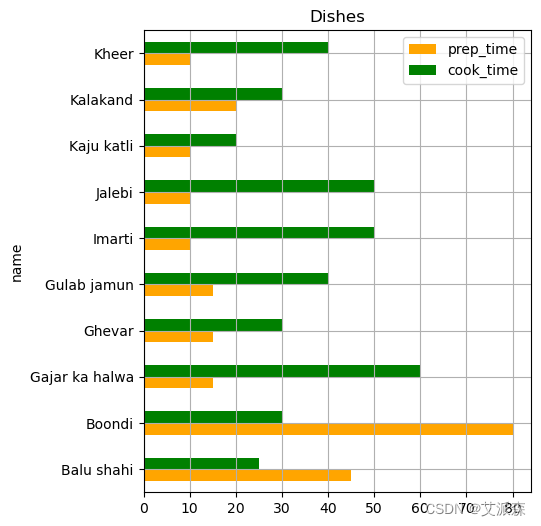
grid:一个布尔值,指示网格线是否可见。 figsize:以英寸为单位表示图形大小的元组。 legend:布尔值,指示是否显示图例。 如果我们想要一个水平条形图,我们可以使用bar()方法,它接受相同的参数。例如,让我们绘制一个橙色和绿色的水平条形图,标题为“Dishes”,有一个5 × 6英寸的网格,还有一个图例。

5.2直方图
直方图对于显示数据分布很有用。它的外观与条形图相似,只是它是连续的。
直方图中的塔状或条状被称为箱状。每个bin的高度显示了该数据中有多少值落在该范围内。 每个bin的宽度= (data的最大值- data的最小值)/ bin的总数
在直方图中创建的bin数量的默认值是10。但是,我们可以使用matplotlib.pyplot.hist()中的参数bins来改变箱子的大小。
方法1:我们可以在bin中传递一个整数,说明要在直方图中创建多少bin /tower,然后相应地更改每个bin的宽度。
例1:

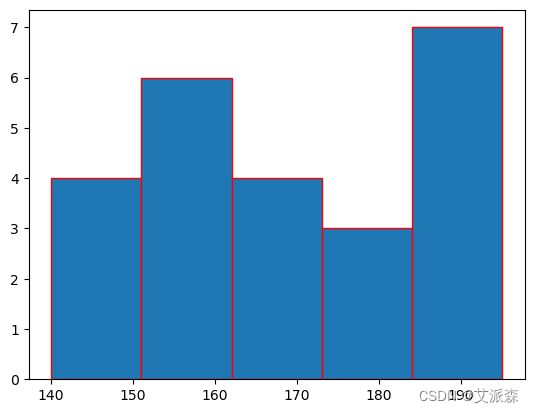
这里,bin = 5,即要创建的bin数量为5。将bins设置为整数将创建大小或宽度相等的bins。当bin大小改变,那么bin宽度将相应地改变为: 宽度= (195 - 140)/ 5 = 11

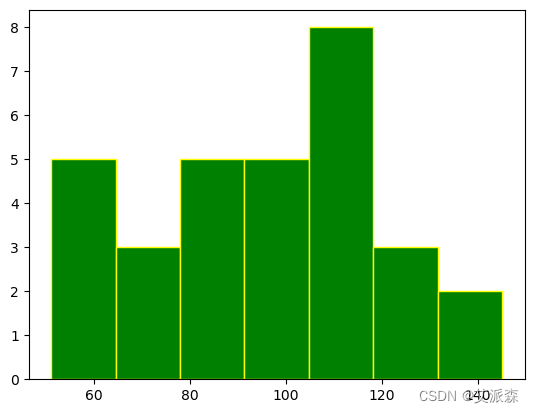
宽度= (145 - 51)/ 7 = 13.4
方法2:我们也可以在参数bin中传递一个int或float序列,其中序列的元素是bin的边/边界。在此方法中,每个容器的宽度可能不同。
假设将一个序列[1,2,3,4,5]分配给箱子,那么制造的箱子数量将是4,即第一个箱子将是[1,2)(包括1,但不包括2)第二个箱子将是[2,3)(包括2,但不包括3)第三个箱子将是[3,4)(包括3,但不包括4)。然而,在最后一个箱子[4,5]中,4和5都包括在内。
因此,所有的箱子都是半开的[a, b),但最后一个箱子是关闭的[a, b]。对于这种情况,每个容器的宽度是相等的。
如果分配给bin的序列中每个元素之间的差异不相等,则每个bin的宽度不同,因此bin的宽度取决于序列。

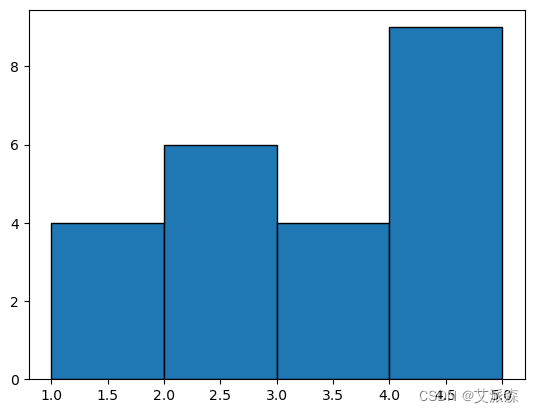

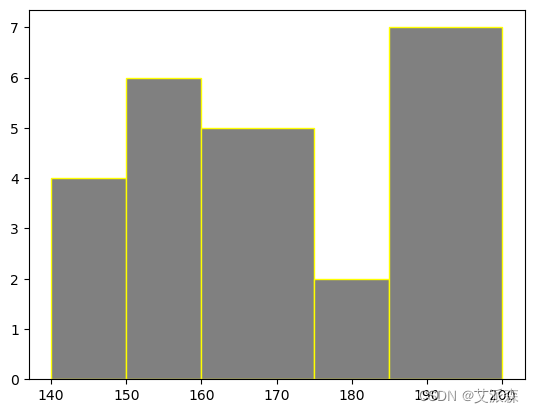
方法3:为了在bins参数中传递序列,我们也可以对等分布的bins使用range函数。在range()中,起始点是数据的最小值,终点是数据的最大值+提到的bin宽度,步长是bin宽度。
由于步长在range()中固定,我们在直方图中得到大小相等的箱子。
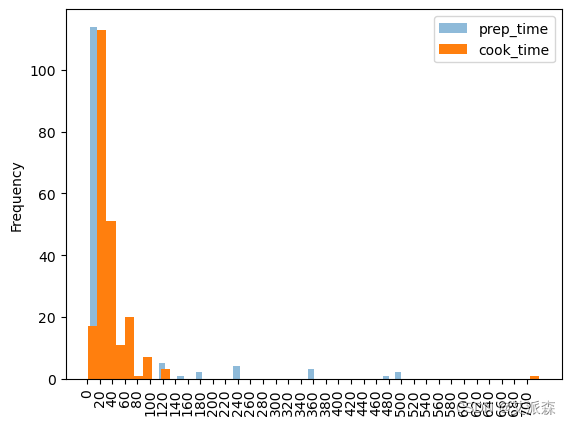
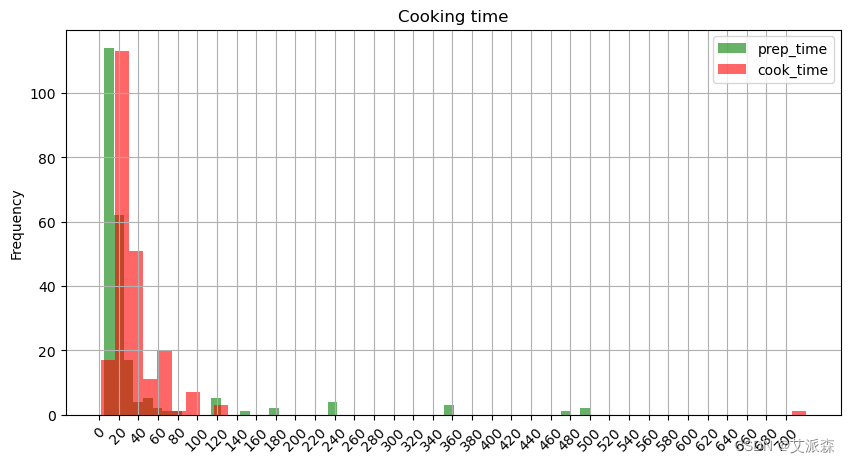
绘制多个直方图¶ 现在我们把准备时间也加进去。为了添加这个直方图,我们将把它作为一个单独的直方图绘制在同一个图中。你可以通过添加参数' alpha '来改变直方图的透明度,其值在0到1之间。1为默认值。
它们会共享y轴和x轴,所以它们会重叠。如果不把它们设置得透明一点,我们可能看不到第二张图下面的直方图。


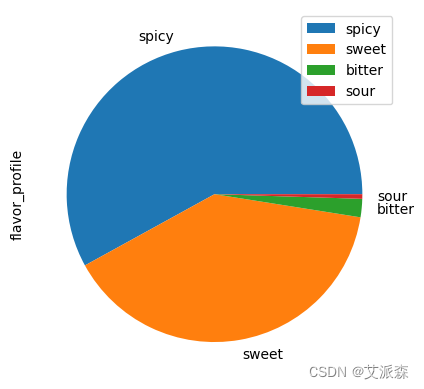
5.3饼图
当我们需要比较的分类值数量很少时,饼状图很有用。饼状图的可读性随着分类值数量的轻微增加而下降。

5.4 散点图
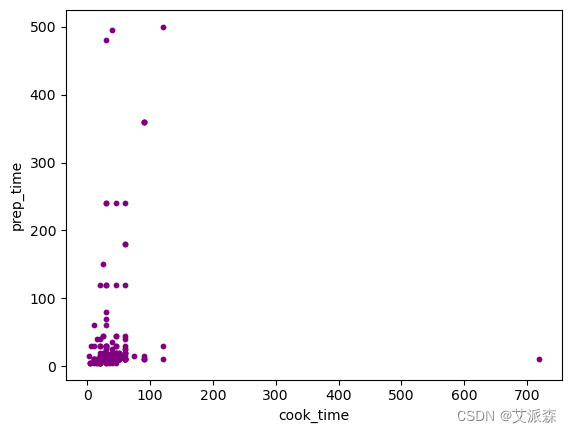
散点图是一种显示两个数值变量之间关系的数据可视化技术。散点图上的每个点代表一个单独的数据点。让我们看看准备时间和烹饪时间之间的关系。

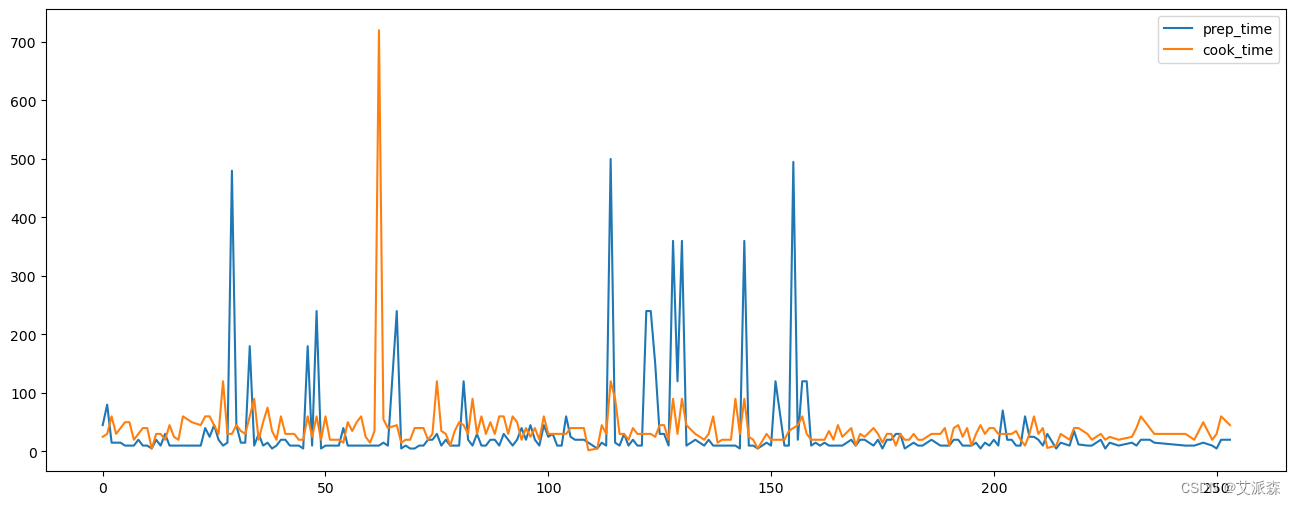
5.5 线图
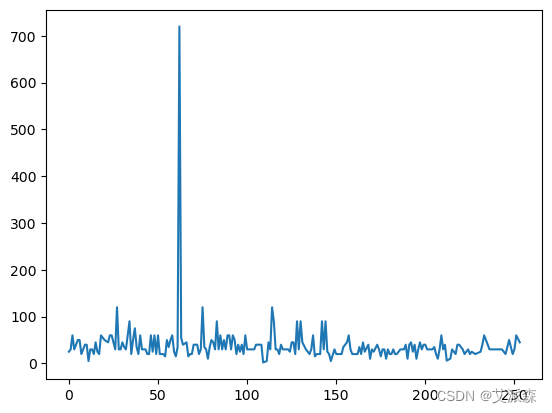
当我们想要看到一段时间内的数据变化时,线形图特别方便。我们想知道每个月新开了多少个账户。


5.6箱线图
boxplot()函数用于从给定的DataFrame列生成框图。箱形图是通过四分位数描绘数值数据组的视觉表示。箱线图也用于检测数据集中的离群值。
箱线图是通过计算数据集的四分位数来创建的,它根据数据集的分布将数字范围分成四部分。
为了更好地理解四分位数,让我们逐一分析:
中位数(Q2):分布中间的值
下四分位数(Q1):范围中位数和最低值之间的中点(25%的分数低于下四分位数值(也称为第一个四分位数))
上四分位数(Q3):范围中位数和最大值之间的中点(75%的分数低于上四分位数值(也称为第三四分位数))。因此,25%的数据高于此值。
下边界:分布中的最低值
高边界:分布中的最高值
您可以在下面的箱线图上看到这些值。



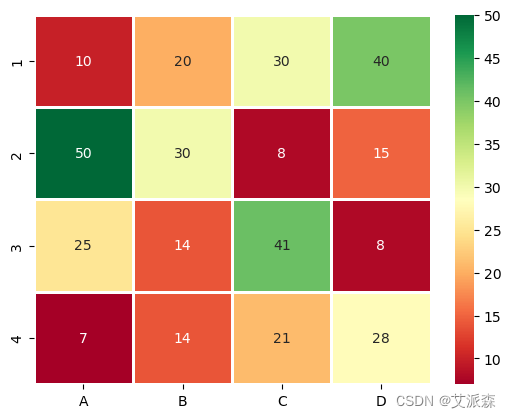
5.7热图
热图是一种矩阵形式的二维图形,它以单元格的形式将数值数据可视化。热图的每个单元格都有颜色,颜色的深浅表示值与数据框的某种关系。




源代码
import pandas as pd
menu = pd.read_csv('indian_food.csv')
menu.head()
menu.shape
menu.info()
menu.describe()
menu.describe(include='O')
menu.isnull().sum()
menu.duplicated().sum()
menu.dropna(inplace=True)
menu.isnull().sum()
为了只提取一些选定的列,我们可以通过方括号将数据集子集并列出我们想要关注的列名:
recipes = menu[['name', 'ingredients']]
print(recipes)
1. 条形图
经典的条形图很容易阅读,也是一个很好的起点——让我们想象一下烹饪每道菜需要多长时间。
Pandas依赖于Matplotlib引擎来显示生成的图。因此,我们必须导入Matplotlib的PyPlot模块,以便在生成图形后调用plt.show()。
首先,让我们导入数据。在我们的数据集中有很多盘子——确切地说是255个。在保持可读性的情况下,这并不适合一个数字。我们将使用head()方法提取前10道菜,并提取与我们的图相关的变量。也就是说,我们希望将每个菜肴的名称和cook_time提取到一个名为name_and_time的新DataFrame中,并将其截断为前10个菜肴:
# 导入matplotlib库进行可视化
import matplotlib.pyplot as plt
name_and_time = menu[['name', 'cook_time']].head(10)
我们将使用bar()方法来绘制数据:bar(x=None, y=None, **kwargs)
x和y参数对应于x和y轴,kwargs对应于datafframe .plot()中记录的其他关键字参数。可以传递许多附加参数来进一步自定义绘图,例如用于标签旋转的rot,用于添加图例的legend,样式等……
这些参数中的许多都有默认值,其中大多数都是关闭的。由于rot参数默认为90,因此我们的标签将旋转90度。让我们在构建情节时将其改为30:
name_and_time.plot.bar(x='name',y='cook_time', rot=30)
plt.show()
与其他菜肴相比,Gajak ka halwa需要更多的烹饪时间
在Pandas的条形图的x轴上绘制多列
通常,我们可能希望比较条形图中的两个变量,例如cook_time和prep_time。这些都是对应于每道菜的变量,可以直接比较。让我们改变name_and_time DataFrame,使其也包括prep_time:
name_and_time = menu[['name', 'prep_time', 'cook_time']].head(10)
name_and_time.plot.bar(x='name', y=['prep_time', 'cook_time'], rot=30)
plt.show()
似乎煮得快的食物需要更多的准备时间,反之亦然。不过,这确实来自一个相当有限的数据子集,对于其他子集来说,这个假设可能是错误的。
堆叠柱形
让我们来看看哪道菜做起来耗时最长。因为我们想把准备时间和烹饪时间都考虑进去,所以我们会把它们叠在一起。
为此,我们将stacked参数设置为True:
name_and_time.plot.bar(x='name', stacked=True)
plt.show()
现在,考虑到准备时间和烹饪时间,我们可以很容易地看到哪些菜需要最长的准备时间。
在Pandas中自定义条形图¶
如果我们想让图形看起来更好一点,我们可以向bar()方法传递一些额外的参数,例如:
color:为每个DataFrame的属性定义颜色。它可以是一个字符串,如'orange', rgb或rgb代码,如#faa005。
title:表示情节标题的字符串或列表。
grid:一个布尔值,指示网格线是否可见。
figsize:以英寸为单位表示图形大小的元组。
legend:布尔值,指示是否显示图例。
如果我们想要一个水平条形图,我们可以使用bar()方法,它接受相同的参数。例如,让我们绘制一个橙色和绿色的水平条形图,标题为“Dishes”,有一个5 × 6英寸的网格,还有一个图例:
name_and_time.plot.barh(x='name',color =['orange', 'green'], title = "Dishes", grid = True, figsize=(5,6), legend = True)
plt.show()
2. 直方图¶
直方图对于显示数据分布很有用。它的外观与条形图相似,只是它是连续的。
直方图中的塔状或条状被称为箱状。每个bin的高度显示了该数据中有多少值落在该范围内。
每个bin的宽度= (data的最大值- data的最小值)/ bin的总数
在直方图中创建的bin数量的默认值是10。但是,我们可以使用matplotlib.pyplot.hist()中的参数bins来改变箱子的大小。
方法1:我们可以在bin中传递一个整数,说明要在直方图中创建多少bin /tower,然后相应地更改每个bin的宽度。
例1:
import matplotlib.pyplot as plt
height = [189, 185, 195, 149, 189, 147, 154,
174, 169, 195, 159, 192, 155, 191,
153, 157, 140, 144, 172, 157, 181,
182, 166, 167]
plt.hist(height, edgecolor="red", bins=5)
plt.show()
这里,bin = 5,即要创建的bin数量为5。将bins设置为整数将创建大小或宽度相等的bins。当bin大小改变,那么bin宽度将相应地改变为:
宽度= (195 - 140)/ 5 = 11
values = [87, 53, 66, 61, 67, 68, 62,
110, 104, 61, 111, 123, 117,
119, 116, 104, 92, 111, 90,
103, 81, 80, 101, 51, 79, 107,
110, 129, 145, 139, 110]
plt.hist(values, bins=7, edgecolor="yellow", color="green")
plt.show()
宽度= (145 - 51)/ 7 = 13.4
方法2:我们也可以在参数bin中传递一个int或float序列,其中序列的元素是bin的边/边界。在此方法中,每个容器的宽度可能不同。
假设将一个序列[1,2,3,4,5]分配给箱子,那么制造的箱子数量将是4,即第一个箱子将是[1,2)(包括1,但不包括2)第二个箱子将是[2,3)(包括2,但不包括3)第三个箱子将是[3,4)(包括3,但不包括4)。然而,在最后一个箱子[4,5]中,4和5都包括在内。
因此,所有的箱子都是半开的[a, b),但最后一个箱子是关闭的[a, b]。对于这种情况,每个容器的宽度是相等的。
如果分配给bin的序列中每个元素之间的差异不相等,则每个bin的宽度不同,因此bin的宽度取决于序列。
# Example 1 : Equal bin width
import matplotlib.pyplot as plt
marks = [1, 2, 3, 2, 1, 2, 3, 2,
1, 4, 5, 4, 3, 2, 5, 4,
5, 4, 5, 3, 2, 1, 5]
plt.hist(marks, bins=[1, 2, 3, 4, 5], edgecolor="black")
plt.show()
# Example 2 : Unequal bin width
import matplotlib.pyplot as plt
data = [189, 185, 195, 149, 189, 147,
154, 174, 169, 195, 159, 192,
155, 191, 153, 157, 140, 144,
172, 157, 181, 182, 166, 167]
plt.hist(data, bins=[140, 150, 160, 175, 185, 200],
edgecolor="yellow", color="grey")
plt.show()
方法3:为了在bins参数中传递序列,我们也可以对等分布的bins使用range函数。在range()中,起始点是数据的最小值,终点是数据的最大值+提到的bin宽度,步长是bin宽度。
由于步长在range()中固定,我们在直方图中得到大小相等的箱子。
绘制多个直方图¶
现在我们把准备时间也加进去。为了添加这个直方图,我们将把它作为一个单独的直方图绘制在同一个图中。你可以通过添加参数' alpha '来改变直方图的透明度,其值在0到1之间。1为默认值。
它们会共享y轴和x轴,所以它们会重叠。如果不把它们设置得透明一点,我们可能看不到第二张图下面的直方图:
import numpy as np
menu = menu[(menu.cook_time!=-1) & (menu.prep_time!=-1)]
# Extracting relevant data
cook_time = menu['cook_time']
prep_time = menu['prep_time']
# Alpha indicates the opacity from 0..1
prep_time.plot.hist(alpha = 0.5 , bins = 50)
cook_time.plot.hist(alpha = 1, bins = 50)
plt.xticks(np.arange(0, cook_time.max(), 20))
plt.xticks(rotation = 90)
plt.legend()
plt.show()
# customizing
prep_time.plot.hist(alpha = 0.6 , color = 'green', title = 'Cooking time', grid = True, bins = 50)
cook_time.plot.hist(alpha = 0.6, color = 'red', figsize = (10,5), grid = True, bins = 50)
plt.xticks(np.arange(0, cook_time.max(), 20))
plt.xticks(rotation = 45)
plt.legend()
plt.show()
3. 饼图¶
当我们需要比较的分类值数量很少时,饼状图很有用。饼状图的可读性随着分类值数量的轻微增加而下降。
# 绘制出风味分布图
flavors = menu[menu.flavor_profile != '-1']
flavors['flavor_profile'].value_counts().plot.pie()
plt.legend()
plt.show()
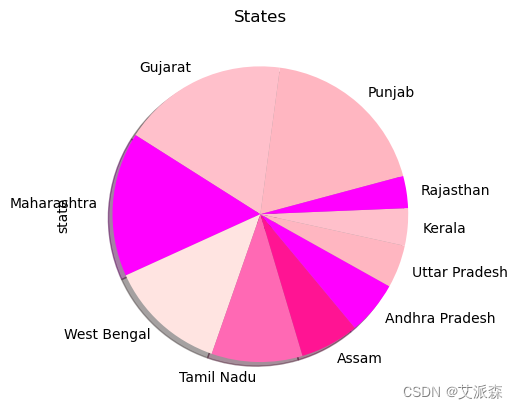
states = (menu[menu.state != '-1'])['state'].value_counts().head(10)
colors = ['lightpink', 'pink', 'fuchsia', 'mistyrose', 'hotpink', 'deeppink', 'magenta']
states.plot.pie(colors = colors, shadow = True, startangle = 15, title = "States")
plt.show()
4. 散点图¶
散点图是一种显示两个数值变量之间关系的数据可视化技术。散点图上的每个点代表一个单独的数据点。
让我们看看准备时间和烹饪时间之间的关系
data = menu[(menu.cook_time!=-1) & (menu.prep_time!=-1)]
data.plot.scatter(x='cook_time', y='prep_time', s = 10, c='purple')
plt.show()
5. 线图¶当我们想要看到一段时间内的数据变化时,线形图特别方便。我们想知道每个月新开了多少个账户
data['cook_time'].plot()
# 如果我们将整个数据帧传递给绘图函数,那么我们将得到所有数值特征的线形图
menu.plot(figsize=(16,6))
6. 箱线图¶
boxplot()函数用于从给定的DataFrame列生成框图。箱形图是通过四分位数描绘数值数据组的视觉表示。箱线图也用于检测数据集中的离群值。
箱线图是通过计算数据集的四分位数来创建的,它根据数据集的分布将数字范围分成四部分。
为了更好地理解四分位数,让我们逐一分析:
中位数(Q2):分布中间的值
下四分位数(Q1):范围中位数和最低值之间的中点(25%的分数低于下四分位数值(也称为第一个四分位数))
上四分位数(Q3):范围中位数和最大值之间的中点(75%的分数低于上四分位数值(也称为第三四分位数))。因此,25%的数据高于此值。
下边界:分布中的最低值
高边界:分布中的最高值
您可以在下面的箱线图上看到这些值。
箱形图很有用,因为它们显示了数据集中的异常值。IQR表示数据中间50%的范围IQR(Inter Quartile range) = Q3-Q1
异常值是指在数值上与其他数据相距甚远的观测值。当查看箱形图时,异常值被定义为位于箱形图须外的数据点。异常值是低于Q1-1.5(IQR)或高于Q3+1.5(IQR)的数据点。
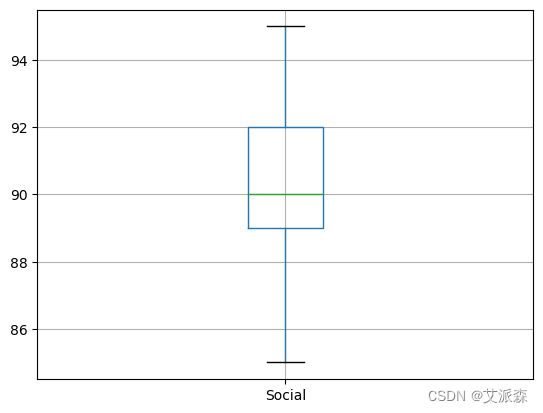
# example
import pandas as pd
df = pd.DataFrame([['Abhishek',75,80,90], ['Anurag',80,90,95],['Bavya',80,82,85],['Bavana',95,92,92],['Chetan',85,90,89]], columns=['Name','Maths','Science','Social'])
boxplot=df.boxplot(column=['Social'])
print(df['Social'].quantile([0.25,0.5,0.75]))
print(boxplot)
print(df['Social'].min(),df['Social'].max())
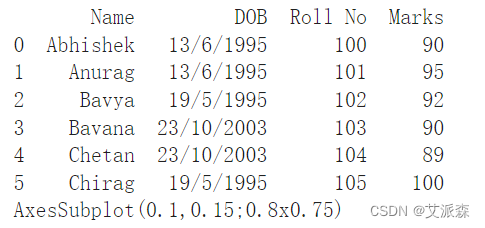
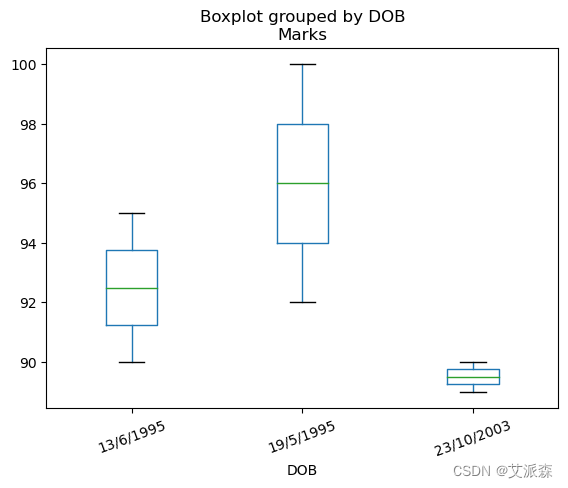
# 示例2:通过分组来自列值的数据,使用DataFrame.boxplot()方法创建boxplot
df = pd.DataFrame([['Abhishek','13/6/1995',100,90], ['Anurag','13/6/1995',101,95],['Bavya','19/5/1995',102,92],['Bavana','23/10/2003',103,90],['Chetan','23/10/2003',104,89],['Chirag','19/5/1995',105,100]], columns=['Name','DOB','Roll No','Marks'])
print(df)
boxplot=df.boxplot(column=['Marks'],by='DOB',grid=False, rot=20, fontsize=10)
print(boxplot)
7. 热图¶
热图是一种矩阵形式的二维图形,它以单元格的形式将数值数据可视化。热图的每个单元格都有颜色,颜色的深浅表示值与数据框的某种关系
# defining index for the dataframe
import seaborn as sns
%matplotlib inline
idx = ['1', '2', '3', '4']
cols = list('ABCD')
# entering values in the index and columns and converting them into a panda dataframe
df = pd.DataFrame([[10, 20, 30, 40], [50, 30, 8, 15],
[25, 14, 41, 8], [7, 14, 21, 28]],
columns = cols, index = idx)
print(df)
sns.heatmap(df, cmap ='RdYlGn', linewidths = 0.80, annot = True)
plt.show()
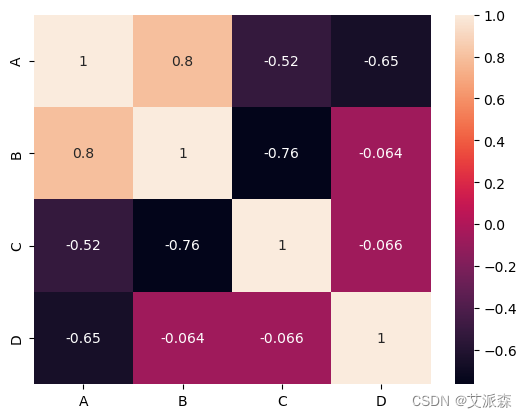
# 使用热图的相关矩阵
corr = df.corr()
sns.heatmap(corr, annot = True)
plt.show()
资料获取,更多粉丝福利,关注下方公众号获取